CC-LARD-topics
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/Yusser/CC-LARD-topics
下载链接
链接失效反馈官方服务:
资源简介:
CC-LARD(Common Crawl Language and Region Dataset)是一个多语言网络语料库,附带文化主题标注和CTO叶节点对齐。该数据集作为NeurIPS 2026年Datasets & Benchmarks轨道论文的配套语料库,旨在提供文化主题分析和区域语言内容研究的基准。数据集包含来自53个主题建模地区的1,239,169个文档,每个文档均标注了地区标签、语言、FASTopic主题和CTO叶节点分配。完整CC-LARD语料库包含13,150,911个文档,涵盖140种语言和4,334个地区。数据集字段包括文本内容、语言代码、地区、URL、语言检测置信度、主题ID及标签、主题概率分布等。数据集适用于区域感知的语料审计、文化评估基线构建、预训练数据分析等任务。使用需遵守ODC-By v1.0许可和Common Crawl使用条款。
CC-LARD (Common Crawl Language and Region Dataset) is a multilingual web corpus with cultural topic annotations and CTO leaf node alignments. This dataset serves as a companion corpus for the NeurIPS 2026 Datasets & Benchmarks track paper, aiming to provide a benchmark for cultural topic analysis and regional language content research. The dataset contains 1,239,169 documents from 53 topic-modeled regions, each annotated with region labels, language, FASTopic themes, and CTO leaf node assignments. The complete CC-LARD corpus includes 13,150,911 documents, covering 140 languages and 4,334 regions. Dataset fields include text content, language code, region, URL, language detection confidence, topic ID and labels, topic probability distribution, etc. The dataset is suitable for region-aware corpus auditing, cultural evaluation baseline construction, pre-training data analysis, and other tasks. Use is subject to the ODC-By v1.0 license and Common Crawl terms of use.
创建时间:
2026-04-14
原始信息汇总
数据集概述
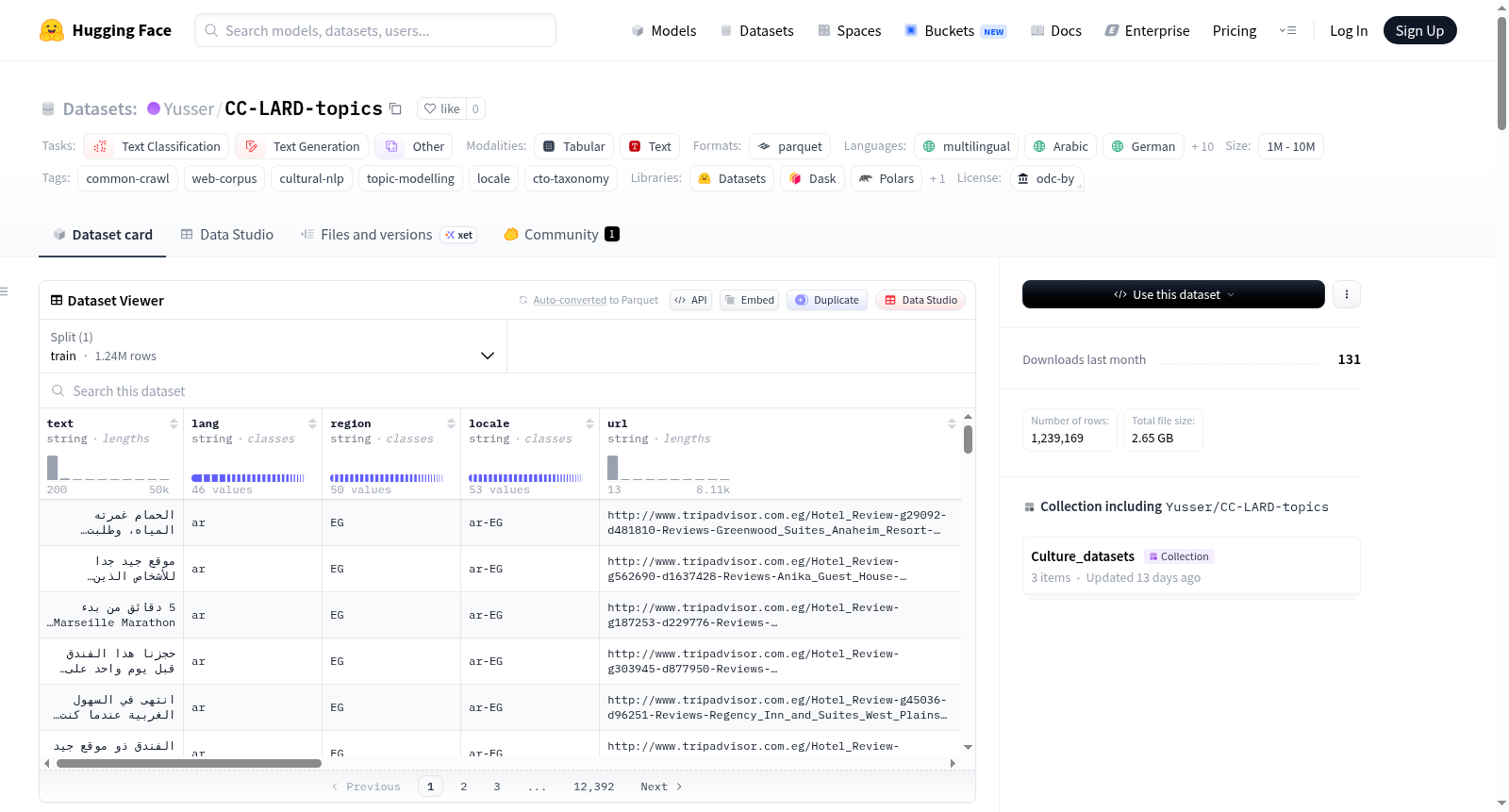
