medagents-benchmark
收藏魔搭社区2025-11-18 更新2025-03-22 收录
下载链接:
https://modelscope.cn/datasets/AI-Bench/medagents-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
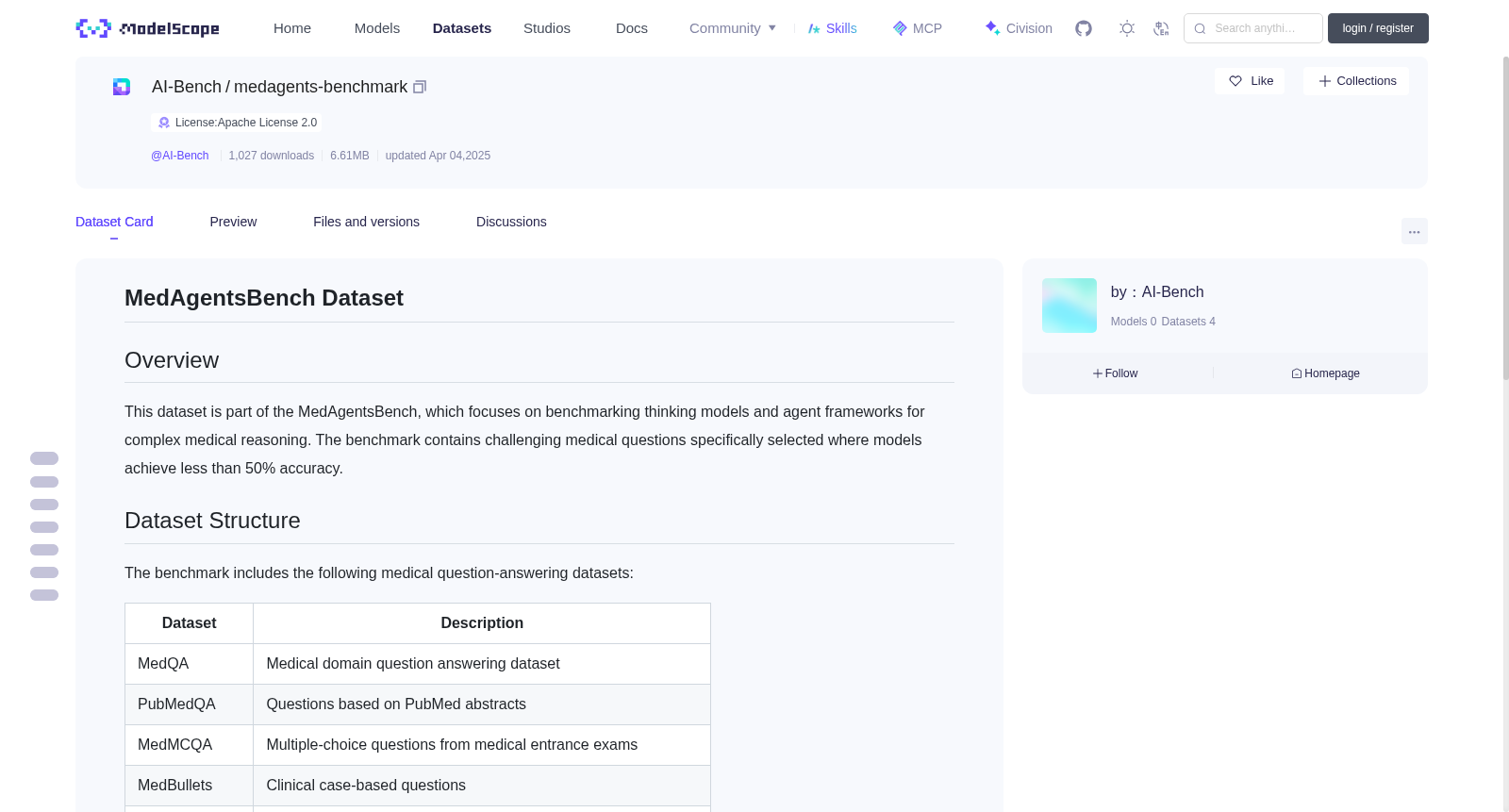
# MedAgentsBench Dataset
## Overview
This dataset is part of the MedAgentsBench, which focuses on benchmarking thinking models and agent frameworks for complex medical reasoning. The benchmark contains challenging medical questions specifically selected where models achieve less than 50% accuracy.
