Harry-1234/IntentRouterTrain
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Harry-1234/IntentRouterTrain
下载链接
链接失效反馈官方服务:
资源简介:
---
license: bsd-3-clause
task_categories:
- text-generation
tags:
- agent
---
# MAOmni: A Self-Correcting Multi-Agent Omni-Modal Reasoning Framework For Affective and Intentional Analysis
<div style="display: flex; flex-wrap: wrap; align-items: center; gap: 5px;">
<a href="https://huggingface.co/Harry-1234/MAOmni" target="_blank"><img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue"></a>
<a href="https://huggingface.co/spaces/Harry-1234/MAOmni" target="_blank"><img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/open-in-hf-spaces-sm-dark.svg"></a>
<a href="https://github.com/eeee-sys/MAOmni" target="_blank"><img src="https://img.shields.io/badge/Project-Page-brightgreen"></a>
<a href="https://github.com/eeee-sys/MAOmni/blob/main/LICENSE" target="_blank"><img src="https://img.shields.io/badge/License-BSD--3--Clause-purple"></a>
</div>
**MAOmni** is a novel self-correcting multi-agent omni-modal framework endowed with deliberative reasoning capabilities. MAOmni decomposes the reasoning process through a dynamic cognitive workflow orchestrated by five specialized agents, a generative Retriever for global context distillation, an adaptive AKD Router Agent for dynamic reasoning routing, a GRPO Grounder for precise continuous-time spatio-temporal localization, Reasoning Agent for explicit structured logical inference, and a TTA Reviser for test-time adaptive self-correction via ephemeral LoRA tuning.
## 🔖 Model Details
- **Model type:** Omni-modal Large Language Model
- **License:** BSD-3-Clause
## 👀 MAOmni Overview
Understanding human intentions and social interaction contexts from complex, dynamic omni-modal streams is a fundamental yet challenging problem in artificial intelligence. Existing multi-modal large language models (MLLMs) typically rely on monolithic, black-box reasoning paradigms, making them highly susceptible to cognitive overload, shortcut learning, and hallucinated predictions when processing long-duration inputs. To address these limitations, we proposes MAOmni, a novel self-correcting multi-agent omni-modal framework endowed with deliberative reasoning capabilities. MAOmni decomposes the reasoning process through a dynamic cognitive workflow orchestrated by five specialized agents, a generative ELT Retriever Agent for global context distillation, an adaptive AKD Router Agent for dynamic reasoning routing, a GRPO Grounder for precise continuous-time spatio-temporal localization, OMLT Reasoner Agent for explicit structured logical inference, and a TTA Reviser for test-time adaptive self-correction via ephemeral LoRA tuning. Extensive experiments on three challenging benchmarks demonstrate the superiority of our framework. Notably, despite its compact 7B parameter scale, MAOmni achieves state-of-the-art results, consistently outperforming leading open-source models and surpassing several proprietary systems, including GPT-4o and Gemini-2.5-Pro.
<p align="center">
<img src="https://github.com/eeee-sys/MAOmni/blob/main/assets/method.png" width="100%" height="100%">
</p>
#### 🌟 Contributions in MAOmni
1. We propose MAOmni, a unified omni-modal reasoning framework that pioneers the application of multi-agent collaboration in the field of affective analysis. Our framework introduces dynamic strategy selection via a planning module, enabling the model to adaptively determine whether to perform temporal grounding or direct reasoning based on input complexity.
2. We introduce GRPO Grounder and TTA Reviser. We train the video locator implemented by the autoregressive method using the GRPO algorithm and fine-tune the reasoning module during testing using the test-time adaption and REINFORCE with Baseline algorithms. This method enables our framework to have sample-level answering capabilities.
3. MAOmni achieves state-of-the-art results across three Benchmarks: IntentBench, Daily-Omni, WorldSense. Notably, our approach surpasses a host of commercial closed-source and open-source models, including GPT-4o, Gemini-2.5-Pro (think). Extensive ablations further confirm its effectiveness.