CC-LARD(Common Crawl Language and Region Dataset) 是一个多语言、多区域的大规模网络语料库,新增了文化主题分配(Cultural Topic Assignments)和CTO(Cultural Topic Ontology)叶节点对齐信息。本页面发布的是经过话题建模的子集,包含1,239,169个文档,涵盖53个经过话题建模的语言区域(locale)。
基本信息
- 许可证:ODC-By v1.0 + Common Crawl 使用条款
- 数据集大小:1,000,000 < 文档数 < 10,000,000
- 语言:阿拉伯语、德语、英语、西班牙语、法语、印地语、日语、韩语、葡萄牙语、俄语、土耳其语、中文等多种语言
- 标签:Common Crawl、网络语料、文化NLP、话题建模、区域、CTO分类体系
- 任务类别:文本分类、文本生成、其他
数据集规模统计
| 指标 | 数值 |
|---|---|
| 完整CC-LARD语料库文档数 | 13,150,911 |
| 语言数量 | 140 |
| 区域数量 | 4,334 |
| 地区数量 | 349 |
| 话题建模区域数量 | 53 |
| 本HuggingFace发布子集文档数 | 1,239,169 |
| 53个区域的FASTopic话题数 | 1,634 |
| 作为共享索引的CTO叶节点数 | 14 |
| Common Crawl快照数量 | 41 |
| 流水线保留率(28.1M → 13.15M) | 46.74% |
数据模式
数据以Parquet格式存储于 data/<locale>/train.parquet,包含以下字段:
| 列名 | 类型 | 描述 |
|---|---|---|
| text | string | 文档文本(提取后、质量过滤后、去重后) |
| lang | string | 检测语言代码(GlotLID,ISO-639-1/3) |
| region | string | 解析区域(ISO-3166-1 alpha-2,若为XX则为null) |
| locale | string | lang-REGION格式代码(如en-IN);未解析则为XX |
| url | string | 源URL |
| lang_confidence | float64 | GlotLID检测置信度(阈值≥0.65) |
| region_source | string | 区域解析来源(HTML lang标签/HTTP头/ccTLD等) |
| warc_date | string | WARC记录日期(快照时间戳) |
| text_length | int64 | 字符长度 |
| title | string | 文档标题(第一个标题或<title>) |
| text_hash | string | 提取后文本的SHA-256哈希(用于精确去重) |
| dominant_topic_id | int64 | 区域内FASTopic话题ID |
| dominant_topic_label | string | FASTopic话题的top-words标签 |
| dominant_topic_description | string | 大语言模型生成的话题描述 |
| dominant_topic_cto_category | string | 14个CTO叶节点之一(如L2_artifacts、L3_values_bias) |
| dominant_topic_probability | float64 | 主导话题的概率质量 |
| topic_distribution | list[float64] | 文档的完整FASTopic话题分布向量 |
构建流水线概述
- Common Crawl WARC → Trafilatura HTML提取(每个分片,128核并行)
