WebSight
收藏arXiv2024-03-14 更新2024-06-21 收录
下载链接:
https://huggingface.co/datasets/HuggingFaceM4/WebSight
下载链接
链接失效反馈官方服务:
资源简介:
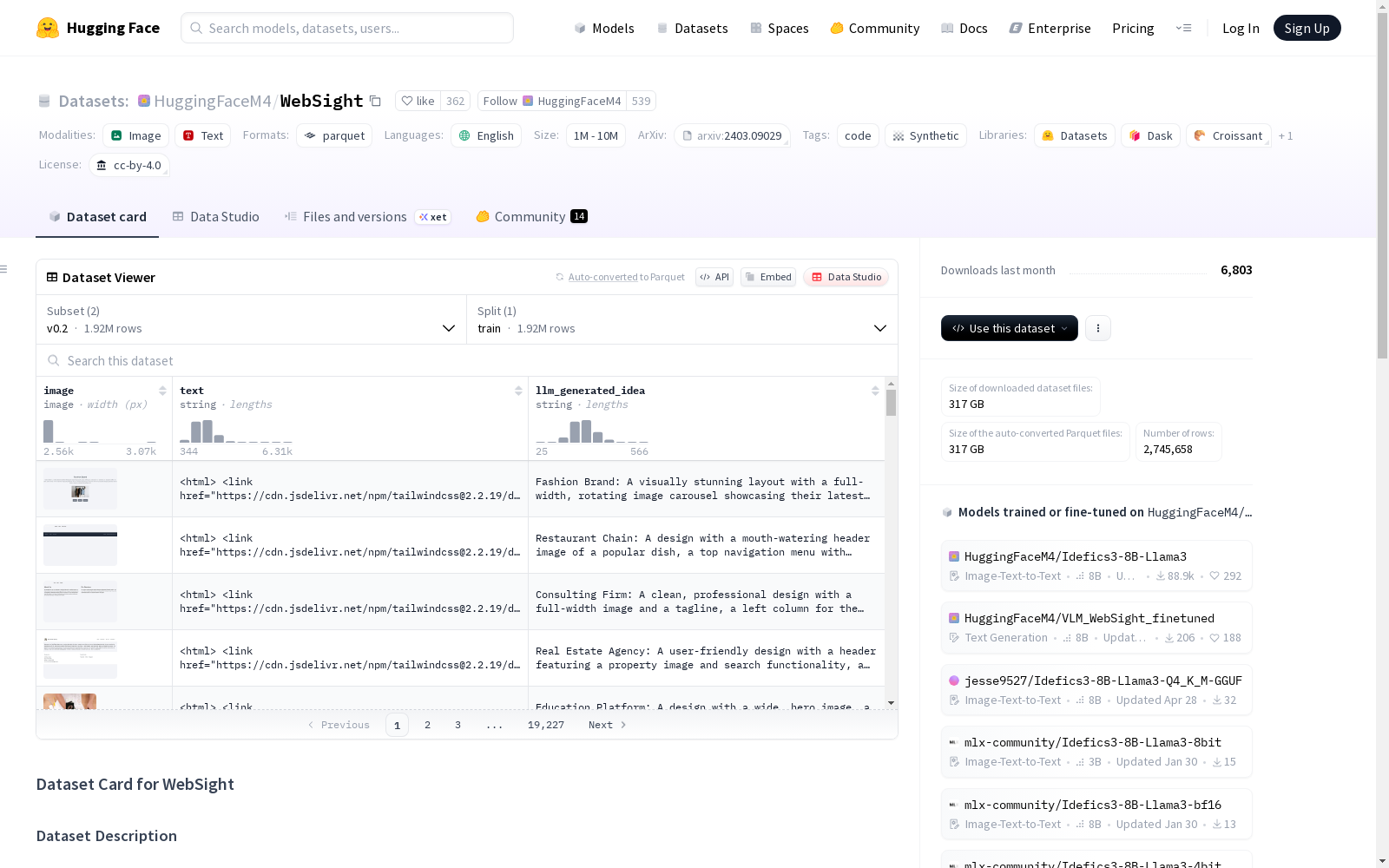
WebSight是由Hugging Face创建的一个综合合成数据集,包含200万对HTML代码及其对应的网页截图。该数据集通过使用大型语言模型生成多样化的网站主题和设计,确保了数据的高质量和多样性。创建过程中,首先使用小型语言模型生成网站概念,然后通过大型语言模型生成最终的HTML代码。WebSight的应用领域主要集中在自动化网页开发,旨在通过AI技术加速UI开发任务,推动无代码解决方案的发展。
WebSight is a comprehensive synthetic dataset created by Hugging Face, containing 2 million pairs of HTML code and their corresponding webpage screenshots. This dataset leverages large language models (LLMs) to generate diverse website themes and designs, ensuring high data quality and diversity. During its development, small language models are first employed to generate website concepts, followed by large language models to produce the final HTML code. The primary application scenarios of WebSight focus on automated web development, aiming to accelerate UI development tasks via AI technologies and promote the advancement of no-code solutions.