## 💻 Code Repository
The code for MAOmni, including training and evaluation scripts, can be found on GitHub: [https://github.com/eeee-sys/MAOmni](https://github.com/eeee-sys/MAOmni)
## 📈 Experimental Results
#### 📍 Results
<p align="center">
<img src="assets/dailyomni.png" width="100%" height="100%">
</p>
<p align="center">
<img src="assets/worldsense.png" width="100%" height="100%">
</p>
<p align="center">
<img src="assets/intentbench.png" width="100%" height="100%">
</p>
## 🚀 Quick Start
### Install the environment
1. Clone the repository from GitHub.
```shell
git clone git@github.com:eeee-sys/MAOmni.git
cd MAOmni
```
2. Initialize conda environment.
```shell
conda create -n grpo_grounder python=3.11 -y
conda activate grpo_grounder
pip install -r src/requirements_grpo_grounder.txt
```
```shell
conda create -n maomni_main python=3.10 -y
conda activate maomni_main
pip install -r src/requirements_main.txt
```
### Quick Inference Demo
The script below showcases how to perform inference with MAOmni's different roles. Please refer to our [GitHub Repository](https://github.com/eeee-sys/MAOmni) for more details about this framework.
```python
import torch
from transformers import (
Qwen2_5OmniForConditionalGeneration,
Qwen2_5OmniThinkerForConditionalGeneration,
Qwen2_5OmniProcessor,
)
from peft import LoraConfig, get_peft_model, PeftModel
from qwen_omni_utils import process_mm_info
# ============================================================
# Main Process
# ============================================================
def main():
# ---- Initialize Models ----
print(f"\n[INIT] Loading Base Model ({args.base_model_path}) on {args.main_gpu}")
base_model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
args.base_model_path, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
).to(args.main_gpu)
base_processor = Qwen2_5OmniProcessor.from_pretrained(args.base_model_path)
# Load Planner LoRA onto thinker submodule
print(f"[INIT] Loading Planner LoRA onto base_model.thinker")
base_model.thinker.load_adapter(args.planner_lora_path, adapter_name="planner")
base_model.eval()
print(f"[INIT] Loading HumanOmniV2 ({args.humanomni_path}) on {args.humanomni_gpu}")
humanomni_model = Qwen2_5OmniThinkerForConditionalGeneration.from_pretrained(
args.humanomni_path, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
).to(args.humanomni_gpu)
humanomni_processor = Qwen2_5OmniProcessor.from_pretrained(args.humanomni_path)
lora_config = LoraConfig(
r=64, lora_alpha=128,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05, bias="none", task_type="CAUSAL_LM"
)
humanomni_model = get_peft_model(humanomni_model, lora_config, adapter_name="initial_dummy")
humanomni_model.enable_input_require_grads()
humanomni_model.gradient_checkpointing_enable()
print(f"[INIT] Starting Grounder process on {args.grounder_gpu}...")
grounder_script = os.path.join(SCRIPT_DIR, "grounder_worker_grpo.py")
grounder_env = os.environ.copy()
grounder_env["CUDA_VISIBLE_DEVICES"] = args.grounder_gpu.replace("cuda:", "")
grounder_proc = subprocess.Popen([
args.grounder_python, grounder_script,
"--model_path", args.grounder_path,
"--grpo_adapter_path", args.grpo_adapter_path,
"--device", "cuda:0"
], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=None, text=True, bufsize=1,
env=grounder_env)
ready_line = grounder_proc.stdout.readline().strip()
if not ready_line or json.loads(ready_line).get("status") != "ready":
print("[ERROR] Grounder worker failed to start.")
sys.exit(1)
print("[INIT] All models ready!")