- GlotLID v3语言识别(置信度≥0.65)
- 成人域名过滤
- 质量过滤(长度、样板内容、字母比例)
- 精确去重(SHA-256哈希)
- 近似去重(MinHash-LSH,Jaccard≥0.8)
- 长度过滤(≥200字符)
- Token计数过滤(≥20 token)
- 按语言区域分片(CC-LARD核心)
- 每个区域FASTopic建模(K ≈ 每100个文档1个话题,限制在30~500之间)
- GPT-4o裁决话题 → CTO叶节点映射
- 发布数据集:为53个高资源语言区域提供逐文档的CTO叶节点标签
推荐用途
- 语言区域感知语料库审计:分析不同语言区域中文化话题的代表性
- 构建文化评估的区域级基准
- 预训练数据分析:将CC-LARD与您的预训练语料库对比,识别文化盲点
- 跨区域公平性分析:诊断哪些区域出现在训练分布中但未出现在评估中
超出范围的使用
- 不应将CC-LARD视为任何区域文化内容的完整或无偏样本
- 不应将逐文档的CTO叶节点标签视为绝对真实(约31%的GPT-4o话题分配覆盖了嵌入先验,约8%被人工抽查标记为“不正确”)
- 不应将区域标签用作说话人群体的代理(例如
en-IN表示印度英语网络内容,而非印度英语使用者)
隐私与删除
尽管已过滤常见个人身份信息(电子邮件、公共IP、电话号码模式),仍可能残留个人信息。如需请求删除个人数据或匹配您URL的文档,请联系CC-LARD作者。
搜集汇总
数据集介绍
构建方式
CC-LARD-topics数据集源自Common Crawl的WARC存档,经由一套精心设计的级联流水线构建而成。首先,利用Trafilatura对原始网页进行HTML文本提取,并借助GlotLID v3进行语言识别,仅保留置信度不低于0.65的文档。随后,依次执行成人内容过滤、质量过滤(涵盖文本长度、样板化比例及字母比率)、基于SHA-256的精确去重以及基于MinHash-LSH且Jaccard相似度不低于0.8的近似去重。接着,通过长度与词元数量筛选(要求不少于200字符及20个词元),生成按语言-区域(locale)划分的核心语料。最后,对53个高资源locale分别应用FASTopic主题建模,并由GPT-4o将每个文档的支配性主题映射至14个CTO叶类别,从而赋予每篇文档精细的文化主题标注。
特点
该数据集的核心特色在于其多维度的语义标注结构与广泛的文化覆盖范围。包含约124万篇文档,跨越53个locale、14种主要语言及14个CTO叶类别,每个文档均携带有locale标签、语言代码、FASTopic主题及其概率分布、以及GPT-4o裁决的CTO分类。不同于常见的单一语言或地域语料,CC-LARD-topics致力于捕捉不同locale间的文化主题差异,为跨区域公平性分析与文化盲区诊断提供了精细化的分析单元。其标注体系融合了无监督主题建模与大语言模型的知识映射,既保留了语料的内在语义结构,又引入了人类可理解的分类框架,实现了规模与深度的平衡。
使用方法
推荐用于locale感知的语料审计,例如评估特定文化主题在不同locale中的表征偏倚;亦可用于构建locale级别的文化评估基线,或对预训练语料进行文化主题对比分析,以在模型训练前识别文化盲区。在读取上,数据集采用Parquet格式分locale存储,用户可通过HuggingFace Datasets库加载指定locale的`data/<locale>/train.parquet`文件,获得包括文本、语言、区域、主题标签及概率分布在内的完整字段。需要注意的是,CTO叶类别标签不宜被视为绝对真理,因GPT-4o约31%的分配结果与嵌入先验相悖,且人工抽检中约8%的标注被判定有误;同时,locale标签反映的是网络内容的地域性,而非实际语言使用者的社群构成。
