epadb
收藏Hugging Face2026-01-13 更新2026-01-14 收录
下载链接:
https://huggingface.co/datasets/hashmin/epadb
下载链接
链接失效反馈官方服务:
资源简介:
EpaDB是一个用于发音评分研究的语音数据库,包含50名阿根廷西班牙语使用者(25名男性和25名女性)朗读英语短语的录音,总计约3.5小时的语音数据。每个说话者录制了64个短句,这些短句包含对该人群来说难以发音的音素。数据集支持发音评估、音素识别、音素级错误检测和对齐分析等任务。数据集的每个条目都是一个JSON格式的语音片段描述,包含音素序列、音素级标签、时间戳、全局评分、说话者元数据、音频元数据和参考文本转录等信息。数据集分为训练集和测试集,分别包含1,903和1,263个例子。数据集的许可为CC BY-NC 4.0,允许非商业用途并需署名。
EpaDB is a speech database designed for pronunciation scoring research. It contains recordings of English phrases read by 50 Argentine Spanish speakers (25 males and 25 females), with a total of approximately 3.5 hours of speech data. Each speaker recorded 64 short sentences that include phonemes which are challenging for this population to pronounce. This dataset supports tasks including pronunciation assessment, phoneme recognition, phoneme-level error detection, and alignment analysis. Each entry in the dataset is a JSON-formatted speech segment description, containing information such as phoneme sequences, phoneme-level labels, timestamps, global scores, speaker metadata, audio metadata, and reference text transcriptions. The dataset is split into training and test sets, with 1,903 and 1,263 examples respectively. The dataset is licensed under CC BY-NC 4.0, allowing non-commercial use with proper attribution.
创建时间:
2026-01-10
原始信息汇总
EpaDB 数据集概述
数据集简介
EpaDB 是一个用于发音评分研究的语音数据库。该语料库包含 50 名阿根廷西班牙语使用者(25 名男性和 25 名女性)朗读英语短语的录音。每位说话者录制了 64 个包含该人群难以发音的语音的短句,总计约 3.5 小时的语音。
支持任务
- 发音评估 – 预测话语级别的全局分数或音素级别的正确/错误。
- 音素识别 – 预测音素序列。
