CG-AV-Counting
收藏arXiv2025-06-06 更新2025-06-07 收录
下载链接:
https://av-reasoner.github.io
下载链接
链接失效反馈官方服务:
资源简介:
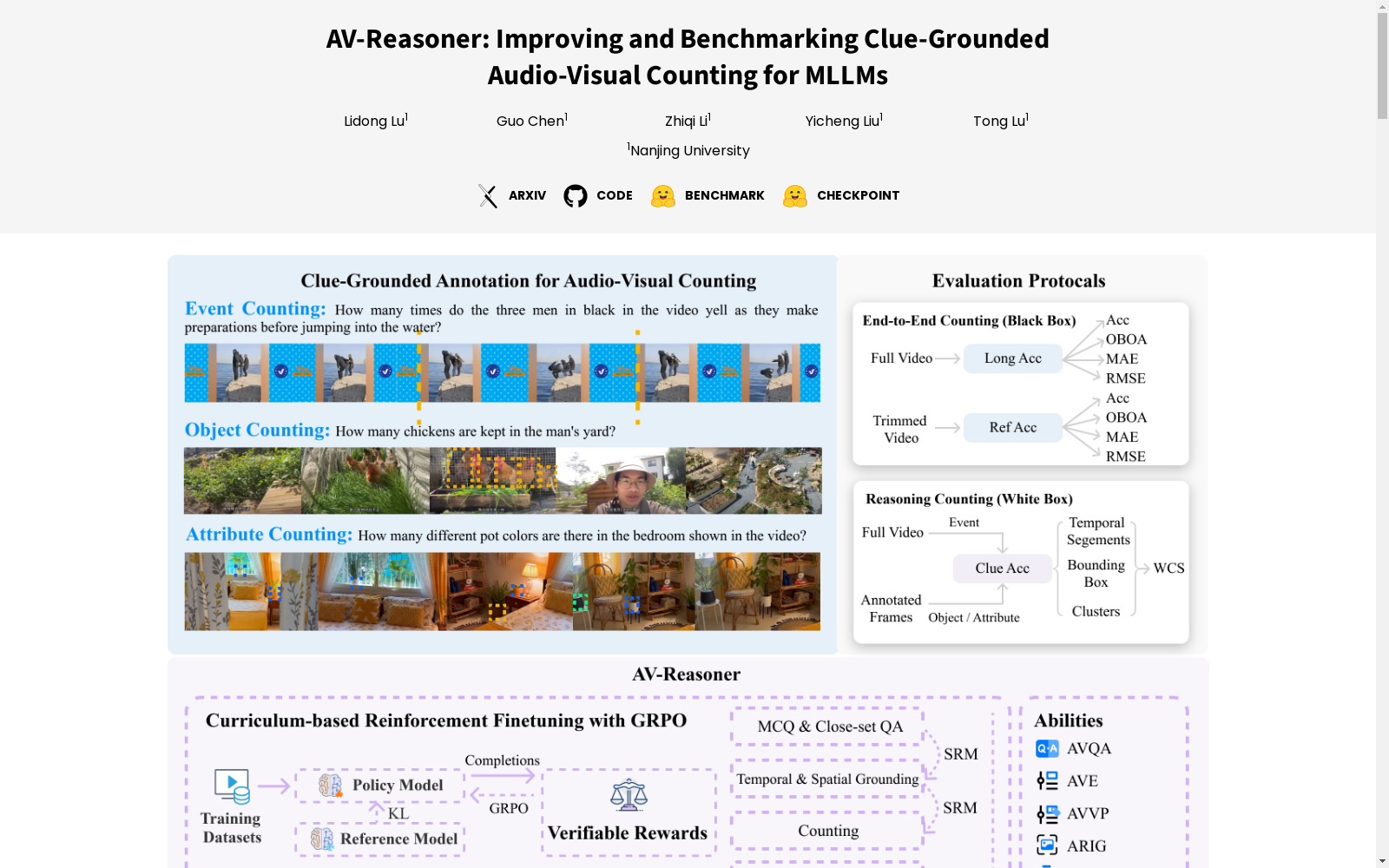
CG-AV-Counting是一个针对多模态大型语言模型(MLLMs)的长视频计数能力评估的基准数据集。该数据集由南京大学的研究团队创建,包含1,027个多模态问题,5,845个注解线索,涵盖497个长视频。数据集支持黑盒和白盒评估,用于全面测试端到端和基于推理的计数能力。CG-AV-Counting旨在解决现有计数基准在视频时长、查询类型、线索注解和模态覆盖方面的限制。
CG-AV-Counting is a benchmark dataset for evaluating the long-video counting capabilities of multimodal large language models (MLLMs). This dataset was created by a research team from Nanjing University, containing 1,027 multimodal questions and 5,845 annotated cues, covering 497 long videos. The dataset supports both black-box and white-box evaluations, enabling comprehensive testing of end-to-end and reasoning-based counting capabilities. CG-AV-Counting aims to address the limitations of existing counting benchmarks in terms of video duration, query types, cue annotation, and modal coverage.
