xudongwu/RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/xudongwu/RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
config_name: Q7B
features:
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: response
dtype: string
- name: reward_score
dtype: float64
- name: gpt_score
dtype: float64
splits:
- name: default
num_bytes: 1492042
num_examples: 256
download_size: 789126
dataset_size: 1492042
configs:
- config_name: Q7B
data_files:
- split: default
path: Q7B/default-*
---
提供机构:
xudongwu
搜集汇总
数据集介绍
构建方式
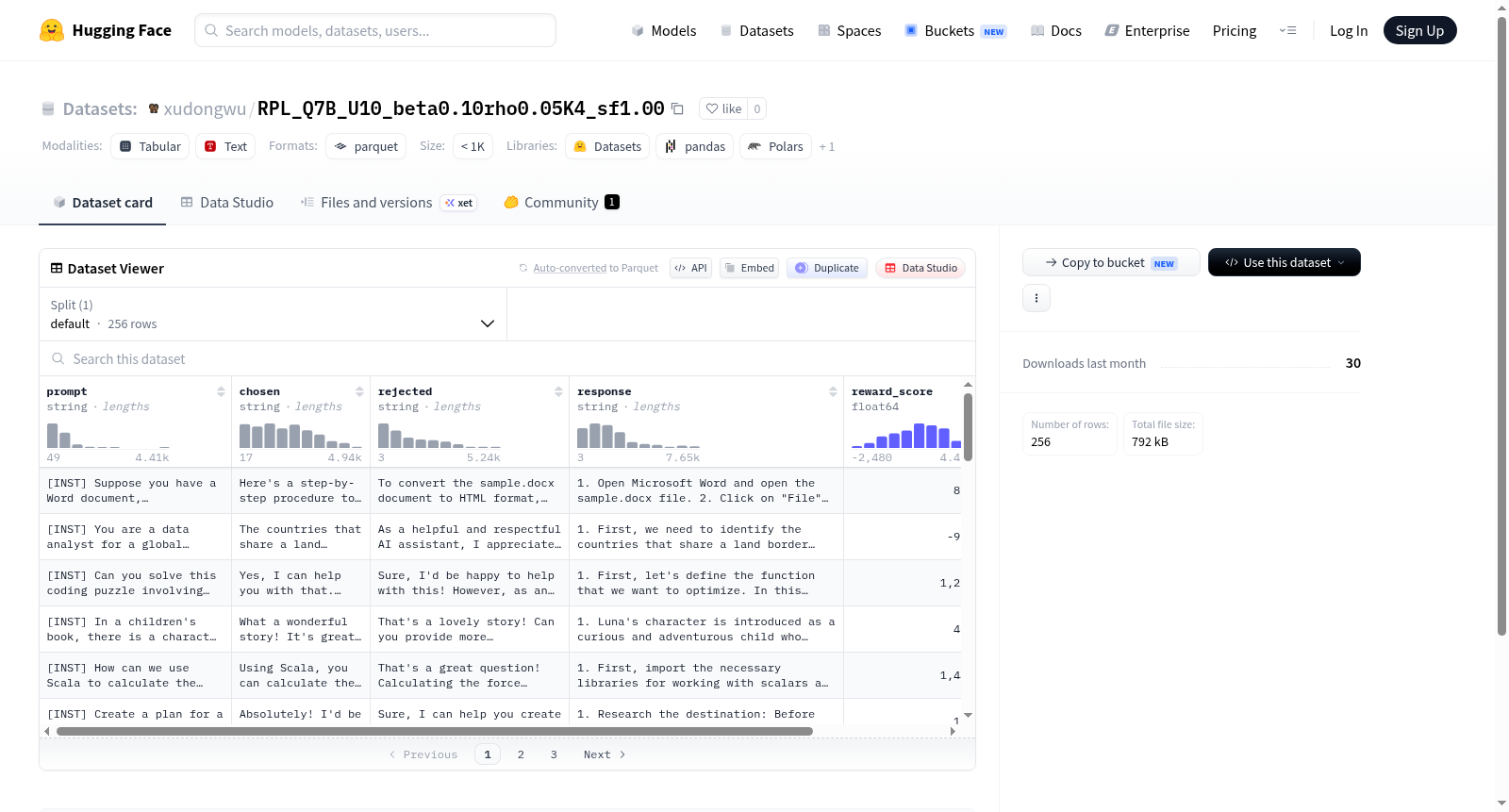
该数据集RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00是基于强化学习偏好优化(RPL)框架构建的偏好数据集,旨在为语言模型的对齐训练提供监督信号。数据集的名称中编码了关键超参数:beta=0.10和rho=0.05分别控制偏好优化的正则化强度与样本筛选比例,K=4表示每个prompt采样了4个候选响应,sf=1.00为奖励缩放因子。构建过程首先使用Qwen2.5-7B-Instruct模型(Q7B)生成大量候选响应,随后通过奖励模型进行评分,并依据RPL算法选取chosen(优选)和rejected(劣选)响应对,最终形成包含256条样本的紧凑数据集,每一条样本由原始prompt、优选响应、劣选响应、模型响应及对应的奖励得分和GPT评分组成。
特点
该数据集最显著的特点在于其高密度信噪比与结构化的质量度量体系。仅256条样本即可实现高效的对齐训练,得益于RPL算法中rho=0.05的严格筛选机制,仅保留最具区分度的偏好对。每一条样本均配备了双维度评分:reward_score来自训练好的奖励模型,提供与优化目标一致的连续反馈;gpt_score则利用GPT-4的评估能力,为chosen和rejected响应提供第三方人类偏好标定。此外,数据集保留了完整的响应文本,支持直接用于监督式微调或作为偏好优化的基线参考。其设计兼顾了实验的经济性与评估的全面性,特别适用于资源受限场景下的快速迭代验证。
使用方法
该数据集可直接加载至HuggingFace datasets库中,通过指定config_name为'Q7B'获取default分片数据。典型使用场景包括:作为DPO、PPO等偏好优化算法的训练数据,利用'prompt'、'chosen'、'rejected'字段构建偏好损失;或利用'reward_score'和'gpt_score'字段进行模型响应的质量排序与评估。在离线强化学习流程中,'response'字段可作为行为策略的初始数据,结合奖励分数进行重要性采样修正。由于数据集规模小巧(约1.5MB),尤其适合作为消融实验的基准集,或与更大规模数据集混合以注入特定偏好的先验知识。
背景与挑战
背景概述