- 音素级错误检测 – 将每个音素分类为插入、删除、扭曲、替换或正确。
- 对齐分析 – 利用 MFA 时间戳研究强制对齐质量或优化发音模型。
语言
- L2 话语:英语
- 说话者 L1:西班牙语
数据集结构
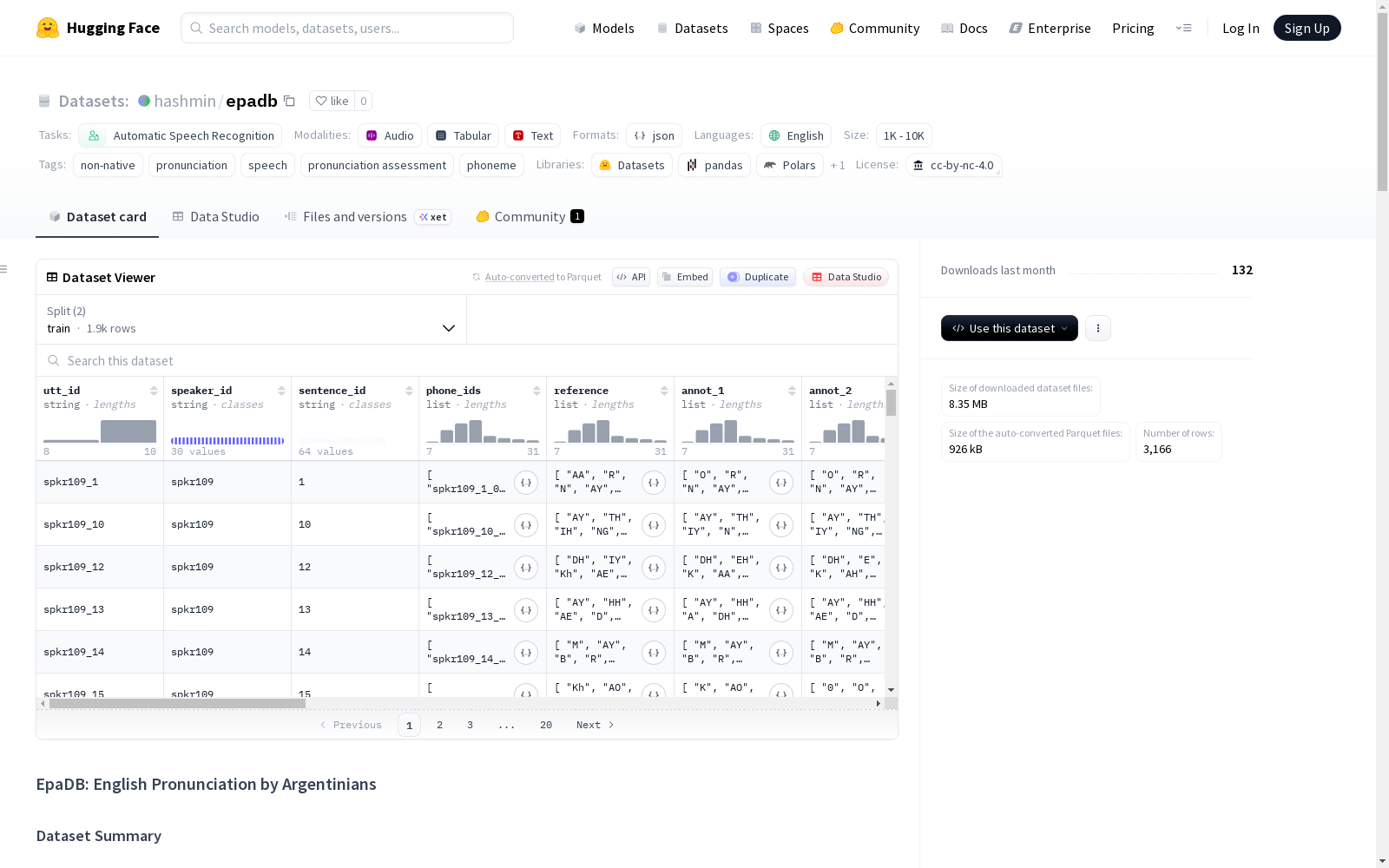
数据实例
每个 JSON 条目描述一个话语:
- 参考转录 (
reference) 和标注者 (annot_1, 可选的annot_2) 的音素序列。 - 音素级标签 (
label_1,label_2) 和派生的error_type类别。 - 每个音素的 MFA 开始/结束时间戳 (
start_mfa,end_mfa)。 - 每个话语的全局分数 (
global_1,global_2) 和派生的说话者水平 (level_1,level_2)。 - 说话者元数据 (
speaker_id,gender)。 - 音频元数据 (
duration,sample_rate,wav_path) 以及波形本身。 - 参考句子的正字法转录 (
transcription)。
数据字段
| 字段 | 类型 | 描述 |
|---|---|---|
utt_id |
string | 唯一话语标识符(例如 spkr28_1)。 |
speaker_id |
string | 说话者标识符。 |
sentence_id |
string | 参考句子 ID(匹配 reference_transcriptions.txt)。 |
phone_ids |
sequence[string] | 每个话语的唯一音素标识符。 |
reference |
sequence[string] | 参考音素,旨在匹配说话者最接近的目标发音。 |
annot_1 |
sequence[string] | 标注者 1 的音素(- 标记删除)。 |
annot_2 |
sequence[string] | 标注者 3 的音素(如果可用),否则为空。 |
label_1 |
sequence[string] | 标注者 1 的音素标签("1" 正确,"0" 错误)。 |
label_2 |
sequence[string] | 标注者 3 的音素标签(如果存在)。 |
error_type |
sequence[string] | 派生类别:correct, insertion, deletion, distortion, substitution。 |
start_mfa |
sequence[float] | 音素开始时间(秒)。 |
end_mfa |
sequence[float] | 音素结束时间(秒)。 |
global_1 |
float or null | 标注者 1 的话语级别分数(1–4)。 |
global_2 |
float or null | 标注者 3 的分数(如果可用)。 |
level_1 |
string or null | 来自标注者 1 的说话者水平熟练度等级("A"/"B")。 |
level_2 |
string or null | 来自标注者 3 的说话者等级。 |
gender |
string or null | 说话者性别("M"/"F")。 |
duration |
float | 话语持续时间(秒)(重采样至 16 kHz 后)。 |
sample_rate |
int | 采样率(Hz)(16,000)。 |
wav_path |
string | 波形文件名(<utt_id>.wav)。 |
