RuTaBERT-Dataset
收藏github2024-04-08 更新2024-05-31 收录
下载链接:
https://github.com/STI-Team/RuTaBERT-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
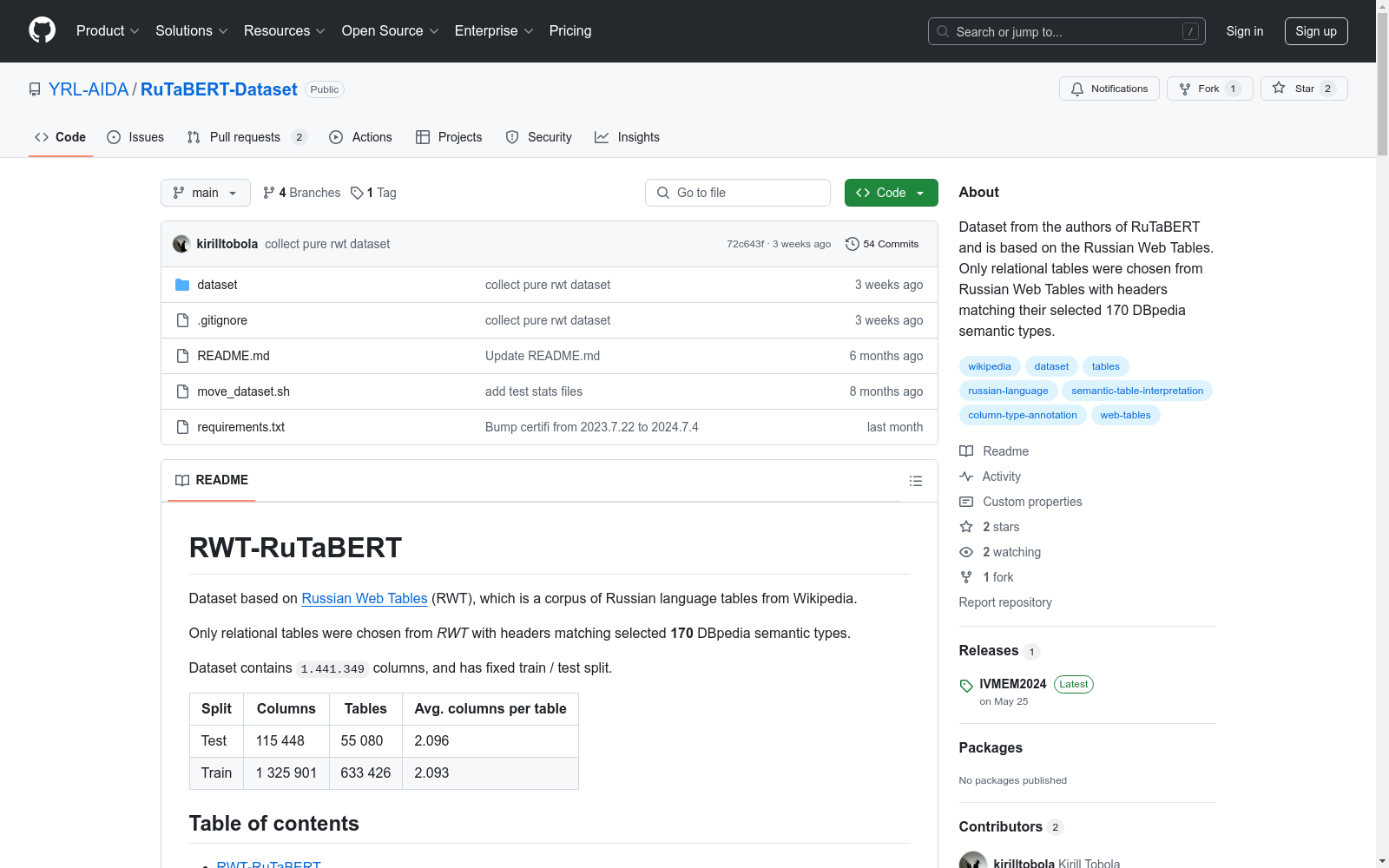
基于俄罗斯网络表格的数据集,专门选择了具有与170个DBpedia语义类型匹配标题的关系表。数据集包含1,441,349列,并设有固定的训练/测试分割。
This dataset is based on Russian web tables, specifically curated to include relational tables with titles matching 170 DBpedia semantic types. The dataset comprises 1,441,349 columns and features a fixed training/testing split.