os.makedirs(args.lora_save_dir, exist_ok=True)
tmp_dir = tempfile.mkdtemp(prefix="idea3_reviser7b_")
# ---- 3. Loop through dataset ----
for sample in samples_to_process:
try:
# ====== PLANNER STAGE ======
# a) Collector Phase (LoRA disabled)
base_model.thinker.set_adapter("planner") # Ensure adapter is active before disabling
base_model.thinker.disable_adapters()
collector_text = stage1_collector(base_model.thinker, base_processor, video_path, query, args.main_gpu)
print(f"[Collector output] {collector_text}")
# b) Planner Phase (LoRA enabled)
base_model.thinker.enable_adapters()
(use_grounder, gnd_query), planner_raw = stage2_planner(base_model.thinker, base_processor, video_path, query, collector_text, args.main_gpu)
print(f"[Planner output] {planner_raw}")
print(f"[Planner] Use Grounder: {use_grounder} | query: {gnd_query}")
# ====== GROUNDER STAGE ======
generation_video = video_path
grounded_span = None
if use_grounder:
pred_spans, success = stage3_grounder(grounder_proc, video_path, gnd_query or query, duration)
print(f"[Grounder output] {pred_spans}")
grounded_span = pred_spans[0]
trim_path = os.path.join(tmp_dir, f"trim_{dataset_id}.mp4")
trim_video_ffmpeg(video_path, grounded_span[0], grounded_span[1], trim_path)
generation_video = trim_path
print(f"[Grounder] Grounded to {grounded_span[0]:.1f}s - {grounded_span[1]:.1f}s")
# ====== HUMANOMNI & REINFORCE STAGE ======
humanomni_query = build_humanomni_query(sample)
adapter_name = f"sample_{dataset_id}".replace(".", "_")
humanomni_model.add_adapter(adapter_name, lora_config)
humanomni_model.set_adapter(adapter_name)
# Ensure adapter parameters require gradients
for n, p in humanomni_model.named_parameters():
