zpn/clintox
收藏Hugging Face2022-12-09 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/zpn/clintox
下载链接
链接失效反馈官方服务:
资源简介:
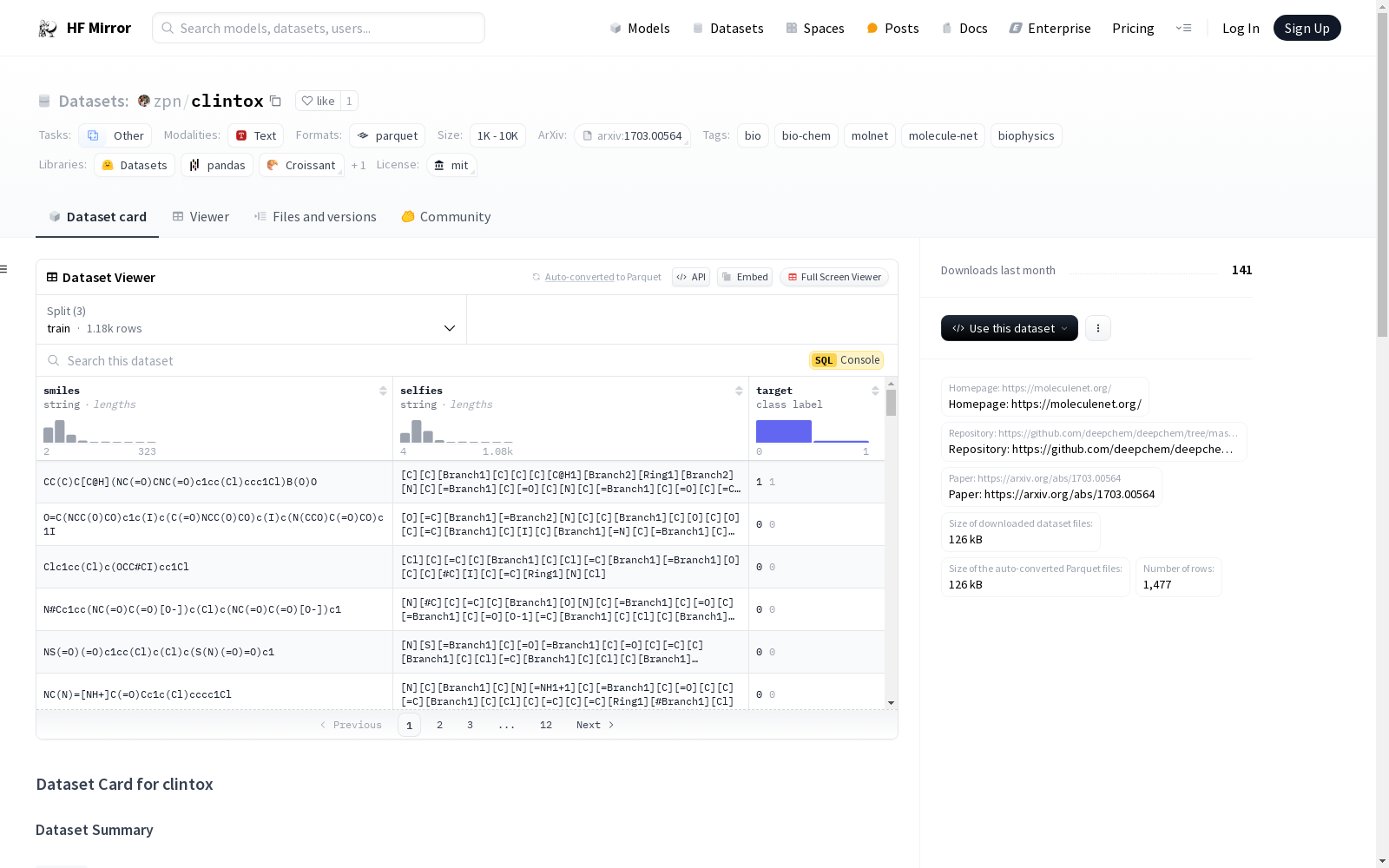
clintox数据集是MoleculeNet中的一个数据集,包含FDA批准的药物和因毒性原因未能通过临床试验的药物的定性数据。该数据集使用CT_TOX任务。每个数据实例包含分子的SMILES和SELFIES表示,以及临床试验毒性(或无毒)的目标值。数据集按80/10/10的比例分为训练集、验证集和测试集,使用scaffold分割方法。数据最初由斯坦福大学的Pande Group生成,并以MIT许可证发布。
The ClinTox dataset is a dataset within MoleculeNet, containing qualitative data on FDA-approved drugs and drugs that failed clinical trials due to toxicity. It utilizes the CT_TOX task. Each data instance includes the SMILES and SELFIES representations of the molecule, alongside the target value for clinical trial toxicity (or non-toxicity). The dataset is split into training, validation and test sets with an 80/10/10 ratio via the scaffold splitting method. The data was originally generated by the Pande Group at Stanford University and released under the MIT License.
