eval-gemini-2.5-pro-multimed-hard-20260408-1933
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/Trelis/eval-gemini-2.5-pro-multimed-hard-20260408-1933
下载链接
链接失效反馈官方服务:
资源简介:
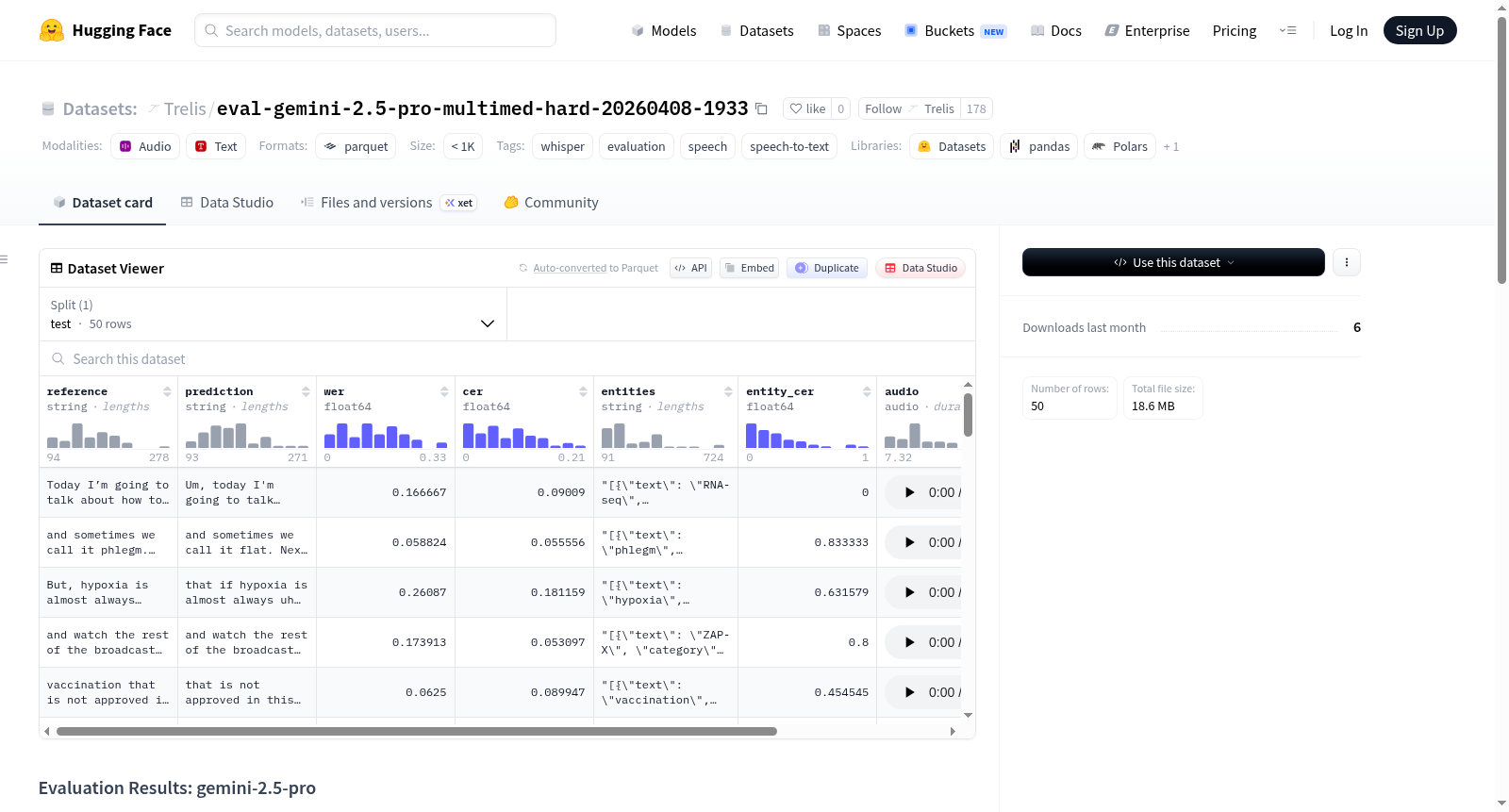
该数据集包含 Whisper 模型在 gemini-2.5-pro 上的评估结果。评估使用的数据集为 Trelis/multimed-hard,模型为 google/gemini-2.5-pro。数据集提供了详细的评估指标,包括词错误率(WER)和字符错误率(CER)。数据列包括音频样本(如果源数据集提供)、参考转录文本、模型预测文本、每个样本的 WER 和 CER,以及实体注释和每个样本的实体 CER(如果没有实体则为 -1.0)。此外,数据集还提供了按类别(如解剖学、生物标志物、条件、药物、组织和程序)划分的实体 CER 详细统计。整体实体 CER 为 16.70%。
This dataset contains the evaluation results of the Whisper model on google/gemini-2.5-pro. The evaluation was conducted using the Trelis/multimed-hard dataset, with the model being google/gemini-2.5-pro. The dataset provides detailed evaluation metrics, including Word Error Rate (WER) and Character Error Rate (CER). The data columns include audio samples (if provided by the source dataset), reference transcriptions, model predictions, WER and CER for each sample, entity annotations, and entity CER for each sample (set to -1.0 if no entities are present). In addition, the dataset also provides detailed statistics of entity CER categorized by classes such as anatomy, biomarkers, conditions, drugs, tissues and procedures. The overall entity CER is 16.70%.
