dataset-A-routing
收藏Hugging Face2026-05-16 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/massaindustries/dataset-A-routing
下载链接
链接失效反馈官方服务:
资源简介:
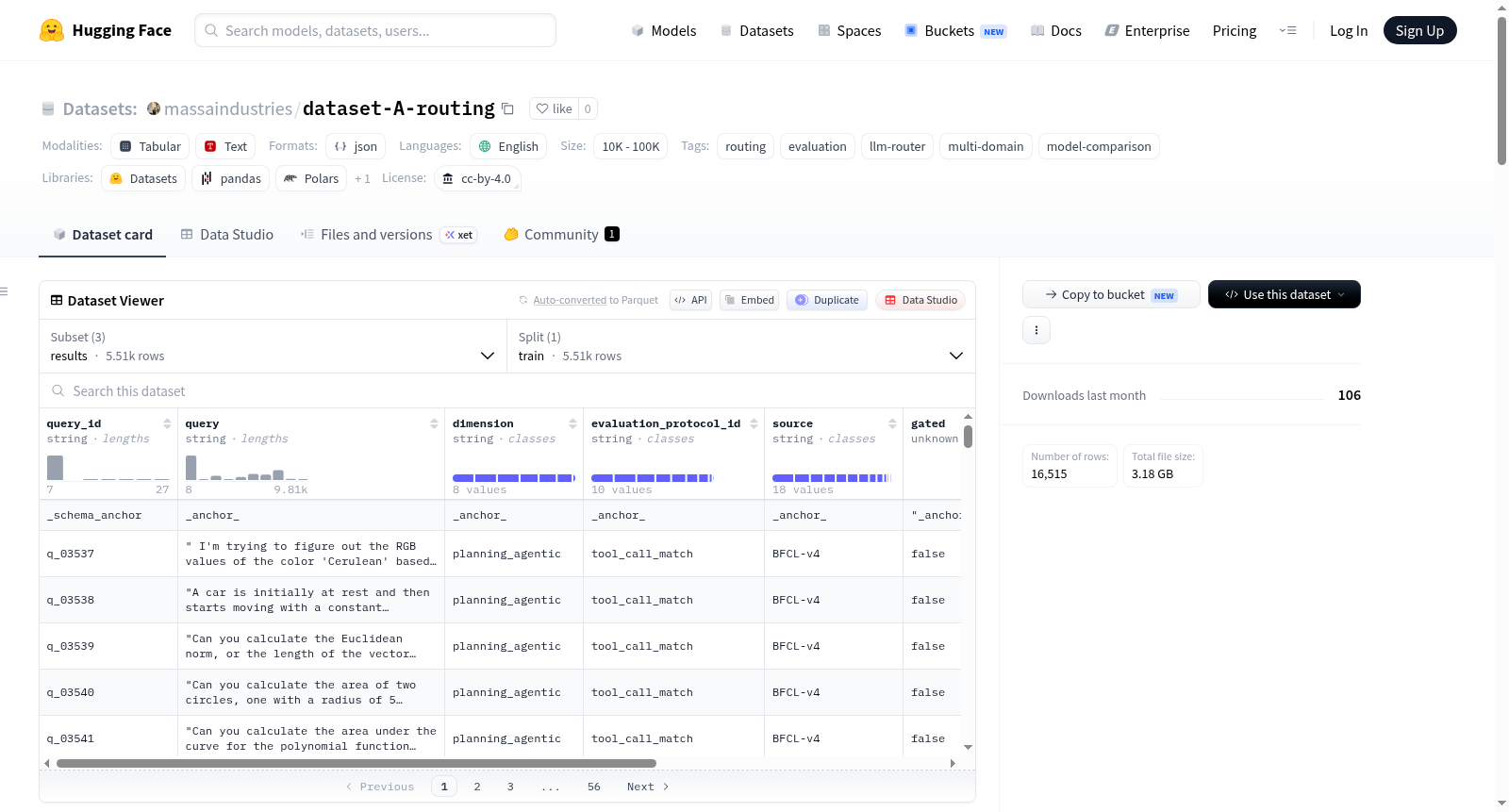
该数据集名为A - Routing (3 modelli, verdict-level),是一个用于评估大语言模型(LLM)路由系统的基准数据集。它专注于六个核心能力维度:规划与代理、数学推理、编程、指令遵循、世界知识和创造性合成。数据集包含5504个查询,每个查询均在三个预训练模型(qwen3.5-9b, deepseek-v4-flash, kimi2.6)上执行,并采用混合评估协议:对于数学、编程和指令遵循任务使用确定性评分器(如数学等价性检查、单元测试通过率、ifeval约束检查),对于规划与代理任务使用LLM评委面板(2-of-3多数表决),对于创造性合成和部分世界知识任务使用单LLM评委。数据集提供三种配置:1) results配置:提供核心的查询级判断结果,包含查询ID、查询文本(受限制的查询会被掩码)、能力维度、评估协议、数据来源以及三个模型各自的正确性布尔值(可能为空值表示弃权)。2) verbose配置:在results基础上,为每个模型额外提供原始响应、思维链、推理成本、延迟、令牌使用情况、完成原因、评分器元数据等详细信息。3) evals配置:仅包含提示和真实值,用于复现和重新运行评估测试。数据规模在1千到1万样本之间。该数据集旨在支持LLM路由策略的评估、模型能力比较以及多领域任务下的性能分析。数据集基于CC-BY-4.0许可证发布,但源自其他受限制数据集的查询文本仍遵循其原始许可证。
The dataset is named A - Routing (3 modelli, verdict-level) and is a benchmark dataset for evaluating large language model (LLM) routing systems. It focuses on six core competency dimensions: planning and agency, mathematical reasoning, programming, instruction following, world knowledge, and creative synthesis. The dataset contains 5,504 queries, each executed on three pre-trained models (qwen3.5-9b, deepseek-v4-flash, kimi2.6), and employs a hybrid evaluation protocol: deterministic scorers (e.g., mathematical equivalence checking, unit test pass rate, ifeval constraint checking) are used for math, programming, and instruction following tasks; an LLM judge panel (2-of-3 majority voting) is used for planning and agency tasks; and a single LLM judge is used for creative synthesis and some world knowledge tasks. The dataset offers three configurations: 1) results configuration: provides core query-level judgment results, including query ID, query text (masked for restricted queries), competency dimension, evaluation protocol, data source, and correctness boolean values for each of the three models (possibly empty to indicate abstention). 