提供机构:
Hugging Face
创建时间:
2024-03-14
搜集汇总
数据集介绍
构建方式
WebSight数据集的构建方式独具匠心。首先,研究者们利用一个小型语言模型生成多样化的网站主题和设计,作为后续步骤的基础。然后,将这些设计输入到一个大型语言模型中,该模型主要在代码数据上进行训练,并经过指令调整,从而生成最终的HTML代码。这一过程确保了数据集包含多种风格的同时,还生成了高质量的代码。此外,为了简化VLMs的学习过程,WebSight采用了Tailwind CSS,它允许直接在HTML文档中进行样式设置,无需外部样式文件,从而生成更简洁的代码。
特点
WebSight数据集具有显著的特点。首先,它是一个包含200万个HTML代码及其对应屏幕截图的合成数据集,这一规模在同类数据集中是空前的。其次,数据集中的HTML代码采用了Tailwind CSS,这使得代码更加简洁且易于学习。此外,WebSight中的屏幕截图包含了整个网页,无论其长度如何,这为VLMs提供了丰富的学习材料。最后,WebSight的数据集是开源的,这为研究社区提供了宝贵的资源,可以加速相关领域的研究进展。
使用方法
WebSight数据集的使用方法主要包括两个方面。首先,它被用于微调一个基础VLM模型,使其能够将网页截图转换为可用的HTML代码。这种能力对于UI开发者来说非常有价值,可以加速无代码模块和插件的设计。其次,WebSight的数据集为研究社区提供了一个开放和可访问的资源,可以用于研究和改进VLMs。此外,由于WebSight的数据集是开源的,研究者和开发者可以自由地使用和修改数据集,以适应自己的研究需求。
背景与挑战
背景概述
随着视觉语言模型(VLMs)的快速发展,其在图像描述、问答和光学字符识别(OCR)等任务上展现出卓越的能力。然而,将网站截图转换为可用的HTML代码这一任务,尽管对网页开发者极具价值,却一直鲜有探索。Hugging Face团队的研究者们注意到这一领域的空白,并提出了WebSight数据集,这是一个由200万对HTML代码及其对应的截图组成的合成数据集。该数据集的创建旨在解决视觉语言模型在转换截图到HTML代码任务上的训练需求,通过为模型提供大量高质量的数据对,以促进模型学习截图与HTML代码之间的关联。WebSight数据集的开放源代码发布,为研究人员和开发者提供了宝贵的资源,有望推动该领域的研究进展,并促进无代码解决方案的开发。
当前挑战
WebSight数据集的研究面临着一系列挑战。首先,VLMs在转换截图到HTML代码这一特定任务上的能力不足,主要归因于缺乏大规模、高质量的截图-HTML代码数据集。其次,在构建数据集的过程中,研究者们必须克服HTML代码中的噪声、长度和外部依赖等问题。例如,网页上的HTML文件通常包含注释、脚本或其他数据,且可能过长,超出当前模型的最大序列长度。此外,HTML代码常常依赖于外部的JavaScript(JS)或层叠样式表(CSS)脚本,这增加了创建能够忠实再现截图设计意图的独立HTML文件的复杂性。为了解决这些问题,研究者们采用了一种合成HTML代码的方法,使用大型语言模型(LLMs)来生成代码,并通过控制代码生成过程来确保数据的清洁性、简洁性和结构性。尽管如此,生成的代码仍然面临与真实网站中图像的整合问题,以及如何寻找与网页内容相关的图像的挑战。
常用场景
经典使用场景
WebSight 数据集主要用于训练和评估视觉语言模型(VLMs)将网页截图转换为可用的 HTML 代码的能力。通过提供大量的 HTML 代码和其对应的截图对,WebSight 促进了 VLMs 在网页开发中的研究和应用,特别是对于无需编码的解决方案的开发。例如,设计师可以快速将设计草图转换为功能性的 UI 组件和代码,从而显著提高 UI 开发的迭代速度。
衍生相关工作
WebSight 数据集的创建和开源发布促进了视觉语言模型在网页截图到 HTML 转换任务上的研究和应用。例如,Design2Code 项目使用了 WebSight 数据集作为基准来评估 VLMs 在生成 HTML 代码方面的能力。此外,WebSight 数据集还可以用于开发新的 VLMs 模型,这些模型可以更好地理解和生成网页代码,从而推动网页开发自动化的发展。
数据集最近研究
最新研究方向
WebSight数据集旨在解决将网页截图转换为HTML代码这一挑战,这是一个对网页开发者极具价值但尚未充分探索的领域。该数据集由2百万对HTML代码及其对应的截图组成,为视觉语言模型(VLMs)的训练提供了丰富的资源。研究团队通过在WebSight数据集上微调基础VLM,展示了模型在将网页截图转换为功能性HTML代码方面的能力。此外,该模型还能够适应未经训练的场景,如将手写草图转换为功能性HTML代码。WebSight数据集的开源发布将进一步推动这一领域的研究,促进UI开发任务的自动化和提升无代码解决方案的能力。
相关研究论文
- 1Unlocking the conversion of Web Screenshots into HTML Code with the WebSight DatasetHugging Face · 2024年
以上内容由遇见数据集搜集并总结生成