在强化学习与人类反馈(RLHF)领域,奖励模型(Reward Model)的评估质量直接决定了策略优化的上限。RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00数据集由研究者于近期构建,旨在系统评估奖励模型在长文本生成任务中的区分能力与稳健性。该数据集围绕Q7B配置,包含256条提示-回答对,每条样本均附带人工设计的奖励分数与GPT-4评分。其命名中的beta、rho、K等参数,反映了实验中对偏好对齐算法中关键超参数的严格标定。数据集由单次分片(default split)构成,为奖励模型校准研究提供了标准化测试床。通过在可控生成环境下对奖励信号的异质性进行精细控制,该资源有望推动RLHF中奖励泛化与偏好一致性的研究进展。
当前挑战
当前该数据集面临的核心挑战在于:第一,奖励信号的多源冲突问题——人工奖励分数与GPT-4评分之间的分歧揭示了人类偏好与自动化评判间的固有偏差,需建立更稳健的分数融合机制;第二,样本稀疏性困境——仅256条数据难以覆盖长文本生成中多样化的失败模式,导致奖励模型对罕见但关键的风险行为(如隐蔽性偏见、事实性幻觉)感知不足;第三,超参数敏感性——数据集构建时采用的beta、rho等参数虽确保了实验可控性,却可能限制其在其他偏好分布下的泛化能力;第四,任务覆盖局限——当前配置仅针对单一模型规模(Q7B),未能体现奖励信号随模型能力缩放时的非线性变化规律。
常用场景
经典使用场景
RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00数据集在强化学习与偏好对齐领域扮演着关键角色,特别是用于训练语言模型以生成更符合人类偏好的文本。其结构包含prompt、chosen、rejected和response等字段,以及reward_score和gpt_score评分,使其成为经典的偏好学习与奖励建模基准。研究人员通常利用该数据集进行直接偏好优化(DPO)、近端策略优化(PPO)等算法的实验,通过对比chosen与rejected回复来微调模型,从而提升对特定指令或对话场景的响应质量。
衍生相关工作
基于RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00数据集,学术界衍生出一系列重要工作,包括探索不同偏好信号(如奖励模型与GPT评分)融合策略的研究,以及针对低资源场景的偏好学习成本压缩方案。部分工作致力于将数据集中的偏好排序规则迁移至其他语言或领域,推动了多语言对齐模型的进展。此外,该数据集催生了对比优化算法中关于超参数敏感性的系统性分析,如beta与rho系数对收敛行为的影响,为后续设计更鲁棒的对齐框架奠定了实证基础。
数据集最近研究
最新研究方向
该数据集聚焦于大语言模型(LLM)在偏好对齐与强化学习微调中的前沿探索。RPL_Q7B_U10_beta0.10rho0.05K4_sf1.00这一命名暗含了严格的超参数配置,如K=4的采样策略与beta=0.10的KL散度约束权重,体现了对DPO(直接偏好优化)及其变体的精细化调优实验。当前相关研究热点集中于利用人类反馈信号(如reward_score与gpt_score)构建更高效的对齐机制,以提升模型生成内容的可接受性与安全性。数据集仅含256条精炼示例,暗示了小样本条件下的对齐效率研究,这对降低微调成本、推动LLM在资源受限场景中的部署具有显著意义。其设计理念响应了领域内对透明化、可复现偏好数据集的迫切需求,为理解奖励模型与策略网络间的动态博弈提供了宝贵的中型基准。
以上内容由遇见数据集搜集并总结生成


