PROMPTEVALS
收藏arXiv2025-04-21 更新2025-04-23 收录
下载链接:
https://huggingface.co/datasets/reyavir/PromptEvals
下载链接
链接失效反馈官方服务:
资源简介:
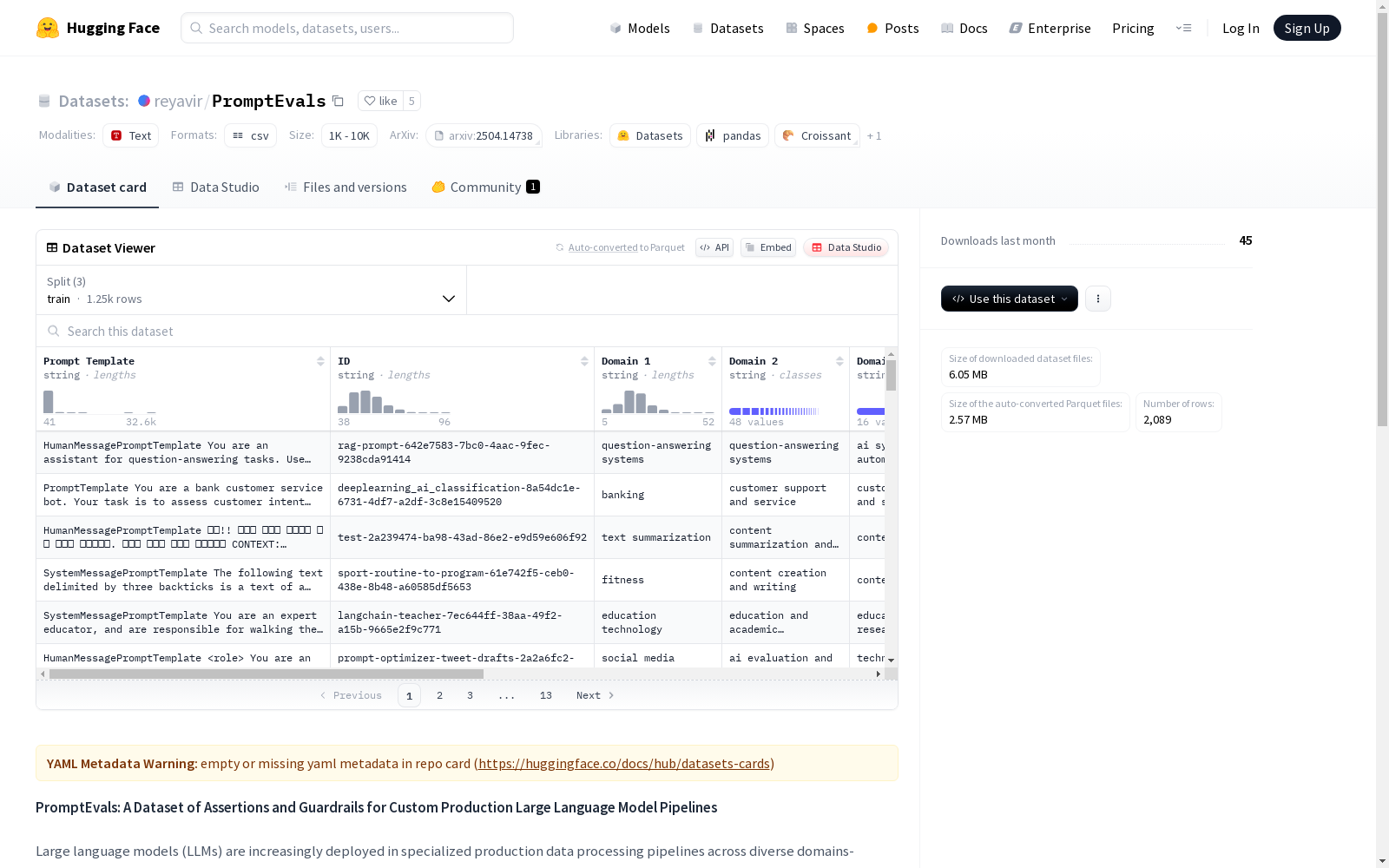
PROMPTEVALS是由加州大学伯克利分校的研究人员创建的一个数据集,包含了2087个针对定制生产大型语言模型管道的提示模板和12623条相应的断言标准。这些提示模板来源于开发者使用开源LLM管道工具所贡献,数据集规模比之前的集合大5倍。该数据集被用于评估封闭和开源模型在生成相关断言方面的性能,并进一步推进了LLM可靠性、对齐和提示工程的研究。
PROMPTEVALS is a dataset created by researchers at the University of California, Berkeley. It contains 2,087 prompt templates tailored for production-grade large language model (LLM) pipelines and 12,623 corresponding assertion criteria. These prompt templates were contributed by developers using open-source LLM pipeline tools, and the dataset is five times larger than prior collections. This dataset is used to evaluate the performance of both closed-source and open-source models in generating relevant assertions, and to further advance research on LLM reliability, alignment, and prompt engineering.
