cfilt/IITB-HGC
收藏Hugging Face2024-03-29 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/cfilt/IITB-HGC
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是作为EMNLP 2023论文《Eyes Show the Way: Modelling Gaze Behaviour for Hallucination Detection》的一部分发布的,包含了眼动追踪数据,用于检测幻觉现象。数据集由500个实例组成,每个实例包含claim-context对,以及注释者的注视持续时间、注视序列、注视单词、注视持续时间序列、注释者标签和真实标签。数据集格式为jsonl文件,每行可以加载为一个json对象。
该数据集是作为EMNLP 2023论文《Eyes Show the Way: Modelling Gaze Behaviour for Hallucination Detection》的一部分发布的,包含了眼动追踪数据,用于检测幻觉现象。数据集由500个实例组成,每个实例包含claim-context对,以及注释者的注视持续时间、注视序列、注视单词、注视持续时间序列、注释者标签和真实标签。数据集格式为jsonl文件,每行可以加载为一个json对象。
提供机构:
cfilt
原始信息汇总
数据集概述
数据集名称
- IITB-HGC
数据集来源
- 该数据集是作为EMNLP 2023论文《Eyes Show the Way: Modelling Gaze Behaviour for Hallucination Detection》的一部分发布的。
数据收集
- 数据集包含500个claim-context对,由5名注释者进行注释。
- 数据来源于FactCC数据集(Kryscinski et al., 2020)。
数据内容
- 每个实例包含注释者在claim和context文本上的注视持续时间及其相应标签。
数据格式
- 数据集格式为jsonl文件,每行可作为独立的json对象。
- 每个json对象包含以下字段:
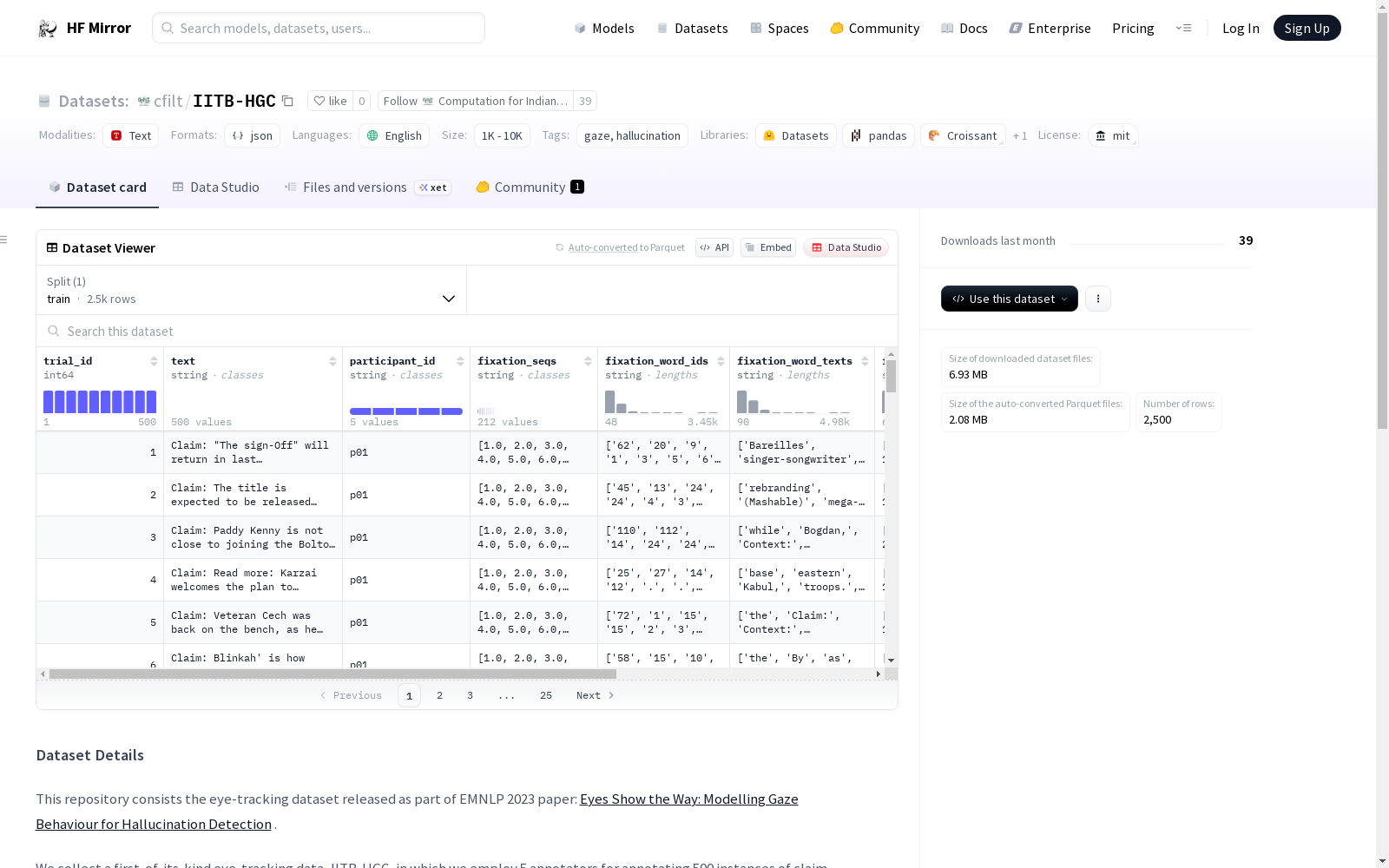
trial_id: 实例ID(1-500)text: 呈现给注释者的文本,采用claim:context格式participant_id: 参与者ID(p01, p02, p03, p04, p05)fixation_seqs: 注视序列IDfixation_word_ids: 注视单词ID序列fixation_word_texts: 注视单词文本序列fixation_durations: 注视持续时间序列(毫秒)annotator_labels: 注释者给出的标签(hallucinated/non_hallucinated)true_labels: FactCC数据集中的真实标签(hallucinated/non_hallucinated)
许可证
- MIT许可证
语言
- 英语
标签
- gaze, hallucination
搜集汇总
数据集介绍
构建方式