2) verbose configuration: builds on results by adding detailed information for each model, such as raw responses, chain-of-thought, inference cost, latency, token usage, completion reason, scorer metadata, etc. 3) evals configuration: contains only prompts and ground truths for reproducing and re-running evaluation tests. The dataset size ranges from 1,000 to 10,000 samples. It aims to support the evaluation of LLM routing strategies, model capability comparison, and performance analysis across multiple domains. The dataset is released under the CC-BY-4.0 license, but query texts derived from other restricted datasets still adhere to their original licenses.
创建时间:
2026-05-16
搜集汇总
数据集介绍
构建方式
dataset-A-routing是一个专为评估大语言模型路由系统而构建的高质量评测数据集。它从六个核心能力维度(规划与智能体、数学推理、代码生成、指令遵循、世界知识与创意合成)出发,精心抽取了5339条查询,并在三个主流模型(Qwen3.5-9b、DeepSeek-v4-flash、Kimi2.6)上以零温度参数执行确定性推理,确保结果可复现。对于数学、代码和指令遵循任务,采用确定性评判器(如数学等价性检查、单元测试、IFEval约束检验);而对规划与智能体这类主观性较强的任务,则采用2-of-3评委小组机制(由GPT-5.4-mini、Mistral-small-2603和GLM-5-turbo构成),创意合成与世界知识则分别通过单评委和混合方法裁定。
特点
该数据集最为突出的特点在于其多维度的覆盖与严格的评判体系。它横跨规划、推理、编码、指令遵循、世界知识与创意六大领域,每一领域均采用针对性评判协议,实现了从硬性规则到软性评价的全覆盖。数据以三个配置分支呈现:核心的results分支提供简洁的逐查询布尔型评判结果;verbose分支则保留了原始模型输出、思考链、成本、延迟及多评委详细评分等丰富元信息,为深入分析模型行为提供了完整素材;evals分支仅含提示与标准答案,便于研究人员独立复现测试。此外,数据集中约有1.4%的查询因评委弃权而标记为空值,体现了评判的审慎性。
使用方法
用户可通过HuggingFace Datasets库便捷加载指定配置的数据:加载results配置可直接获取每个查询下三个模型的正确性标记,用于快速计算准确率与胜率;加载verbose配置可获得完整响应与成本时间细节,适用于模型行为剖析与实际部署成本估算;加载evals配置则仅含输入与标准答案,适合从头执行推理并自行应用评判器以验证路由策略。需注意每个配置文件均包含一行标记为'_schema_anchor'的结构锚点,实际分析时需通过过滤移除。为保障数据来源纯净,该数据集采用CC-BY-4.0许可,但保留其原始数据集的各自授权条款。