创建时间:
2023-11-13
原始信息汇总
RWT-RuTaBERT 数据集概述
数据集来源与构成
- 来源:基于 Russian Web Tables (RWT),一个来自维基百科的俄语语言表格语料库。
- 构成:仅包含与170个DBpedia语义类型匹配头部的关系表。
数据集规模
- 总列数:1,441,349列。
- 训练/测试分割:
- 测试集:115,448列,55,080表,平均每表2.096列。
- 训练集:1,325,901列,633,426表,平均每表2.093列。
训练集统计
- 最频繁的列大小:
- 1列:257,890次
- 2列:172,414次
- 3列:124,635次
- 4列:54,886次
- 5列:18,532次
- 最不频繁的列大小:
- 19列:6次
- 40列:6次
- 16列:5次
- 38列:5次
- 最频繁的标签:
- год(年):230,016次
- название(名称):170,812次
- место(地点):103,986次
- дата(日期):97,228次
- 最不频繁的标签:
- континент(大陆):92次
- роман(小说):89次
- закон(法律):89次
- борец(摔跤手):88次
测试集统计
- 最频繁的列大小:
- 1列:22,491次
- 2列:14,923次
- 3列:10,798次
- 4列:4,801次
- 最不频繁的列大小:
- 13列:3次
- 36列:2次
- 20列:1次
- 16列:1次
- 最频繁的标签:
- год(年):19,854次
- название(名称):14,748次
- место(地点):9,004次
- дата(日期):8,408次
- 最不频繁的标签:
- цитата(引用):7次
- дорога(道路):6次
- статья(文章):6次
- фирма(公司):6次
搜集汇总
数据集介绍
构建方式
RuTaBERT-Dataset的构建基于[Russian Web Tables](https://arxiv.org/abs/2210.06353)语料库,该语料库包含从维基百科中提取的俄语表格数据。在构建过程中,仅选择了具有关系结构的表格,并且这些表格的表头与DBpedia的170种语义类型相匹配。数据集最终包含了1,441,349个列,并预先划分了训练集和测试集,确保了数据集的固定分割。
特点
RuTaBERT-Dataset的一个显著特点是其庞大的规模和多样性。数据集包含了超过140万列,涵盖了从最常见的列大小(如1列)到极为罕见的列大小(如19列)的广泛分布。此外,数据集中的标签也展示了显著的频率差异,最常见的标签如‘год’(年份)和‘название’(名称)出现的次数远高于较为罕见的标签如‘континент’(大陆)。这种频率分布为研究者提供了丰富的数据多样性,适用于多种自然语言处理任务。
使用方法
使用RuTaBERT-Dataset时,用户需要确保其计算环境满足特定的软件要求,包括C++编译器、Make工具、RapidJSON和Boost库。数据集的复现过程包括从原始数据集中提取列头、进行数据标注、收集列数据以及创建最终的训练和测试集。具体的操作步骤包括运行一系列的编译命令和Jupyter Notebook中的代码单元,以确保数据集的完整性和一致性。最终的训练和测试集将分别存储在指定的目录中,供用户进行进一步的分析和模型训练。
背景与挑战
背景概述
RuTaBERT-Dataset是基于[Russian Web Tables](https://arxiv.org/abs/2210.06353)语料库构建的数据集,该语料库包含从维基百科中提取的俄语表格数据。该数据集由研究人员精心挑选了170种DBpedia语义类型的关系表,旨在为俄语表格数据的语义分析提供丰富的资源。数据集包含了1,441,349列数据,并已固定了训练集和测试集的划分,分别包含1,325,901列和115,448列数据。该数据集的创建不仅为俄语自然语言处理领域提供了宝贵的资源,还为跨语言语义分析研究奠定了基础。
当前挑战
RuTaBERT-Dataset在构建过程中面临了多个挑战。首先,从庞大的俄语维基百科表格数据中筛选出符合170种DBpedia语义类型的关系表,这一过程需要精确的语义匹配和筛选算法。其次,数据集中存在大量稀有标签和列大小,如某些标签仅出现几次,这为模型训练带来了类别不平衡的问题。此外,数据集的构建涉及复杂的预处理步骤,包括表格数据的收集、列头的提取、标签的分配等,这些步骤对计算资源和算法效率提出了较高要求。最后,如何确保数据集在训练和测试集之间的分布一致性,也是一个重要的挑战。
常用场景
经典使用场景
RuTaBERT-Dataset的经典使用场景主要集中在自然语言处理领域,特别是针对俄语语义表的分析与理解。该数据集通过从维基百科中提取的俄语表格数据,结合DBpedia的170种语义类型,为研究人员提供了一个丰富的资源库,用于训练和测试表格数据的语义标注模型。其固定训练和测试集的划分,使得模型在处理表格数据时能够更好地捕捉语义信息,从而提升模型的准确性和鲁棒性。
实际应用
在实际应用中,RuTaBERT-Dataset为俄语表格数据的自动化处理提供了强大的支持。例如,在信息抽取、知识图谱构建和数据清洗等任务中,该数据集可以用于训练模型,从而自动识别和标注表格中的关键信息。此外,在企业数据管理和智能问答系统中,该数据集的应用能够显著提升数据处理的效率和准确性,为企业决策提供更加可靠的数据支持。
衍生相关工作
基于RuTaBERT-Dataset,许多相关工作得以展开,特别是在俄语表格数据的语义标注和分类任务中。例如,研究人员开发了多种基于深度学习的语义标注模型,这些模型在处理复杂表格数据时表现出色。此外,该数据集还激发了关于表格数据结构化表示和语义理解的研究,推动了自然语言处理技术在表格数据分析中的进一步发展。这些衍生工作不仅丰富了数据集的应用场景,也为相关领域的研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