audio |
Audio | 自动加载的波形(16 kHz)。 |
transcription |
string or null | 参考句子文本。 |
数据划分
| 划分 | 示例数量 |
|---|---|
| 训练集 | 1,903 |
| 测试集 | 1,263 |
注意事项
- 当标注者 3 未标注某个话语时,相关字段(
annot_2,label_2,global_2,level_2)不存在或设置为 null。 - 错误类型来自对比 MFA 参考音素与标注者 1 标签的简单启发式方法。
- 波形在清单生成期间使用
ffmpeg重采样至 16 kHz。 - 强制对齐和注释被合并以生成每个说话者/分区的丰富 CSV 文件。
- 全局分数按说话者平均以派生
level_*等级(如果平均值 ≥ 3 则为A,否则为B)。
许可信息
- 音频和注释:CC BY-NC 4.0(允许非商业用途,需署名)。
引用格式
@article{vidal2019epadb, title = {EpaDB: a database for development of pronunciation assessment systems}, author = {Vidal, Jazmin and Ferrer, Luciana and Brambilla, Leonardo}, journal = {Proc. Interspeech}, pages = {589--593}, year = {2019} }
使用方式
安装依赖并加载数据集: python from datasets import load_dataset
上传前的本地使用:
ds = load_dataset( "epadb_dataset/epadb.py", data_dir="/path/to/epadb", # 包含 train.json, test.json, WAV/ 的文件夹 split="train", ) print(ds) print(ds[0]["utt_id"], ds[0]["audio"]["sampling_rate"]) # 16000
推送到 Hugging Face Hub 后:
ds = load_dataset("JazminVidal/epadb", split="train")
致谢
该数据库是布宜诺斯艾利斯大学应用人工智能实验室语音实验室的努力成果,并部分由 Google 通过 2018 年 Google 拉丁美洲研究奖资助。
搜集汇总
数据集介绍
构建方式
在二语习得研究领域,构建高质量的发音评估数据集对于推动语音技术发展至关重要。EpaDB数据集的构建过程严谨而系统,首先选取了50名阿根廷西班牙语母语者作为发音人,男女各半,以确保样本的性别平衡。每位发音人朗读了64条精心设计的英语短语,这些短语专门包含了对于该群体而言发音困难的语言现象,累计收集了约3.5小时的语音数据。随后,研究团队对语音进行了细致的音素级标注,由至少一名标注员提供参考音素序列、正确性标签及语句级全局评分,部分数据还引入了第二名标注员以增强可靠性。最后,利用Montreal Forced Aligner (MFA)工具生成了音素级的时间对齐信息,并将所有元数据与音频波形整合为结构化的JSON格式,形成了包含训练集和测试集的完整语料库。
特点
