AVAGD (Audio-Visual Affordance Grounding Dataset)
收藏arXiv2025-12-02 更新2025-12-03 收录
下载链接:
https://jscslld.github.io/AVAGFormer/
下载链接
链接失效反馈官方服务:
资源简介:
AVAGD是由南京大学与中国移动通信有限公司研究院联合构建的首个音频-视觉可供性接地数据集,旨在通过动作声音分割物体交互区域。该数据集规模庞大,涵盖12,768张标注图像和5,203条音频片段,覆盖97种物体和55种可供性类别,数据源自ADE20K、Open Images等多个公开数据集,并辅以人工收集的YouTube音频。其创建过程采用半自动标注流程,结合Grounding DINO自动过滤与SAM2辅助的人工精细标注,确保了像素级分割掩码的质量。该数据集主要应用于增强现实与具身智能领域,致力于解决基于音频线索理解物体交互区域的细粒度多模态对齐问题,推动跨模态可供性感知研究的发展。
AVAGD is the first audio-visual affordance grounding dataset jointly constructed by Nanjing University and the Research Institute of China Mobile Communications Corporation, which aims to segment object interaction regions via action sounds. This large-scale dataset contains 12,768 annotated images and 5,203 audio clips, covering 97 object categories and 55 affordance classes. It is sourced from multiple public datasets such as ADE20K and Open Images, supplemented with manually collected YouTube audio. The dataset was built using a semi-automatic annotation pipeline, which combines automatic filtering via Grounding DINO and manually refined annotations assisted by SAM2 to guarantee the quality of pixel-level segmentation masks. It is mainly applied in the fields of augmented reality and embodied intelligence, dedicated to solving the fine-grained multimodal alignment problem of understanding object interaction regions based on audio cues, and promoting the development of cross-modal affordance perception research.