if adapter_name in n:
p.requires_grad = True
humanomni_model.train()
trainable_params = [
p for n, p in humanomni_model.named_parameters()
if p.requires_grad and adapter_name in n
]
optimizer = torch.optim.AdamW(trainable_params, lr=args.lr)
b = args.b0
best_score = -1
best_answer = ""
best_raw_resp = ""
all_history = []
early_stop = False
for t in range(1, args.t_max + 1):
gc.collect(); torch.cuda.empty_cache()
humanomni_model.eval()
inputs = get_humanomni_inputs(humanomni_processor, generation_video, humanomni_query, sample, args.humanomni_gpu)
with torch.no_grad():
output_ids = humanomni_model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.85)
generated_sequence = output_ids[0][inputs.input_ids.size(1):]
y_t_text = humanomni_processor.decode(generated_sequence, skip_special_tokens=True)
print(f" [Iter {t}/{args.t_max}] Answer = {y_t_text}")
base_model.thinker.disable_adapters()
score_t, reviser_raw = revise_answer(base_model.thinker, base_processor, video_path, query, y_t_text, args.main_gpu)
all_history.append({"iter": t, "answer": y_t_text, "score": score_t, "reviser_raw": reviser_raw})
# --- RL Update (REINFORCE) ---
humanomni_model.train()
optimizer.zero_grad()
advantage = float(score_t - b)
advantage_tensor = torch.tensor([advantage], device=args.humanomni_gpu, dtype=torch.bfloat16)
outputs = humanomni_model(**forward_kwargs)
nll_loss = outputs.loss
final_loss = nll_loss * advantage_tensor.detach()
final_loss.backward()
optimizer.step()
b = args.alpha * b + (1.0 - args.alpha) * score_t
提供机构:
Harry-1234
搜集汇总
数据集介绍
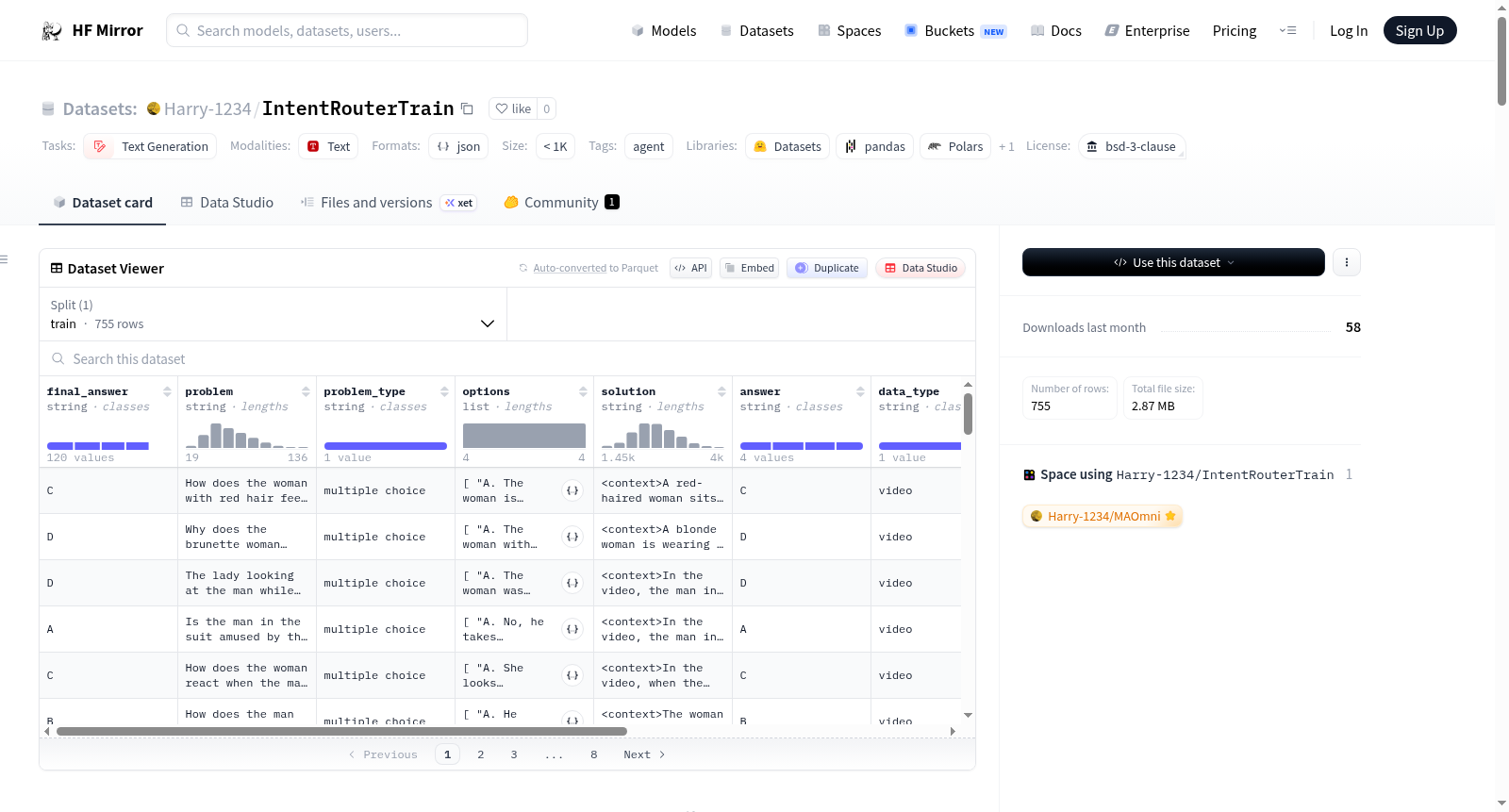
构建方式