背景与挑战
背景概述
CC-LARD-topics数据集诞生于大规模网络语料库与文化计算交汇的前沿领域,由匿名研究团队为NeurIPS 2026数据集与基准赛道所构建。该数据集聚焦于语言与区域(locale)维度下文化主题的分布建模,旨在解决当前多语言预训练语料库在文化多样性表征上的系统性盲区。通过从Common Crawl 41个快照中提取约1315万文档,覆盖140种语言和4334个区域,并利用FASTopic主题模型及GPT-4o标注形成14个CTO叶子节点的文化主题分类,该研究为跨文化自然语言处理提供了首个大规模、可复现的区域感知语料基准。其影响力体现在为训练数据审计、跨区域公平性分析以及文化评估基线的建立奠定了关键数据基础设施,成为连接网络文本原始语料与文化认知计算的重要桥梁。
当前挑战
该数据集所应对的核心挑战在于:其一,现有网络语料库如Common Crawl虽体量庞大,但缺乏细粒度区域与文化主题标注,导致多语言模型在非主流区域(如印度英语en-IN)的文化表征严重偏斜,且难以量化训练语料中不同文化概念的覆盖差异。其二,构建过程中需克服多源异构难题:从WARC文档中解析区域元数据需依赖HTML lang标签、HTTP头及ccTLD等多种信号,且约47%的文档因区域不可解析而被排除;主题建模面临跨区域主题对齐的语义鸿沟——FASTopic生成的1634个局部主题需经由GPT-4o映射至统一CTO索引,但人工抽检显示8%的映射被判定为错误。此外,成人内容过滤、质量筛选与去重管线导致原始数据保留率仅46.74%,需在数据规模与质量间达成精密权衡。
常用场景
经典使用场景
CC-LARD-topics数据集作为融合语言、地域与文化主题标注的大规模网络语料库,其经典使用场景聚焦于多语种与跨区域的文化主题建模与审计。研究者可依托该数据集中涵盖的53个主题建模地域、1634个FASTopic主题以及14个CTO叶节点分类体系,系统地剖析不同语言-地域组合中文化内容的分布偏斜与表征差异。例如,通过对比英文-印度(en-IN)与英文-美国(en-US)两个locale的CTO标签分布,可以揭示同一语言在不同文化区中的话题侧重与认知偏差。该数据集还常见于构建地域感知的语言模型预训练数据审计流程,以定量评估训练语料在文化维度上的覆盖充分性,从而为后续模型训练提供数据偏见的校正依据。
解决学术问题
该数据集在学术界主要回应了文化与自然语言处理交叉领域中的两大核心症结:其一是大规模网络语料中文化主题标注的系统性缺失,导致多语种模型在跨文化场景下表现欠佳且难以溯因;其二是现有基准测评通常忽略语言变体间的文化差异,掩盖了模型在非主流地域上的公平性问题。CC-LARD-topics通过构建从原始网页到文化主题叶节点的自动化标注流水线,为研究者提供了可复现的文化主题归因方案,使语料库审计从粗粒度的语言层面深入到细粒度的文化价值层面。其影响力体现在为后续跨文化NLP研究树立了数据层面的方法论典范,促进了文化意识评估框架的标准化发展。
衍生相关工作
基于CC-LARD-topics数据集的内涵与设计理念,衍生出一系列具有影响力的后续工作。在方法论层面,研究者借鉴其FASTopic + GPT-4o裁定文化标签的混合范式,提出了针对低资源语言的文化主题自动归因模型,进一步拓展了文化NLP的双语与多语研究边界。在基准测评方面,伴生的survey-culture-topics知识库汇集了175项文化感知基准的测评结果,成为衡量多语模型文化能力的事实标准。此外,多篇工作利用该数据集挖掘了模型在不同locale上的偏好差异,推动了对抗去偏训练、文化感知数据重采样等技术的成熟。这些衍生工作共同构筑了从数据构建、评估到模型改进的完备研究闭环。
以上内容由遇见数据集搜集并总结生成