提供机构:
加州大学伯克利分校
创建时间:
2025-04-21
搜集汇总
数据集介绍
构建方式
PROMPTEVALS数据集的构建采用了多阶段流程,首先从LangChain Prompt Hub收集真实场景下的LLM提示模板,随后通过GPT-4o生成初始断言标准,再经过人工审核补充遗漏标准,最终通过模型精炼去除冗余条目。该流程结合了自动化生成与人工验证,确保每个提示模板对应6.29个经过分类学标注的断言标准,涵盖结构化输出、语义约束等10个类别。
特点
该数据集包含2087个跨领域提示模板及12623条断言标准,规模达同类数据集的5倍。其核心特征在于真实开发者场景的广泛覆盖性,涉及金融分析、医疗咨询等15个一级领域,其中通用聊天机器人(8.67%)和文本摘要(2.73%)占比显著。标准采用Liu等人提出的分类体系,结构化输出(23.7%)与指令遵循(18.5%)为高频约束类型,且38%的标准存在类型共现现象。
使用方法
数据集支持两种主要应用模式:作为基准测试时,可采用语义F1指标(基于text-embedding-3-large的余弦相似度)评估模型生成断言的相关性;用于模型微调时,建议采用LoRA方法在4096序列长度下训练4个epoch。配套发布的Mistral与Llama3微调模型在测试集上相较GPT-4o提升20.93%的F1值,适合集成至开发工具链实现实时断言生成。
背景与挑战
背景概述
PROMPTEVALS数据集由加州大学伯克利分校和LangChain的研究团队于2024年4月创建,旨在解决大型语言模型(LLM)在生产环境中的可靠性问题。该数据集包含2087个LLM流程提示和12623个对应的断言标准,覆盖金融、医疗、教育等多个领域,是目前同类数据集中规模最大的。其核心研究问题聚焦于如何通过自动化生成的断言标准来确保LLM输出符合开发者预期,从而提升生产环境中LLM应用的稳定性和可控性。该数据集通过开源工具收集真实场景下的开发者需求,为LLM对齐、可靠性研究和提示工程提供了重要基准。
当前挑战
PROMPTEVALS面临两大核心挑战:领域问题方面,需解决LLM输出与复杂业务约束(如金融报告格式、医疗术语准确性)的精准对齐问题,这对多轮交互和动态评估提出更高要求;构建过程方面,开发者需求的异构性导致断言标准定义困难(如同时满足结构化和语义约束),且人工标注12,623条标准存在主观性和规模化的双重压力。此外,数据集中15%的提示涉及模糊性要求(如'专业语气'),需要设计新型评估指标来量化这类主观标准。
常用场景
经典使用场景
PROMPTEVALS数据集在大型语言模型(LLM)的生产管道中扮演着关键角色,特别是在金融、营销和电子商务等多样化领域。该数据集通过提供大量开发者贡献的提示模板和相应的断言标准,帮助研究人员和工程师评估和改进LLM输出的可靠性。经典使用场景包括生成任务特定的断言标准,以确保LLM输出符合开发者的预期和指令。
解决学术问题
PROMPTEVALS解决了LLM在生成输出时未能遵循指令或满足开发者期望的常见问题。通过提供12623个断言标准,该数据集为研究LLM的可靠性、对齐性和提示工程提供了丰富资源。其意义在于填补了现有数据集的空白,推动了LLM在任务特定对齐和约束遵循方面的研究进展。
衍生相关工作
PROMPTEVALS衍生了一系列经典工作,包括基于该数据集微调的Mistral和Llama 3模型。这些模型在生成断言标准方面表现优异,平均性能超过GPT-4o约20.93%。此外,该数据集还促进了LLM可靠性、对齐性和提示工程领域的多项研究,为后续工作提供了重要基准。
以上内容由遇见数据集搜集并总结生成


