opencompass/anah
收藏Hugging Face2025-03-13 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/opencompass/anah
下载链接
链接失效反馈官方服务:
资源简介:
ANAH是一个双语数据集,专门用于在生成式问答中对大语言模型(LLMs)的幻觉进行注释。该数据集包含约12,000个句子级别的注释,覆盖了超过700个主题的约4,300个LLM回答。每个回答句子都经过了严格的注释,包括检索参考片段、判断幻觉类型和修正幻觉内容。数据集的组成部分包括主题名称、参考文档、选择的问题、GPT3.5和InternLM的回答,以及对这些回答的分析注释。
ANAH是一个双语数据集,专门用于在生成式问答中对大语言模型(LLMs)的幻觉进行注释。该数据集包含约12,000个句子级别的注释,覆盖了超过700个主题的约4,300个LLM回答。每个回答句子都经过了严格的注释,包括检索参考片段、判断幻觉类型和修正幻觉内容。数据集的组成部分包括主题名称、参考文档、选择的问题、GPT3.5和InternLM的回答,以及对这些回答的分析注释。
提供机构:
opencompass
原始信息汇总
ANAH: Analytical Annotation of Hallucinations in Large Language Models
简介
ANAH是一个双语数据集,专注于大型语言模型(LLMs)在生成式问答中的幻觉分析标注。
数据集特点
- 包含约12,000个句子级别的标注。
- 覆盖约4,300个LLM响应,涉及超过700个主题。
- 通过人机交互流程构建。
数据处理
- 每个答案句子都经过严格的标注过程,包括检索参考片段、判断幻觉类型及修正幻觉内容。
许可
本数据集采用Apache-2.0许可证。
搜集汇总
数据集介绍
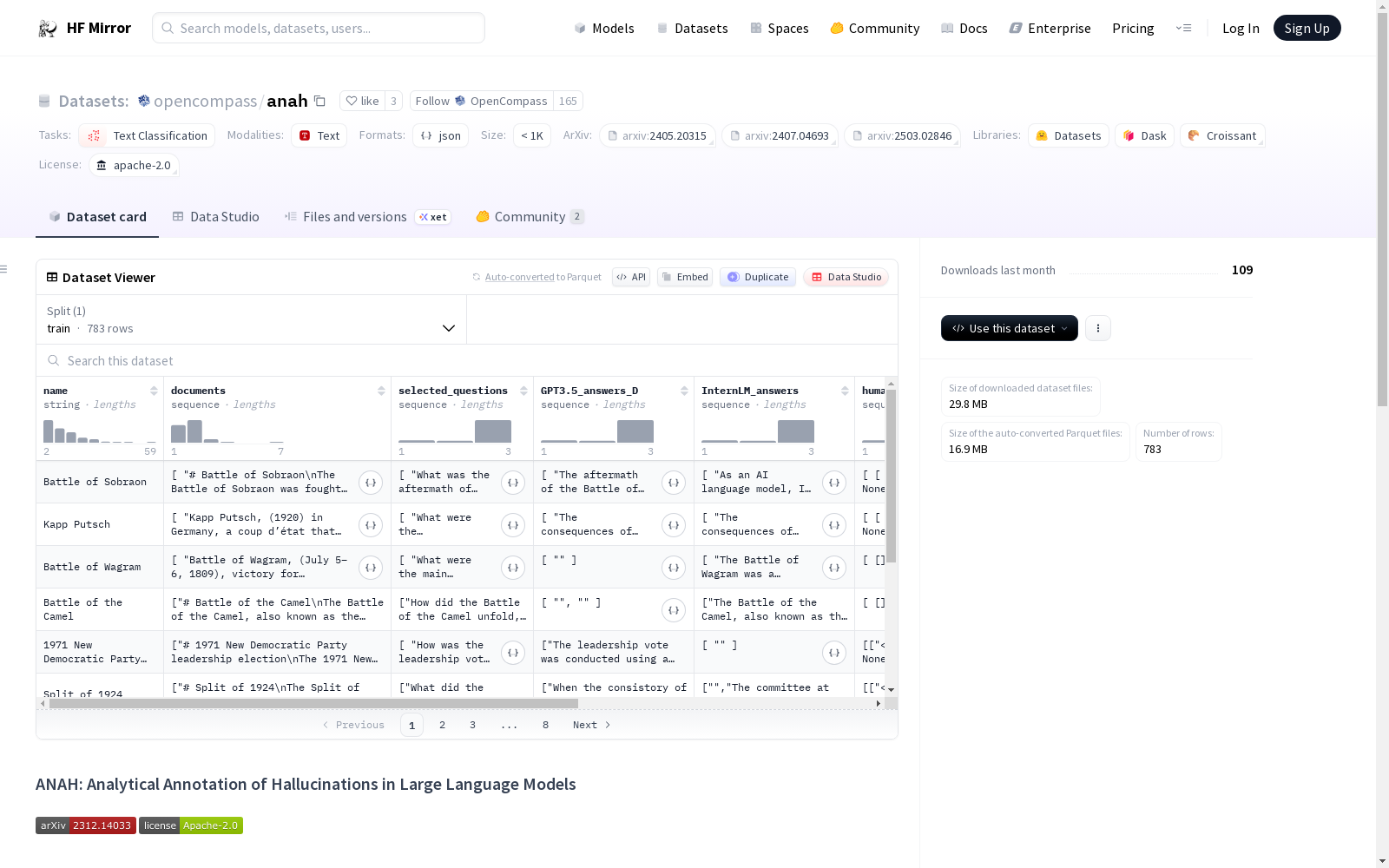
构建方式
在生成式问答领域,为深入探究大语言模型的幻觉现象,ANAH数据集采用人机协同的构建流程。该流程首先从超过700个主题中筛选出约4.3万条模型回答,进而对其中约1.2万条句子进行精细标注。每一句标注均包含检索相关参考片段、判定幻觉类型以及修正幻觉内容三个关键步骤,确保了标注的严谨性与分析深度。
特点
ANAH数据集的核心特点在于其双语属性与精细的分析性标注。它不仅覆盖了GPT-3.5与InternLM等主流模型的生成回答,更对每个回答句子提供了包含参考片段、幻觉类型及修正内容的结构化注释。这种设计使得数据集能够清晰揭示幻觉的具体形态与成因,为幻觉检测器的训练与事实性对齐研究提供了高质量、可解释的语料基础。