在情感与意图分析这一前沿领域,构建能够支撑多智能体协同推理的数据集至关重要。IntentRouterTrain数据集作为MAOmni框架的核心训练资源,其构建过程紧密围绕多模态意图理解任务展开。该数据集通过整合来自视频、文本等多种模态的复杂交互数据,并利用动态认知工作流进行结构化标注。具体而言,数据收集涵盖了多样化的社会互动场景,随后由专家依据框架内各智能体的专业角色——如路由、定位与推理——对原始数据进行精细的标注与划分,确保了数据与多智能体分工协作的训练目标高度对齐。
特点
该数据集的核心特点在于其与MAOmni框架的高度适配性与任务的复杂性。数据集专门为训练自适应知识蒸馏路由智能体而设计,其样本天然蕴含了需要动态决策路径的意图分析挑战。数据呈现多模态融合特性,不仅包含时序视觉信息,还融合了丰富的语境文本,模拟了真实世界中人机交互的模糊性与连续性。此外,数据标注体系深度嵌入了框架的认知分解逻辑,使得模型能够从数据中学习到何时进行时空定位、何时进行直接推理等关键策略,为培养模型的审慎推理能力提供了坚实基础。
使用方法
为了有效利用该数据集训练MAOmni框架中的路由等智能体,需遵循其配套代码库定义的标准化流程。典型的使用方法始于环境配置与数据加载,需按照项目要求安装特定依赖并激活相应环境。在训练阶段,数据集被输入到由多个专门化模块组成的流水线中:生成式检索器首先对全局上下文进行提炼,随后自适应路由智能体根据输入复杂度动态选择推理路径。训练过程可能涉及对比学习或强化学习策略,以优化路由决策的准确性。用户可通过调用项目提供的训练脚本,指定数据集路径与模型参数,系统化地完成从数据预处理到模型评估的完整迭代。
背景与挑战
背景概述
在人工智能领域,从复杂动态的全模态流中解析人类意图与社会交互情境,是构建具备深度认知能力系统的核心议题。IntentRouterTrain数据集作为MAOmni框架的关键组成部分,由研究团队于近期开发,旨在支撑多智能体协作的意图与情感分析任务。该数据集紧密围绕全模态大语言模型在长序列输入下易产生的认知过载与幻觉预测等问题,通过结构化标注为自适应路由与逻辑推理提供训练基础,推动了意图理解与多模态推理技术的边界拓展。
当前挑战
该数据集致力于解决全模态意图理解与情感分析中的核心挑战,即如何从异构且时序交错的视频、文本与音频流中,精准抽离并关联用户的深层意图与情感状态。构建过程中的挑战主要体现在多模态数据的对齐与标注上,由于意图的隐含性与上下文依赖性,需要设计精细的标注体系以捕捉细微的语义差异与时空关联,同时确保数据规模与质量足以训练复杂的多智能体路由与修正机制。
常用场景
经典使用场景
在情感与意图分析领域,理解复杂动态多模态数据流中的人类意图与社会交互情境是核心挑战。IntentRouterTrain数据集作为MAOmni框架的关键训练资源,其经典应用场景在于为自适应知识蒸馏路由代理提供动态推理路径的标注数据。该数据集通过精心设计的意图分类与路由标签,使模型能够依据输入内容的复杂度,自主决策是否执行时序定位或直接推理,从而优化多智能体协作的认知工作流程。
衍生相关工作
围绕该数据集衍生的经典工作主要包括多智能体协作框架的优化与测试时自适应方法的创新。MAOmni框架本身便是其直接产物,其中GRPO Grounder与TTA Reviser等模块的设计深受数据集特性的启发。后续研究进一步探索了基于强化学习的动态路由策略、跨模态意图对齐技术,以及轻量级参数高效微调方法,这些工作共同推动了情感计算与意图理解领域向更高效、更稳健的方向发展。
数据集最近研究
最新研究方向
在情感与意图分析领域,多模态大语言模型正面临处理长时、复杂输入时认知过载与幻觉生成的挑战。针对此,基于IntentRouterTrain数据集的最新研究聚焦于自校正多智能体全模态推理框架的构建。该框架通过动态认知工作流协调五个专用智能体,实现了从全局上下文提炼到时空定位、结构化逻辑推理的分解式处理,并引入测试时自适应校正机制。这一方向显著提升了模型在意图理解与社会交互语境分析中的鲁棒性与精确度,在多项基准测试中超越了包括GPT-4o在内的现有领先模型,推动了具身智能与细粒度人机交互的前沿发展。
以上内容由遇见数据集搜集并总结生成


