Hausa-large-tts
收藏Hugging Face2025-12-02 更新2025-12-03 收录
下载链接:
https://huggingface.co/datasets/Aybee5/Hausa-large-tts
下载链接
链接失效反馈官方服务:
资源简介:
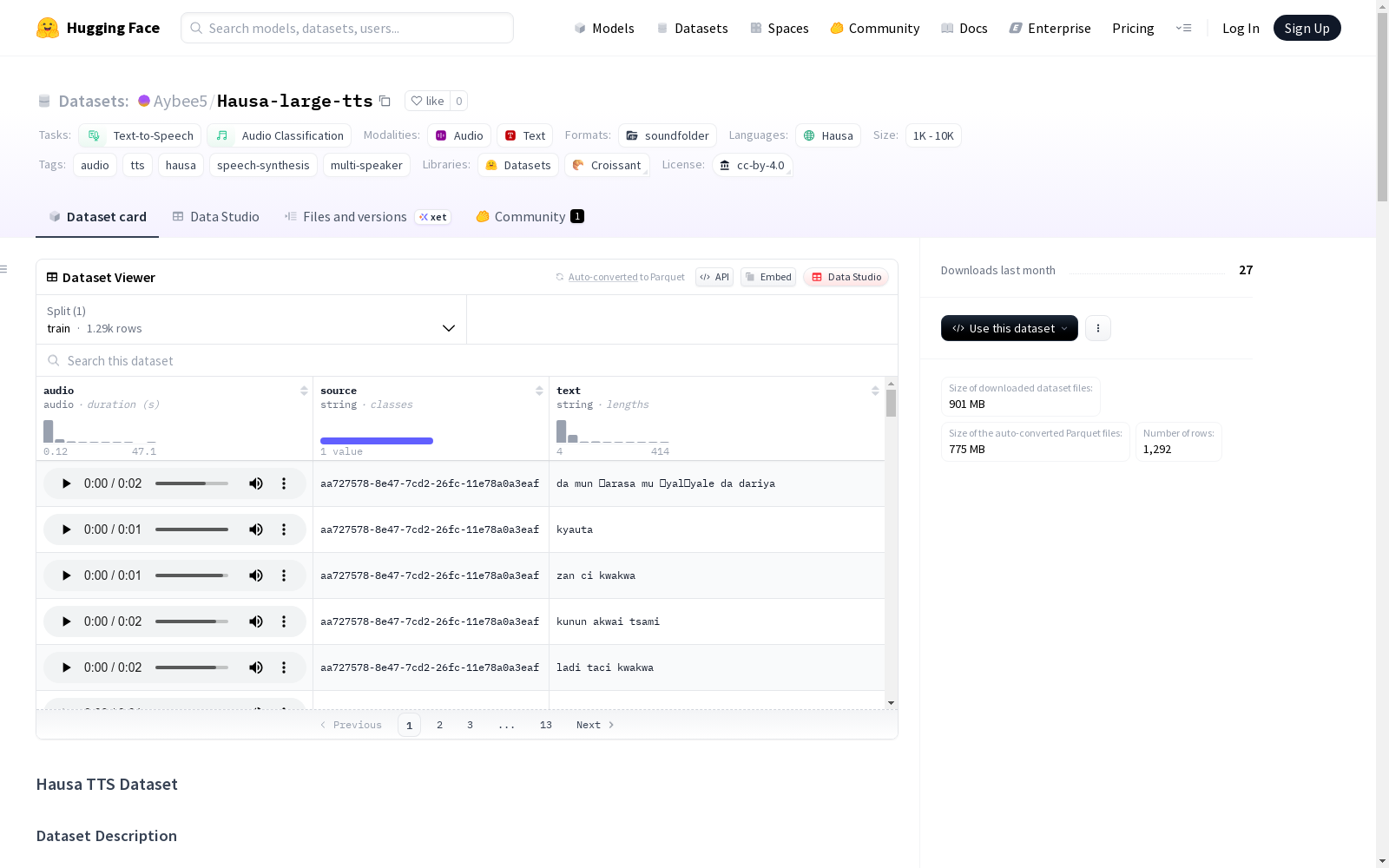
豪萨语TTS数据集包含多个说话者的豪萨语语音合成录音及其对应的文本转录,适用于语音合成模型训练、多说话者语音合成、豪萨语语音研究等领域。
创建时间:
2025-11-29
原始信息汇总
Hausa TTS 数据集概述
数据集基本信息
- 数据集名称:Hausa TTS Dataset
- 发布者:Aybee5
- 托管平台:Hugging Face
- 数据集地址:https://huggingface.co/datasets/Aybee5/Hausa-large-tts
- 语言:豪萨语 (ha)
- 许可证:Creative Commons Attribution 4.0 International (CC BY 4.0)
- 主要任务类别:文本转语音、音频分类
- 标签:音频、文本转语音、豪萨语、语音合成、多说话人
- 数据规模:小于1K样本
数据集内容与结构
数据构成
- 总样本数:约100条录音
- 说话人数量:3位独特的说话人
- 音频格式:WAV文件
- 目标采样率:24,000 Hz
- 语言:豪萨语
数据结构
数据集组织如下:
data/ ├── metadata.csv # 元数据(来源、音频路径、文本) └── audio_files/ ├── 97f373e8-f6e6-.../ # 说话人1的音频文件 ├── b0db0a87-2206-.../ # 说话人2的音频文件 └── c3621689-ca53-.../ # 说话人3的音频文件
数据字段
metadata.csv 文件包含以下列:
- file_name:音频文件(WAV格式)的相对路径
- source:说话人ID(UUID格式)
- text:音频对应的豪萨语文本转录
主要用途
- 文本转语音模型训练
- 多说话人语音合成
- 豪萨语语音研究
- 语音克隆应用
- 语音语料库分析
使用方式
加载数据集
python from datasets import load_dataset dataset = load_dataset("Aybee5/hausa-large-tts", split="train")
说话人信息处理
数据集包含3位独特说话人的录音,每位说话人由source字段中的UUID标识。训练多说话人TTS模型时,可将这些UUID映射为数字说话人ID。
数据收集与处理
- 音频数据使用MimicStudio录音系统收集,包含母语为豪萨语的说话人朗读文本提示。
- 所有音频文件以WAV格式存储,元数据在SQLite数据库中跟踪,并已导出为CSV格式以便分发。
使用注意事项
- 不同说话人之间的音频质量可能有所差异
- 部分音频文件可能存在背景噪音
- 文本转录使用拉丁字母书写的豪萨语
- 说话人特征(性别、年龄、口音)未明确标注
引用信息
如果研究中使用此数据集,请引用:
@dataset{hausa_tts_dataset, title={Hausa TTS Dataset}, author={Your Name}, year={2025}, publisher={Hugging Face}, howpublished={url{https://huggingface.co/datasets/Aybee5/hausa-large-tts}} }
搜集汇总