使用方法
研究者可利用ANAH数据集进行幻觉检测模型的训练与评估。具体而言,数据集中的‘human_GPT3.5_answers_D_ann’与‘human_InternLM_answers_ann’字段提供了详尽的标注信息,可直接作为监督信号。同时,其结构化的参考文档、问题及模型回答,支持构建多样化的提示工程或用于相关任务的微调实践,如遵循ANAH-v2与Mask-DPO等论文所提出的方法。
背景与挑战
背景概述
在大型语言模型(LLM)迅速发展的背景下,模型生成内容中的幻觉问题日益凸显,成为制约其可靠应用的关键瓶颈。为系统性地解析和标注LLM在生成式问答中产生的幻觉,研究团队于2024年提出了ANAH数据集。该数据集由上海人工智能实验室等机构的研究人员构建,核心研究问题聚焦于对模型输出进行细粒度的幻觉分析与校正。通过提供超过1.2万个句子级标注,覆盖700余个主题,ANAH为幻觉检测器的训练与事实对齐研究提供了重要支撑,显著推进了自然语言处理领域对模型可信生成能力的深入探索。
当前挑战
ANAH数据集致力于应对生成式问答中LLM幻觉的精准识别与分类挑战,其核心在于区分事实性错误、无关生成及逻辑矛盾等多种幻觉类型。在构建过程中,研究团队面临多重困难:首先,确保标注的严谨性与一致性要求设计复杂的人机协同流程,以平衡效率与质量;其次,为每个回答句子检索准确的参考片段并执行校正,需处理大规模多源文档的语义对齐问题;此外,构建覆盖广泛主题的双语标注数据,对领域知识的深度与标注资源的协调提出了较高要求。
常用场景
经典使用场景
在自然语言处理领域,幻觉检测是评估大语言模型生成内容真实性的核心挑战。ANAH数据集通过提供双语、句子级别的幻觉标注,成为训练幻觉检测器的经典资源。研究者利用其精细的参考片段、幻觉类型判断及修正内容,能够系统地评估模型在生成式问答中的事实一致性,为模型的可信度研究奠定了数据基础。
解决学术问题
该数据集直接应对大语言模型中普遍存在的事实性幻觉问题,为学术研究提供了可量化的分析工具。通过标注幻觉的具体类型与修正,ANAH帮助研究者深入理解幻觉的产生机制,推动了事实性对齐、模型可信评估等方向的发展。其构建不仅填补了细粒度幻觉标注数据的空白,更促进了检测方法与对齐技术的创新,对提升模型生成内容的可靠性具有重要理论意义。
衍生相关工作
基于ANAH数据集,已衍生出多项经典研究工作。例如,ANAH-v2对其进行了扩展与优化,进一步提升了标注规模与质量;Mask-DPO则利用该数据探索了基于掩码的去偏对齐方法,有效减少了模型幻觉。这些工作不仅验证了数据集的实用价值,也推动了幻觉检测与对齐技术的前沿进展,为后续研究提供了重要的方法论参考。
以上内容由遇见数据集搜集并总结生成


