eval-whisper-tiny-multimed-hard-20260408-1930
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/Trelis/eval-whisper-tiny-multimed-hard-20260408-1930
下载链接
链接失效反馈官方服务:
资源简介:
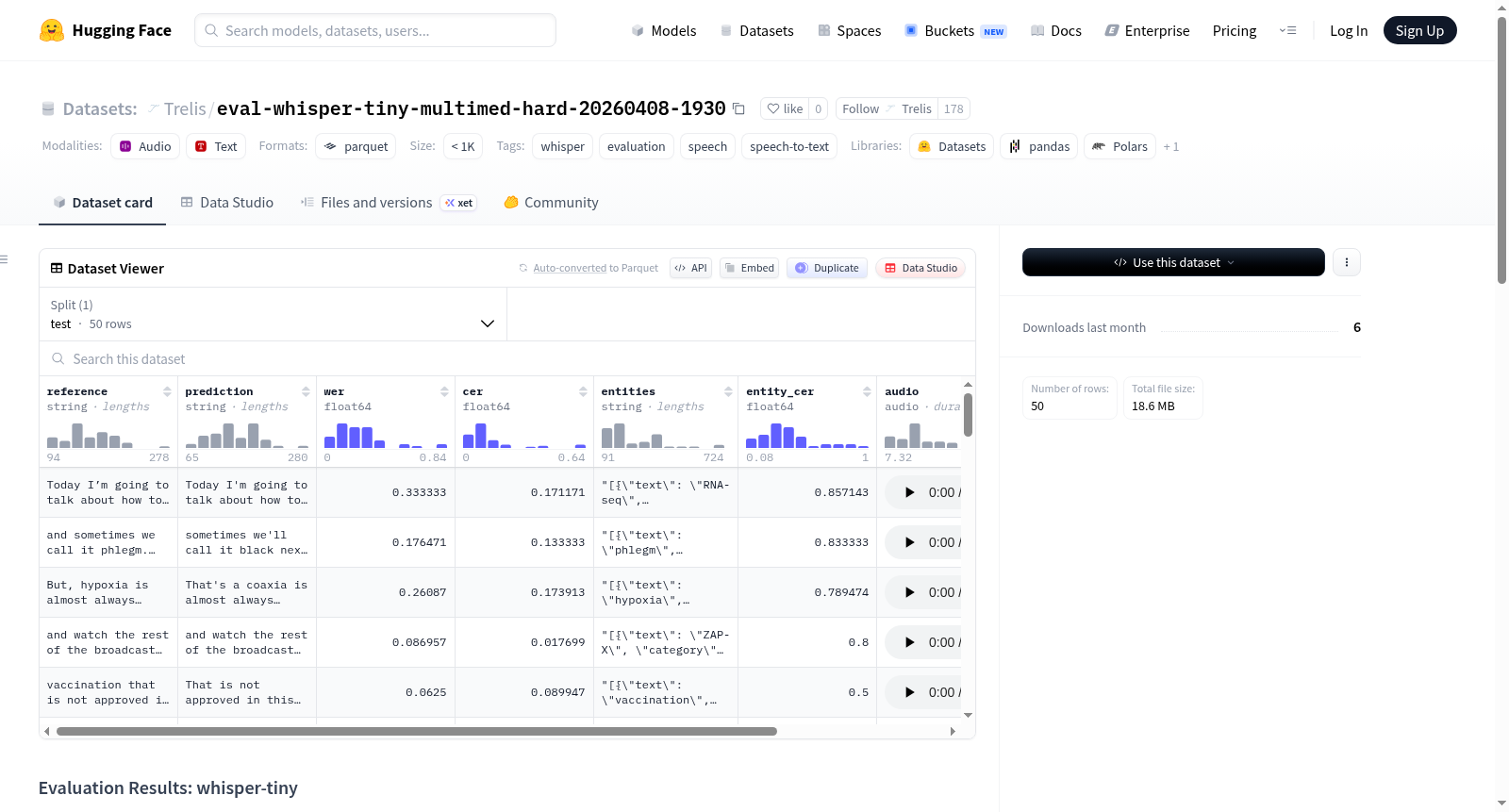
该数据集包含对 Whisper-tiny 模型在 Trelis/multimed-hard 数据集上的评估结果。数据集主要用于语音到文本模型的性能评估,重点关注转录准确性和实体识别。数据内容包括音频样本(如果源数据集提供)、参考转录文本、模型预测文本、词错误率(WER)、字符错误率(CER)、实体标注以及每个样本的实体字符错误率(Entity CER)。评估结果显示,整体字符错误率为14.36%,词错误率为23.56%,实体字符错误率为36.03%。不同类别的实体识别准确率有所差异,其中药物类别的识别准确率最高(CER为7.14%),而组织类别的识别准确率最低(CER为40.59%)。该数据集适用于语音识别模型的性能评估和比较研究。
This dataset contains the evaluation results of the Whisper-tiny model on the Trelis/multimed-hard dataset. It is primarily designed for performance evaluation of speech-to-text models, with a focus on transcription accuracy and entity recognition. The dataset includes audio samples (if provided by the original source dataset), reference transcriptions, model-predicted transcriptions, Word Error Rate (WER), Character Error Rate (CER), entity annotations, and Entity Character Error Rate (Entity CER) for each individual sample. The evaluation results indicate that the overall Character Error Rate is 14.36%, Word Error Rate is 23.56%, and Entity Character Error Rate is 36.03%. Recognition accuracy varies across different entity categories: the medication category achieves the highest recognition accuracy with a CER of 7.14%, while the organization category has the lowest recognition accuracy with a CER of 40.59%. This dataset is suitable for performance evaluation and comparative research of speech recognition models.