提供机构:
南京大学
创建时间:
2025-06-06
原始信息汇总
AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs
数据集概述
- 数据集名称: CG-AV-Counting
- 作者: Lidong Lu, Guo Chen, Zhiqi Li, Yicheng Liu, Tong Lu
- 机构: 南京大学
- 年份: 2025
- 论文链接: https://arxiv.org/abs/2506.05328
数据集详情
- 视频数量: 497个长视频(均超过10分钟)
- 问题数量: 1,027个多模态查询问题
- 标注线索: 5,845个细粒度人工标注线索
- 模态需求: 40%样本需音频+视觉模态,其余仅需视觉模态
- 计数目标类型: 对象计数、事件计数、属性计数
- 数值范围: 1-76(长尾分布,主要集中在1-20)
- 视频类别: 超过10类(体育、生活记录、幽默、教程等)
基准测试特点
- 首创性: 首个专门评估MLLMs视频计数能力的综合基准
- 对比优势:
- 同时包含音频和视觉模态
- 更复杂的查询
- 提供细粒度计数线索
- 支持端到端和基于推理的计数评估
评估指标
黑盒评估(端到端计数)
- Long Acc: 完整视频中的计数和时序定位
- Ref Acc: 修剪参考片段中的计数
- 指标:
- 准确率(Acc)
- 容错准确率(OBOA)
- 平均绝对误差(MAE)
- 均方根误差(RMSE)
白盒评估(显式证据定位)
- White-box Counting Score (WCS): 结合定位准确性和计数惩罚
- Instruction-Following Accuracy (IFA): 输出格式匹配比例
基线模型AV-Reasoner
- 训练方法: GRPO+课程学习
- 性能: 在多个基准测试中达到SOTA
- 局限性: 在域外基准上,语言空间推理未能带来性能提升
引用格式
bibtex @misc{lu2025avreasoner, title={AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs}, author={Lidong Lu and Guo Chen and Zhiqi Li and Yicheng Liu and Tong Lu}, year={2025}, eprint={2506.05328}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2506.05328}, }
搜集汇总
数据集介绍
构建方式
CG-AV-Counting数据集的构建采用三阶段标注流程,首先通过Gemini 2.0 Flash生成候选问题与参考时间区间,随后由人工标注员进行全局视频预览与问题筛选,最终通过细粒度线索标注实现验证。数据集基于CG-Bench的497段超10分钟长视频,涵盖视觉、听觉及跨模态查询,包含1,027个多模态问题与5,845条手工标注线索,支持事件、物体及属性三类计数目标。标注过程中采用仲裁机制确保样本质量,并通过结合草稿区间与线索区间确定最终参考范围。
特点
该数据集具有多模态交互、长视频上下文和细粒度标注三大核心特征。其创新性地设计了五种查询模态组合(纯视觉、纯听觉、视觉参考听觉查询等),覆盖超过10个内容领域的视频素材,且所有视频时长均超过10分钟以评估长程时序推理能力。数据集提供事件时间戳、物体边界框及属性聚类等结构化线索标注,支持黑白盒双评估协议。统计显示计数目标呈长尾分布(1-76次),其中40%样本需跨模态协同分析,为现有基准中模态覆盖最全面的计数测试平台。