背景与挑战
背景概述
大型语言模型(LLM)的迅猛发展催生了模型路由(LLM Routing)这一新兴研究范式,其核心在于根据查询特性动态选择最优模型,以平衡性能与成本。dataset-A-routing由产业界与学术界联合构建,于近期发布,旨在为LLM路由系统提供标准化的多维度评估基准。该数据集涵盖规划与智能体、数学推理、代码生成、指令遵循、世界知识与创意合成六大核心能力域,依托5504条精心设计的查询,对Qwen3.5-9B、DeepSeek-v4-Flash与Kimi2.6三款代表性模型进行了系统性评判。其影响力体现在引入确定性评判与LLM评判面板相结合的混合评估协议,为路由算法的公平比较奠定了方法论基础,已成为当前该领域事实上的评估标准。
当前挑战
该数据集面临的挑战主要源自领域问题与构建过程两个层面。在领域问题上,LLM路由需应对模型间能力分布的显著差异与查询语义的模糊性,现有精度约66%至84%的模型准确率表明路由决策远未达最优;单一评判协议难以涵盖所有能力维度,如创意合成依赖单模型评判,存在偏差风险。在构建过程中,约1.4%的评判避答(abstention)导致数据稀疏,且部分源自私有数据集(gated)的查询无法公开,限制了可复现性;跨领域评判标准(如数学确定性验证与知识开放性评判)的异构性增加了标签一致性维护的复杂度,对路由系统的鲁棒泛化构成了严峻考验。
常用场景
经典使用场景
在大型语言模型(LLM)推理系统的评估与优化领域中,数据集A-Routing(dataset-A-routing)作为一套精心构建的基准评测资源,被广泛用于路由策略的有效性验证。该数据集涵盖了规划智能体、数学推理、代码生成、指令遵循、世界知识与创意合成六大核心能力维度,共包含5504条查询样本,每条查询均经由qwen3.5-9b、deepseek-v4-flash和kimi2.6三个模型推理,并借助确定性评分器或LLM评审面板得出准确性判定。研究者通过分析不同模型在各维度上的胜率与准确率分布,能够系统评估路由系统在动态分配查询至最优模型时的表现,进而量化路由算法在提升整体响应质量与降低推理成本方面的贡献。这一经典用法不仅为路由机制的横向对比提供了标准化测试平台,更推动了多模型协同推理架构的实证研究。
实际应用
在工业级LLM服务平台中,dataset-A-routing为智能路由系统的部署与调优提供了直接支撑。实际应用中,该数据集可帮助运维团队为不同查询配置差异化模型池——例如将数学与代码类问题优先分配给擅长推理的模型,而将创意写作任务导向生成能力更强的模型,从而在保证输出质量的前提下显著降低计算开销与延迟。基于该数据集的评估结果,企业能够基于准确率、成本与响应速度等指标制定精细化的路由阈值与切换策略,构建动态负载均衡机制。此外,数据集提供的详细推理日志与元数据(包括响应内容、令牌消耗、延迟等)使开发者能够进行深入的根因分析与故障排查,提升系统的鲁棒性与可解释性。这种数据驱动的路由优化方法已在多云部署、边缘计算与实时交互场景中展现出巨大的实用价值。
衍生相关工作
基于dataset-A-routing的框架设计思路,学术界与工业界已衍生出多项具有影响力的相关工作。在路由策略层面,研究者利用该数据集中的多维评估结果提出了基于贝叶斯优化的自适应路由算法,以及融合查询嵌入相似度与模型历史表现的概率路由模型。这些工作进一步验证了在不同能力维度上实行差异化模型分配的有效性。在评估方法学方面,该数据集启发了关于LLM评审面板可靠性的大规模实证研究,尤其是2-of-3多数投票机制与单评审员方案的对比分析,催生了更为稳健的联合评审协议。此外,数据集中的确定性评分与LLM评审共存模式,为混合评估框架的设计提供了范例,推动了半自动化评测流水线的开发。这些衍生工作共同拓展了多模型协作的理论与应用边界,彰显了该数据集在LLM服务系统研究中的基础性地位。
以上内容由遇见数据集搜集并总结生成