EpaDB数据集在发音评估研究领域展现出鲜明的特色。其核心价值在于提供了多层次的精细标注,不仅包含语句级的整体发音质量评分,还深入到音素级别,标注了每个音素的正确与否,并进一步推导出插入、删除、扭曲、替换等具体的错误类型。这种细粒度的标注体系为深入分析发音偏误模式提供了可能。数据集的结构设计科学,每个语音样本均关联了丰富的元数据,包括发音人身份、性别、参考文本转录以及经过MFA对齐的音素起止时间。尤为重要的是,数据集平衡考虑了发音人的性别分布,并包含了部分由双标注员验证的数据,这在一定程度上保障了标注的一致性与数据质量,使其成为研究西班牙语母语者英语发音问题的宝贵资源。
使用方法
对于致力于发音评估或语音处理的研究者而言,EpaDB数据集提供了清晰便捷的使用路径。数据集已预先划分为训练集和测试集,用户可通过Hugging Face的`datasets`库直接加载。在本地使用时,需指定包含`train.json`、`test.json`和`WAV`音频文件夹的本地路径;若数据集已上传至Hub,则可直接通过仓库标识符调用。加载后,每条数据实例均以字典形式呈现,用户可轻松访问其音频波形、音素序列、各类标签及评分等全部字段。这使得研究者能够灵活地将该数据集应用于多种任务,例如训练模型进行语句级发音评分、音素识别、音素级错误检测,或是利用其精确的时间对齐信息进行发音模型的对齐分析与优化。
背景与挑战
背景概述
在第二语言习得与语音技术交叉领域,发音评估系统的研发依赖于高质量、细粒度标注的语音数据库。EpaDB(English Pronunciation by Argentinians)由布宜诺斯艾利斯大学应用人工智能实验室语音实验室于2019年创建,核心研究团队包括Jazmin Vidal、Luciana Ferrer和Leonardo Brambilla。该数据集旨在解决阿根廷西班牙语母语者英语发音的自动评估问题,聚焦于该群体易混淆音素的发音错误检测与评分。通过收录50位说话者朗读的64个短语,共计约3.5小时语音,并辅以音素级错误标注与话语级全局分数,EpaDB为发音评估模型提供了关键数据支撑,推动了非母语发音分析技术的实证研究。
当前挑战
EpaDB所应对的领域挑战在于非母语发音评估的复杂性与主观性。传统方法难以精准量化音素层面的细微错误,如扭曲、替换或插入,且评估标准易受评委主观判断影响。构建过程中的挑战包括:针对阿根廷西班牙语母语者设计包含易错音素的语音材料;确保多位标注者在音素序列与错误类型上的一致性;利用强制对齐技术获取精确的音素时间边界,并处理标注缺失或冲突情况。这些挑战要求数据集在语音学标注规范与技术流程上实现严谨平衡。
常用场景
经典使用场景
在语音技术领域,EpaDB数据集为发音评估研究提供了关键资源。该数据集收录了阿根廷西班牙语母语者朗读英语短语的音频,特别聚焦于非母语发音者难以掌握的音素。研究人员利用其精细的音素级标注和全局评分,构建并验证自动发音评分模型,以客观量化学习者的发音准确性,从而推动计算机辅助语言学习系统的进步。
解决学术问题
EpaDB直接应对了发音评估中缺乏高质量、细粒度标注数据的挑战。它通过提供音素级别的正确/错误标签及错误类型分类,支持学术界深入探究非母语发音的声学模式与错误规律。该数据集促进了发音评分算法的基准测试,解决了模型泛化能力评估的难题,并为跨语言发音迁移研究奠定了实证基础,显著提升了该领域研究的可重复性与科学性。
衍生相关工作
自EpaDB发布以来,已催生了一系列围绕发音评估的经典研究工作。学者们以其为基础,探索了基于深度学习的端到端评分模型、针对特定音素错误的检测算法,以及利用多任务学习整合全局与局部发音特征的方法。这些研究不仅深化了对发音评估任务的理解,也推动了相关模型在更大规模或多语言数据集上的应用与优化。
以上内容由遇见数据集搜集并总结生成


