VLR-BENCH
收藏arXiv2024-12-13 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/MLP-KTLim/VLR-Bench
下载链接
链接失效反馈官方服务:
资源简介:
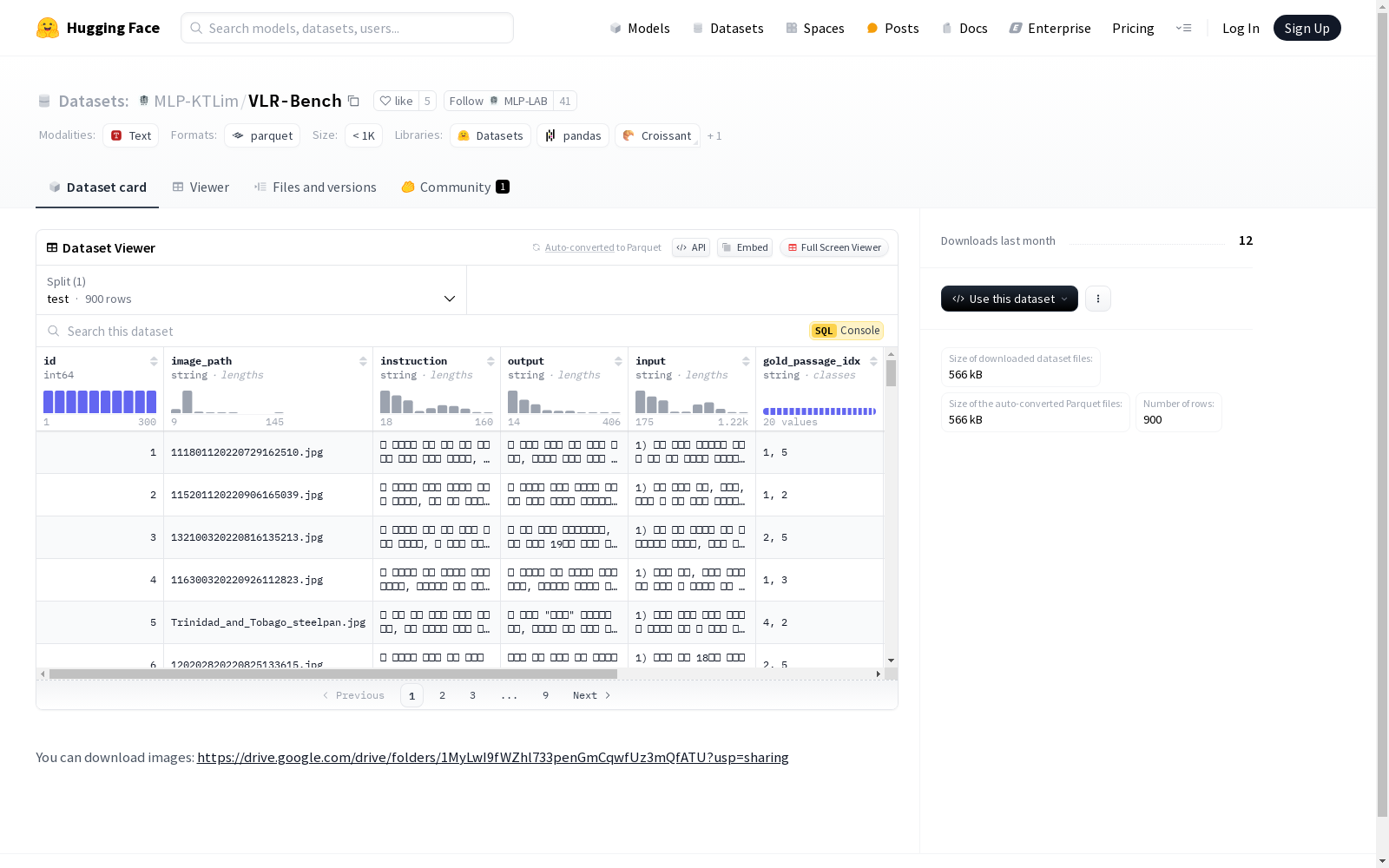
VLR-BENCH是由首尔科学技术大学创建的一个视觉语言检索增强生成(RAG)的多语言基准数据集,旨在评估视觉语言模型(VLM)在检索增强生成任务中的能力。该数据集包含300个数据集,每个数据集包含五个不同的段落,其中只有两个段落包含解决查询所需的直接信息。数据集的内容涵盖了英语、中文和韩语的通用知识和文化数据,通过手动筛选和GPT-4o生成高质量的问题-答案对。数据集的创建过程包括图像选择、问题生成和外部知识的生成与验证。VLR-BENCH主要应用于评估模型在处理需要外部知识检索的视觉语言任务中的表现,旨在解决模型在选择有用段落以生成准确答案方面的挑战。
VLR-BENCH is a multilingual visual-language retrieval-augmented generation (RAG) benchmark dataset developed by Seoul National University of Science and Technology, designed to evaluate the performance of Vision-Language Models (VLMs) on retrieval-augmented generation tasks. This benchmark comprises 300 subsets, each containing five distinct paragraphs, with only two of the paragraphs containing the direct information required to address the corresponding query. Its content covers general knowledge and cultural data across English, Chinese, and Korean, and high-quality question-answer pairs are generated through manual screening and GPT-4o-assisted creation. The dataset creation pipeline includes image selection, question generation, as well as external knowledge generation and verification. VLR-BENCH is primarily utilized to assess model performance on visual-language tasks that require external knowledge retrieval, and it aims to resolve the challenges faced by models when selecting useful paragraphs to generate accurate answers.