## Dataset Structure
The benchmark includes the following medical question-answering datasets:
| Dataset | Description |
|---------|-------------|
| MedQA | Medical domain question answering dataset |
| PubMedQA | Questions based on PubMed abstracts |
| MedMCQA | Multiple-choice questions from medical entrance exams |
| MedBullets | Clinical case-based questions |
| MMLU | Medical subset from Massive Multitask Language Understanding |
| MMLU-Pro | Advanced version of MMLU with more complex questions |
| AfrimedQA | Medical questions focused on African healthcare contexts |
| MedExQA | Expert-level medical questions |
| MedXpertQA-R | Medical expert reasoning questions |
| MedXpertQA-U | Medical expert understanding questions |
## Dataset Splits
Each dataset contains:
- `test_hard`: Specifically curated hard questions (accuracy <50%)
- `test`: Complete test set
## Citation
If you use this dataset in your research, please cite the MedAgentsBench paper:
```
@inproceedings{tang2025medagentsbench,
title={MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning},
author = {Tang, Xiangru and Shao, Daniel and Sohn, Jiwoong and Chen, Jiapeng and Zhang, Jiayi and Xiang, Jinyu and Wu, Fang and Zhao, Yilun and Wu, Chenglin and Shi, Wenqi and Cohan, Arman and Gerstein, Mark},
journal = {arXiv preprint arXiv:2503.07459},
year = {2025},
}
```
## License
Please refer to the repository for license information.
## Additional Information
For more details, visit the [MedAgentsBench repository](https://github.com/gersteinlab/medagents-benchmark) or the [paper](https://huggingface.co/papers/2503.07459).
# MedAgentsBench 数据集
## 概述
本数据集隶属于MedAgentsBench评测基准,该基准专注于针对复杂医疗推理场景下的思考模型与AI智能体框架开展性能评测。本基准收录了一系列极具挑战性的医疗问答问题,这些问题的现有模型准确率均低于50%。
## 数据集结构
该评测基准包含以下医疗问答数据集:
| 数据集 | 描述 |
|---------|-------------|
| MedQA | 医疗领域问答数据集 |
| PubMedQA | 基于PubMed摘要的问答问题 |
| MedMCQA | 源自医学入学考试的多项选择题 |
| MedBullets | 基于临床案例的问答问题 |
| MMLU | 源自大规模多任务语言理解(Massive Multitask Language Understanding)的医疗子数据集 |
| MMLU-Pro | MMLU的进阶版本,包含复杂度更高的问答问题 |
| AfrimedQA | 聚焦非洲医疗保健场景的医疗问答问题 |
| MedExQA | 专家级医疗问答问题 |
| MedXpertQA-R | 医疗专家推理类问答问题 |
| MedXpertQA-U | 医疗专家理解类问答问题 |
## 数据集划分
每个数据集均包含以下两个子集:
- `test_hard`:经过专门筛选的高难度问题(模型准确率低于50%)
- `test`:完整测试集
## 引用说明
若您在研究工作中使用本数据集,请引用以下MedAgentsBench论文:
@inproceedings{tang2025medagentsbench,
title={MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning},
author = {Tang, Xiangru and Shao, Daniel and Sohn, Jiwoong and Chen, Jiapeng and Zhang, Jiayi and Xiang, Jinyu and Wu, Fang and Zhao, Yilun and Wu, Chenglin and Shi, Wenqi and Cohan, Arman and Gerstein, Mark},
journal = {arXiv preprint arXiv:2503.07459},
year = {2025},
}
## 授权信息
请参阅代码仓库以获取详细的授权条款。
## 补充信息
如需了解更多详情,请访问[MedAgentsBench 代码仓库](https://github.com/gersteinlab/medagents-benchmark)或[相关论文](https://huggingface.co/papers/2503.07459).
提供机构:
maas
创建时间:
2025-03-19
搜集汇总
数据集介绍
背景与挑战
背景概述
MedAgentsBench是一个用于评估思维模型和智能体框架在复杂医学推理任务上的基准测试数据集。它整合了多个医学问答子集(如MedQA、PubMedQA等),并特别包含模型准确率低于50%的挑战性问题,旨在推动医学人工智能的推理能力研究。
以上内容由遇见数据集搜集并总结生成