提供机构:
Trelis创建时间:
2026-04-09
搜集汇总
数据集介绍
构建方式
在语音识别技术不断演进的背景下,eval-whisper-tiny-multimed-hard-20260408-1930数据集的构建体现了对模型性能的精细化评估需求。该数据集基于Trelis/multimed-hard这一医学领域语音数据集,通过系统性地应用openai/whisper-tiny模型进行自动语音识别,生成了预测转录文本。构建过程中,每个音频样本均与参考转录对齐,并计算了词错误率和字符错误率等指标,同时整合了源数据中的实体标注信息,从而形成了一个结构化的评估结果集合,为模型在特定领域的表现提供了量化依据。
特点
该数据集的核心特点在于其专注于医学语音识别的评估场景,涵盖了解剖学、生物标志物、疾病状况、药物、组织和医疗程序等多个实体类别。它不仅提供了整体的词错误率和字符错误率,还细化了实体级别的字符错误率分析,例如药物类别的错误率仅为7.14%,而组织类别的错误率则高达40.59%,这揭示了模型在不同医学术语识别上的性能差异。这种细粒度的评估维度使得数据集能够深入反映模型在复杂专业领域中的识别能力与局限性。
使用方法
在语音识别研究与应用中,该数据集可作为评估whisper-tiny模型在医学领域性能的基准工具。研究人员可以直接利用数据集中的音频、参考转录、预测结果及错误率指标,进行模型对比分析或错误模式挖掘。通过关注实体类别错误率,用户能够识别模型在特定医学术语上的薄弱环节,从而指导模型优化或数据增强策略。此外,数据集的结构化格式便于集成到自动化评估流程中,支持高效的实验复现与结果验证。
背景与挑战
背景概述
随着自动语音识别技术的飞速发展,尤其是在医疗等专业领域的应用,对模型在复杂场景下的性能评估变得至关重要。eval-whisper-tiny-multimed-hard-20260408-1930数据集由Trelis机构于2024年创建,旨在系统评估Whisper-tiny模型在医学多模态困难数据集上的表现。该数据集聚焦于医学语音转录任务,核心研究问题在于量化模型在包含专业术语、多样口音及噪声干扰的音频数据中的识别准确性,通过词错误率和字符错误率等指标,为语音识别模型在专业领域的优化与部署提供关键基准,推动了领域自适应技术的发展。
当前挑战
该数据集所解决的领域问题在于医学语音识别,其挑战主要体现在模型对专业医学术语(如解剖结构、生物标志物、疾病条件等)的准确转录,这些术语往往拼写复杂且语境依赖性强,导致实体字符错误率高达36.03%,尤其在组织和程序类别上错误率超过39%。在构建过程中,挑战源于源数据multimed-hard本身的多模态与困难特性,包括音频质量不一、说话者口音多样、背景噪声干扰,以及医学实体标注的一致性维护,这些因素共同增加了评估的复杂度,要求评估框架能精准分离模型错误与数据固有噪声。
常用场景
经典使用场景
在语音识别领域,评估数据集常被用于基准测试和模型性能比较。该数据集专门针对Whisper-tiny模型在复杂多模态医疗音频上的表现进行评估,通过提供详细的词错误率和字符错误率指标,为研究者提供了一个标准化的测试平台,以衡量模型在嘈杂或专业领域音频上的转录准确性。
实际应用
在实际应用中,该数据集可用于优化医疗环境下的语音转文本系统,例如临床记录转录或医学教育工具。通过评估模型在硬样本上的表现,开发者能够识别并修正系统在关键实体(如病症、药物)上的错误,提升自动化转录的可靠性和安全性,支持更高效的医疗信息处理。
衍生相关工作
该数据集衍生了针对Whisper模型系列的多项研究,包括领域自适应训练、实体增强识别方法以及误差分析框架。相关经典工作聚焦于利用实体错误率数据改进医疗术语的识别,并推动了跨模态评估标准的发展,为后续语音识别模型在专业场景的优化提供了实证基础。
以上内容由遇见数据集搜集并总结生成