提供机构:
Trelis创建时间:
2026-04-09
搜集汇总
数据集介绍
构建方式
在语音识别技术评估领域,eval-gemini-2.5-pro-multimed-hard-20260408-1933数据集的构建遵循了严谨的基准测试范式。该数据集并非从头创建,而是基于现有的Trelis/multimed-hard评估数据集,专门用于对Google的Gemini-2.5-Pro模型进行语音转文本性能的量化分析。构建过程的核心是将源数据集中的音频样本输入目标模型,生成预测文本,随后通过自动化脚本将预测结果与人工标注的真实文本进行逐项比对,计算得出词错误率和字错误率等关键指标。整个流程确保了评估结果的客观性与可复现性,为模型性能提供了标准化的度量。
使用方法
对于研究人员而言,该数据集可直接用于模型性能的横向对比与深度分析。使用者可以加载数据集,通过审查`reference`(参考文本)、`prediction`(预测文本)及对应的`wer`(词错误率)、`cer`(字错误率)字段,进行错误案例的定性分析。更重要的是,利用`entities`(实体标注)和`entity_cer`(实体字符错误率)字段,可以开展针对医疗命名实体识别准确率的专项评估。该数据集可作为基准,用于衡量新模型或改进算法在Multimed-Hard这一挑战性测试集上是否超越了Gemini-2.5-Pro所设立的性能标杆。
背景与挑战
背景概述
自动语音识别技术作为人机交互的核心环节,其评估体系的构建对于推动模型性能的精准度量至关重要。eval-gemini-2.5-pro-multimed-hard-20260408-1933数据集由Trelis机构于2024年创建,旨在对谷歌Gemini 2.5 Pro等先进模型在复杂多模态医学语音场景下的转录能力进行系统性评估。该数据集依托于源数据集Trelis/multimed-hard,聚焦于医学领域专业术语的识别,核心研究问题在于量化模型在包含解剖学、生物标志物、病症等专业实体词汇的语音材料上的识别准确率。其评估结果通过词错误率和字符错误率等指标,为语音识别模型在垂直领域的性能优化提供了关键基准,显著影响了医学人工智能与语音技术交叉领域的研究方向。
当前挑战
该数据集所针对的领域挑战在于,医学语音识别需处理大量专业术语、缩写及复杂实体名称,这些词汇在通用语音数据中罕见,导致模型在专业领域泛化能力不足,实体识别错误率显著高于通用词汇。在构建过程中,挑战主要源于高质量医学语音数据的稀缺性与标注复杂性。医学对话或讲座录音常涉及隐私与伦理问题,难以公开获取;同时,专业文本转录需要领域专家参与,以确保解剖结构、药物名称等实体标注的准确性,这大幅增加了数据标注的时间与经济成本。此外,评估框架需设计针对实体的细粒度错误率度量,以精准揭示模型在特定医学类别上的性能瓶颈。
常用场景
经典使用场景
在语音识别领域,评估数据集常被用于基准测试和模型性能比较。eval-gemini-2.5-pro-multimed-hard-20260408-1933数据集基于Trelis/multimed-hard构建,专注于医疗多媒体场景下的语音转文本任务。其经典使用场景在于为先进的大语言模型如Gemini-2.5-Pro提供细粒度的评估框架,通过计算词错误率和字符错误率等指标,系统衡量模型在复杂专业领域音频上的转录准确性。
解决学术问题
该数据集有效解决了语音识别研究中模型在专业领域泛化能力不足的学术问题。医疗对话通常包含大量医学术语、实体名称和复杂句式,传统通用语音模型在此类数据上表现受限。通过提供带有实体标注的医疗音频样本,该数据集支持研究者深入分析模型在特定实体类别上的错误模式,从而推动领域自适应、术语识别和鲁棒性建模等关键研究方向的发展。
实际应用
在实际应用中,该数据集直接服务于医疗人工智能系统的开发与优化。高精度的医疗语音转录是临床文档自动化、远程医疗问诊记录和医学教育工具的核心技术基础。通过评估模型在“解剖结构”、“生物标志物”、“疾病条件”等实体上的表现,能够指导开发更可靠的辅助诊断系统和患者信息管理系统,提升医疗服务的效率与准确性,并降低人工记录的错误风险。
数据集最近研究
最新研究方向
在语音识别领域,针对医学专业场景的模型性能评估正成为前沿焦点。该数据集基于Trelis/multimed-hard构建,专门用于测试Gemini-2.5-Pro等先进模型在复杂医学音频转录中的表现。研究重点已从通用语音识别转向特定领域实体识别精度,如解剖结构、生物标志物等专业术语的字符错误率分析。当前热点集中于利用细粒度实体分类误差数据优化模型在噪声环境或多语种医学对话中的鲁棒性,这直接关系到临床诊断辅助系统的可靠性提升与自动化医疗记录的安全应用。
以上内容由遇见数据集搜集并总结生成