提供机构:
zpn
原始信息汇总
数据集概述
数据集名称
- 名称: clintox
数据集属性
- 语言: 单语种(monolingual)
- 许可证: MIT
- 大小: 1K<n<10K
- 标签:
- bio
- bio-chem
- molnet
- molecule-net
- biophysics
- 任务类别: other
数据集描述
- 概述:
clintox是 MoleculeNet 中的一个数据集,包含FDA批准的药物和因毒性原因未通过临床试验的药物的定性数据。此数据集使用CT_TOX任务。
数据集结构
- 数据字段:
- 数据分割: 采用80/10/10的训练/验证/测试分割,使用scaffold split方法。
数据集创建
- 源数据: 数据最初由斯坦福大学的Pande Group生成。
- 许可证: 原始发布为MIT许可证。
引用信息
@misc{https://doi.org/10.48550/arxiv.1703.00564, doi = {10.48550/ARXIV.1703.00564}, url = {https://arxiv.org/abs/1703.00564}, author = {Wu, Zhenqin and Ramsundar, Bharath and Feinberg, Evan N. and Gomes, Joseph and Geniesse, Caleb and Pappu, Aneesh S. and Leswing, Karl and Pande, Vijay}, keywords = {Machine Learning (cs.LG), Chemical Physics (physics.chem-ph), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences, FOS: Physical sciences, FOS: Physical sciences}, title = {MoleculeNet: A Benchmark for Molecular Machine Learning}, publisher = {arXiv}, year = {2017}, copyright = {arXiv.org perpetual, non-exclusive license} }
搜集汇总
数据集介绍
构建方式
clintox数据集由斯坦福大学的Pande实验室生成,专门用于评估药物在临床试验中的毒性。该数据集包含了经过FDA批准的药物以及因毒性原因未能通过临床试验的药物。数据集通过SMILES和SELFIES两种分子表示方法进行编码,并标注了临床试验中的毒性或无毒性标签。数据集的构建采用了80/10/10的训练/验证/测试集划分方式,基于分子骨架进行分割,确保了数据集的多样性和代表性。
特点
clintox数据集的主要特点在于其专注于药物的临床毒性评估,涵盖了FDA批准的药物和临床试验失败的药物,提供了丰富的毒性数据。数据集采用了SMILES和SELFIES两种分子表示方法,增强了数据的可解释性和通用性。此外,数据集的划分基于分子骨架,确保了不同数据集之间的独立性,从而提高了模型的泛化能力。
使用方法
clintox数据集适用于药物毒性预测任务,研究者可以通过分析SMILES或SELFIES表示的分子结构,结合标注的毒性标签,训练机器学习模型以预测新药物的临床毒性。数据集的80/10/10划分方式为模型训练、验证和测试提供了明确的数据集划分,便于进行系统的模型评估。使用时,研究者应确保遵循MIT许可协议,并参考相关文献进行适当的引用。
背景与挑战
背景概述
clintox数据集是MoleculeNet基准测试的一部分,由斯坦福大学的Pande实验室于2017年创建。该数据集专注于药物的临床试验毒性评估,涵盖了美国食品药品监督管理局(FDA)批准的药物以及因毒性原因未能通过临床试验的药物。通过提供药物的SMILES和SELFIES表示及其临床试验毒性标签,clintox数据集为分子机器学习领域提供了一个重要的基准,推动了药物毒性预测模型的研究与发展。
当前挑战
clintox数据集在构建过程中面临的主要挑战包括数据的标准化和表示问题。由于药物分子结构的复杂性,部分分子无法转换为SELFIES格式,这为数据处理和模型训练带来了技术难题。此外,临床试验毒性数据的获取和标注也具有一定的难度,尤其是在确保数据准确性和代表性方面。这些挑战不仅影响了数据集的质量,也对基于该数据集的模型性能提出了更高的要求。
常用场景
经典使用场景
在药物研发领域,`clintox`数据集被广泛用于评估药物的临床毒性。通过分析药物的SMILES和SELFIES表示,研究人员可以构建模型来预测药物在临床试验中可能出现的毒性问题。这一经典应用场景不仅加速了药物筛选过程,还提高了药物安全性评估的准确性。
解决学术问题
`clintox`数据集解决了药物研发中长期存在的毒性预测难题。通过提供经过验证的毒性数据,该数据集为学术界提供了一个标准化的基准,用于开发和评估毒性预测模型。这不仅推动了分子机器学习领域的发展,还为药物安全性研究提供了重要的数据支持。
衍生相关工作
基于`clintox`数据集,许多相关研究工作得以展开。例如,研究人员开发了多种毒性预测模型,并将其应用于不同类型的药物数据。此外,该数据集还启发了其他分子数据集的构建,推动了MoleculeNet平台的发展,进一步促进了分子机器学习领域的研究。
以上内容由遇见数据集搜集并总结生成