使用方法
使用CG-AV-Counting时可采用端到端黑盒评估与可解释白盒评估双协议。黑盒模式下提供完整视频(Long Acc)或修剪片段(Ref Acc),通过准确率、容错准确率(OBOA)、平均绝对误差(MAE)和均方根误差(RMSE)四项指标衡量计数性能。白盒评估则要求模型输出带证据的推理过程:事件计数需标注时序片段,物体计数需定位首帧边界框,属性计数需按查询特征聚类。评估采用加权计数分数(WCS),综合时空定位精度(IoU)与计数偏差惩罚(CAP),同时检测指令遵循准确率(IFA)。为适配不同模态输入,需分别调用视觉编码器、听觉编码器或多模态融合模块进行特征提取。
背景与挑战
背景概述
CG-AV-Counting是由南京大学的研究团队于2025年提出的一个多模态视频计数基准数据集。该数据集基于CG-Bench中的497个长视频构建,包含1,027个手动标注的多模态问题和5,845个标注线索,覆盖事件、对象和属性三种计数目标。数据集支持黑盒和白盒两种评估方式,旨在全面测试多模态大语言模型(MLLMs)在端到端计数和基于推理的计数任务中的表现。该数据集的创建填补了现有计数基准在长视频、多模态查询和细粒度线索标注方面的空白,为评估模型的精细对齐和推理能力提供了重要工具。
当前挑战
CG-AV-Counting面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,该数据集旨在解决视频计数任务中模型对长视频和多模态信息的处理能力不足的问题,尤其是模型在复杂查询和细粒度计数任务中的表现。在构建过程中,挑战包括长视频的标注复杂性、多模态线索的同步标注、以及确保计数目标的多样性和平衡性。此外,数据集的评估协议设计也面临如何准确衡量模型在时空推理和多模态融合方面的能力的挑战。
常用场景
经典使用场景
CG-AV-Counting数据集在视频理解和多模态大语言模型(MLLMs)的研究中扮演着关键角色。该数据集通过提供长视频中的多模态计数任务,为模型在复杂场景下的计数能力提供了全面评估。其经典使用场景包括对视频中的事件、物体和属性进行精确计数,例如统计视频中特定事件的发生次数、物体的数量或属性的多样性。这些任务不仅要求模型具备跨模态的信息整合能力,还需要在长时间范围内进行准确的时空定位和推理。
解决学术问题
CG-AV-Counting数据集解决了当前MLLMs在计数任务中的多个关键问题。首先,它弥补了现有基准数据集中视频时长过短、查询封闭、缺乏线索标注和多模态覆盖不足的缺陷。其次,通过提供细粒度的线索标注和多样化的计数目标,该数据集能够更准确地评估模型的真实推理能力,而非依赖猜测。此外,其黑盒和白盒评估协议为模型的端到端计数能力和可解释性提供了双重验证,推动了多模态推理研究的深入发展。
衍生相关工作
CG-AV-Counting数据集的推出催生了一系列相关研究和工作。基于该数据集,研究者提出了AV-Reasoner模型,通过GRPO和课程学习策略显著提升了计数性能。此外,该数据集还启发了对多模态大语言模型在长视频理解、时空推理和跨模态对齐方面的进一步探索。相关经典工作包括Video-R1、Video-Chat-R1等,这些研究在视觉推理任务中取得了显著成果,推动了多模态模型在复杂场景下的应用。
以上内容由遇见数据集搜集并总结生成