数据集介绍
构建方式
在低资源语言语音合成领域,构建高质量数据集是推动技术进步的关键。Hausa-large-tts数据集的构建依托于MimicStudio录音系统,通过邀请三位母语为豪萨语的发音人朗读文本提示词,系统性地采集了音频数据。所有录音均以WAV格式保存,并辅以SQLite数据库进行元数据管理,最终导出为结构清晰的CSV文件,确保了音频文件与对应豪萨语文本转录的精确配对。
特点
该数据集的核心特点在于其专注于豪萨语这一资源相对匮乏的语言,为多说话人语音合成研究提供了宝贵资源。数据集囊括了约100条录音样本,源自三位发音风格各异的独立说话人,每位说话人均由唯一的UUID标识。音频以24,000 Hz的目标采样率存储,文本转录采用拉丁字母书写,其多说话人属性为建模音色多样性及说话人适应技术奠定了基础。
使用方法
为便于研究与应用,该数据集可通过Hugging Face的`datasets`库直接加载。用户需指定数据集名称与分割集,即可获得包含音频路径、数组、采样率及文本的标准化数据结构。对于多说话人TTS模型训练,建议将说话人UUID映射为数值ID。加载后,可利用`Audio`特征将音频列转换为指定采样率,进而对接下游的语音合成或分析流程。
背景与挑战
背景概述
随着全球人工智能技术的蓬勃发展,低资源语言的语音合成研究逐渐成为计算语言学领域的重要议题。Hausa-large-tts数据集由Aybee5于2025年发布,专注于豪萨语这一广泛使用于西非地区但数字资源相对匮乏的语言。该数据集旨在为豪萨语文本到语音转换任务提供基础语料,通过集成三位发音人的录音及其对应文本转录,支持多说话人语音合成模型的构建。其创建不仅填补了豪萨语在语音合成领域的数据空白,也为促进语言技术的包容性发展提供了关键资源,对推动非洲本土语言的数字化进程具有积极意义。
当前挑战
在豪萨语语音合成领域,核心挑战在于低资源语言缺乏大规模、高质量的标注语音数据,这限制了深度学习方法的应用效果。具体而言,数据稀缺导致模型在韵律建模、发音准确性和自然度方面表现受限,难以捕捉语言的细微特征。从数据集构建角度看,Hausa-large-tts仅包含约100条录音和三位说话人,样本规模较小,且说话人多样性不足,可能影响模型的泛化能力。此外,音频质量存在波动,部分录音伴有背景噪声,文本转录仅采用拉丁字母书写,未标注说话人的人口统计学特征,这些因素均对数据的一致性与实用性构成挑战。
常用场景
经典使用场景
在低资源语言语音合成领域,Hausa-large-tts数据集为豪萨语文本转语音研究提供了关键资源。该数据集最经典的使用场景是训练多说话人语音合成模型,通过整合三位不同说话人的音频与文本配对数据,研究人员能够构建能够生成自然、多样化语音输出的系统。这种多说话人设置不仅增强了模型的泛化能力,还为探索说话人身份编码和语音风格迁移奠定了基础。
实际应用
在实际应用层面,Hausa-large-tts数据集能够服务于豪萨语地区的语音技术开发。例如,可用于构建本地化的语音助手、有声读物生成系统或教育工具,为西非地区数百万豪萨语使用者提供便捷的语音交互服务。此外,在语音克隆和个性化语音合成应用中,该数据集的多说话人特性为定制化语音产品提供了数据基础,有助于推动语言技术在现实场景中的落地与普及。
衍生相关工作
围绕该数据集,已衍生出若干经典研究工作。例如,研究人员利用其进行低资源语言语音合成模型适配,探索基于迁移学习的豪萨语TTS系统构建。同时,该数据集也支持多说话人语音合成架构的验证与优化,促进了如说话人编码网络和语音风格解耦等技术的实验。这些工作不仅拓展了豪萨语语音技术的边界,也为其他低资源语言的类似研究提供了可借鉴的范式。
以上内容由遇见数据集搜集并总结生成