提供机构:
首尔科学技术大学
创建时间:
2024-12-13
原始信息汇总
数据集概述
数据集信息
-
特征(Features):
- id: 数据类型为
int64 - image_path: 数据类型为
string - instruction: 数据类型为
string - output: 数据类型为
string - input: 数据类型为
string - gold_passage_idx: 数据类型为
string - keyword1: 数据类型为
string - keyword2: 数据类型为
string - language: 数据类型为
string
- id: 数据类型为
-
数据分割(Splits):
- test: 包含 900 个样本,数据大小为 1042936 字节
-
数据集大小:
- 下载大小: 565960 字节
- 数据集大小: 1042936 字节
-
配置(Configs):
- default:
- 数据文件路径:
data/test-*
- 数据文件路径:
- default:
其他信息
- 图像下载链接: https://drive.google.com/drive/folders/1MyLwI9fWZhl733penGmCqwfUz3mQfATU?usp=sharing
搜集汇总
数据集介绍
构建方式
VLR-BENCH数据集的构建基于视觉问答(VQA)任务,旨在评估视觉语言模型(VLM)在检索增强生成(RAG)方面的能力。数据集包含32,000个自动生成的指令遵循示例,每个示例由图像、查询、五个外部知识段落和描述性答案组成。这些段落中仅有两个包含直接回答查询所需的信息,其余段落则用于测试模型区分有用信息的能力。数据集的构建过程包括从BOK-VQA数据集中手动筛选图像,使用GPT-4o生成问题和答案,并通过人工注释者进行审核和选择,确保数据的高质量和相关性。
特点
VLR-BENCH数据集的主要特点在于其多语言性和复杂性。数据集包含英语、中文和韩语三种语言,涵盖了150个基于一般知识和150个基于文化背景的数据集。每个数据样本包含五个外部知识段落,其中两个是“黄金段落”,直接包含回答查询所需的信息,另外两个是“白银段落”,与主题相关但偏离答案,最后一个则是“青铜段落”,与图像和问题无关。这种设计使得模型必须具备区分有用信息的能力,从而生成准确的答案。
使用方法
VLR-BENCH数据集主要用于评估视觉语言模型在检索增强生成任务中的表现。使用该数据集时,模型需要根据给定的图像和查询,从五个外部知识段落中选择出有用的信息,并生成相应的答案。数据集的评估指标包括关键词匹配分数(KMS)、Rouge、BLEU和BERT-Score等,这些指标能够全面评估模型在生成答案时的准确性、完整性和相关性。通过使用VLR-BENCH数据集,研究人员可以更好地理解和提升模型在复杂视觉问答任务中的表现。
背景与挑战
背景概述
VLR-BENCH数据集由首尔科学技术大学(SeoulTech)和汉巴特国立大学(Hanbat National University)的研究团队于2024年提出,旨在评估视觉语言模型(VLMs)在检索增强生成(RAG)任务中的表现。该数据集的核心研究问题是如何在多语言背景下,通过提供多个外部知识段落,测试模型选择有用段落并生成准确答案的能力。VLR-BENCH包含32,000个自动生成的指令遵循示例,涵盖英语、中文和韩语,旨在提升VLMs在RAG任务中的能力。该数据集的提出填补了现有数据集在多段落选择和多语言评估方面的空白,对视觉语言模型的研究和应用具有重要推动作用。
当前挑战
VLR-BENCH数据集面临的挑战主要集中在两个方面:一是如何有效解决视觉语言模型在处理外部知识时的选择难题,即模型需要从多个段落中准确识别出与问题相关的关键信息;二是数据集构建过程中遇到的挑战,包括如何确保多语言数据的准确性和一致性,以及如何在有限的资源下高效生成高质量的训练数据。此外,VLR-BENCH还需要应对模型在处理复杂查询时可能出现的错误信息干扰问题,确保模型能够正确利用检索到的外部知识生成准确的答案。
常用场景
经典使用场景
VLR-BENCH 数据集的经典使用场景主要集中在视觉语言模型(VLM)的评估与训练上。该数据集通过提供图像、查询、多个相关和不相关的文本段落以及答案,测试模型在检索增强生成(RAG)任务中的表现。具体而言,模型需要从五个段落中选择两个与问题相关的段落,并基于这些段落生成准确的答案。这种设计使得模型不仅需要具备图像理解能力,还需要具备从文本中筛选有用信息的能力,从而评估其在复杂场景下的综合表现。
衍生相关工作
VLR-BENCH 数据集的提出催生了一系列相关研究工作。首先,基于该数据集的训练方法,研究者开发了多种视觉语言模型,如 LLAVA-LLAMA-3 和 X-LLAVA,这些模型在多语言环境下表现出色。其次,VLR-BENCH 的成功应用也启发了其他研究者设计类似的检索增强生成任务数据集,如 InfoSeek 和 Encyclopedic VQA。此外,VLR-BENCH 还推动了对多模态模型在知识检索和生成任务中表现的深入研究,特别是在如何有效利用外部知识方面,为未来的研究提供了新的方向。
数据集最近研究
最新研究方向
VLR-BENCH 数据集的最新研究方向主要集中在视觉语言模型(VLMs)的检索增强生成(RAG)能力评估上。该数据集通过提供包含五个不同段落的复杂问题,测试模型在选择有用段落以生成准确答案方面的能力。研究重点在于评估模型如何有效利用外部知识,特别是在多语言环境下,模型能否准确识别并利用相关段落。此外,VLR-BENCH 还通过引入 VLR-IF 训练数据,进一步增强模型在检索和生成任务中的表现,尤其是在处理需要外部知识的复杂查询时。这一研究方向不仅推动了 VLMs 在多语言环境下的应用,还为模型在实际应用中的知识整合能力提供了新的评估标准。
相关研究论文
- 1VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation首尔科学技术大学 · 2024年
以上内容由遇见数据集搜集并总结生成