在信息检索与自然语言处理领域,IITB-HGC数据集的构建采用了精心挑选的5名标注者,对从FactCC数据集中衍生出的500个声明-上下文对进行标注。该过程记录了标注者在声明和上下文文本上的注视持续时间,以及相应的标注标签,旨在捕捉注视行为与幻觉检测之间的关联。
使用方法
使用IITB-HGC数据集时,研究者可以加载jsonlines文件中的每行作为json对象,访问包含注视行为和标注信息的字段。该数据集适用于眼动行为分析、自然语言处理模型训练和评估,特别是在幻觉检测任务中,有助于模型理解和模拟人类的阅读和判断过程。
背景与挑战
背景概述
在自然语言处理领域,对于文本生成任务,尤其是 hallucination(虚假信息生成)的检测,始终是一个关键的研究议题。cfilt/IITB-HGC 数据集在这样的背景下应运而生,由 IITB(印度理工学院孟买分校)的研究团队在 2023 年 EMNLP 会议论文中提出。该数据集的核心研究问题是如何通过分析标注者的眼动行为来检测文本中的虚假信息。数据集的构建基于 FactCC 数据集,通过五名标注者对 500 个声明-上下文对进行标注,记录了标注者在阅读声明和上下文时的注视时长及其对应的标签。该数据集的发布对于眼动行为建模在虚假信息检测中的应用具有重要意义。
当前挑战
cfilt/IITB-HGC 数据集在构建过程中面临了多重挑战。首先,如何精确捕捉并记录标注者的眼动行为是一个技术难题。其次,确保标注质量,尤其是在标注者对声明和上下文的注视时长及其标签的一致性上,需要严格的质量控制。此外,该数据集在解决虚假信息检测问题的挑战上,需要研究者开发出能够有效利用眼动数据特征的模型,这对于传统的文本处理方法而言是一个新的研究方向。
常用场景
经典使用场景
在自然语言处理领域, cfilt/IITB-HGC 数据集的应用尤为引人注目。该数据集主要用于模拟和研究人类在阅读过程中的注视行为,以检测文本中的虚假信息,即幻觉现象。其经典的使用场景在于,研究者可以利用该数据集训练机器学习模型,通过分析标注者的注视序列和持续时间,进而预测文本片段是否为幻觉内容。
解决学术问题
cfilt/IITB-HGC 数据集解决了学术研究中关于如何有效利用眼动数据来检测文本中幻觉现象的问题。在信息传播迅速的当下,准确识别和过滤幻觉内容显得尤为重要,该数据集的构建为这一领域的学术研究提供了可靠的实验基础,增强了模型在幻觉检测方面的准确性和可靠性。
实际应用
在实际应用中,cfilt/IITB-HGC 数据集可以被应用于新闻审核、社交媒体内容监控以及教育材料的事实核查等多个领域。通过深入分析眼动数据,可以辅助开发更为精准的自动审核系统,这对于维护网络环境的真实性和健康性具有显著意义。
数据集最近研究
最新研究方向
在自然语言处理领域,眼动追踪数据集IITB-HGC的发布,为虚假信息检测研究开辟了新的视角。该数据集由EMNLP 2023论文中提出,旨在通过分析标注者在处理声明与上下文对时的眼动行为,以识别虚假信息。通过精确捕获标注者对文本的注视时长及其标注结果,该数据集为模型训练提供了独特而丰富的特征集,有望推动模型在检测虚假信息,尤其是生成性虚假信息(hallucination)方面的性能提升。其研究成果不仅对于提升信息准确性有重要意义,亦为认知科学领域提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