提供机构:
南京大学;中国移动通信有限公司研究院
创建时间:
2025-12-02
搜集汇总
数据集介绍
构建方式
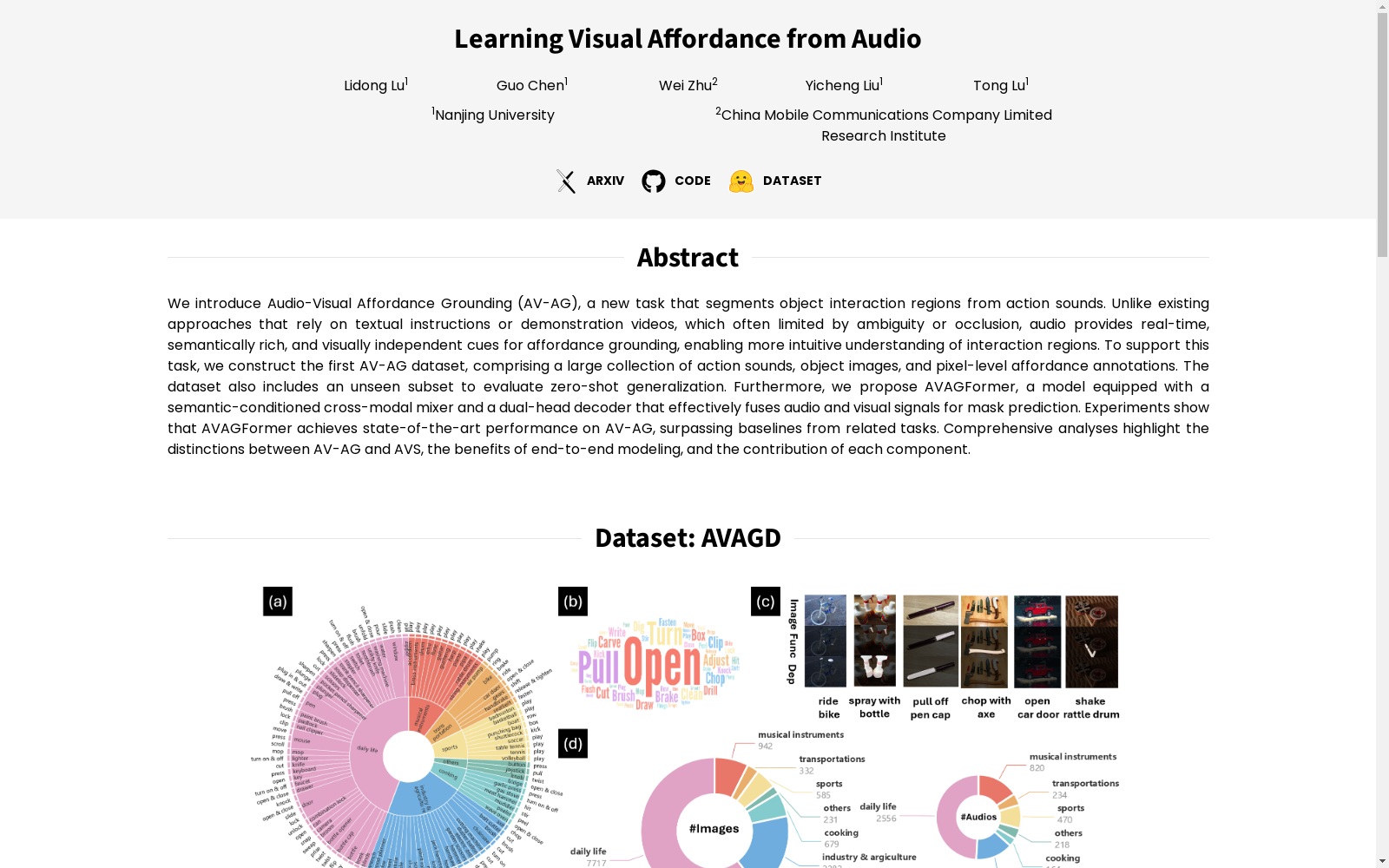
在构建AVAGD数据集的过程中,研究团队采用了系统化的半自动标注流程。图像数据主要来源于ADE20K、Open Images Dataset V7、Products-10K、Flickr以及METU-ALET等多个公开数据集,覆盖了乐器、烹饪、日常生活、工农业、体育和交通等六个领域。为了高效检索相关图像,团队利用Grounding DINO进行自动过滤和分类,随后通过人工验证确保类别准确性,并应用感知哈希技术去除重复样本。音频数据则通过以物体和功能类别为关键词在YouTube上手动搜索并精心裁剪而成,确保音频片段包含清晰的交互声音且人声干扰最小。最终,标注人员借助X-AnyLabeling工具和SAM2模型,为每张图像生成了像素级的功能区域与依赖区域分割掩码,形成了包含12,768张图像和5,203段音频的大规模多模态数据集。
特点
AVAGD数据集在可交互区域理解领域展现出鲜明的特色。其核心创新在于首次将听觉线索系统地引入可交互区域定位任务,提供了丰富的音频-视觉配对数据。数据集涵盖了97种物体类别和55种功能类别,具有前所未有的类别多样性,并包含了大量具有复杂背景的真实场景图像,有效缩小了与真实应用场景之间的领域差距。尤为重要的是,该数据集对可交互区域进行了细粒度划分,明确区分了直接完成动作的功能区域(如笔帽)和提供必要支持的依赖区域(如笔身),并提供了高质量的像素级分割标注。此外,数据集还专门设置了未见类别子集,为评估模型的零样本泛化能力提供了标准基准。
使用方法
AVAGD数据集主要用于支持音频-视觉可交互区域定位这一新型任务的研究与评估。在使用时,模型接收一张静态图像和一段动作音频作为输入,其核心目标是输出与音频语义对应的、图像中可交互区域的像素级分割掩码。数据集已预先划分为训练集、验证集和测试集,其中测试集包含未见过的物体-功能类别组合,专门用于测试模型的泛化性能。研究人员可以基于该数据集训练端到端的跨模态模型,例如论文中提出的AVAGFormer,该模型通过语义条件化的跨模态混合器和双头解码器来融合音频与视觉信号。评估通常采用平均交并比和F分数等分割指标,以量化模型在细粒度可交互区域分割上的准确性。
背景与挑战
背景概述
在增强现实与具身智能领域,准确识别物体可交互区域是实现智能体与环境有效互动的核心挑战。传统方法依赖文本指令或演示视频,常受限于语义模糊或视觉遮挡。为突破这一局限,南京大学等机构的研究团队于2025年提出了音频-视觉可供性定位任务,并构建了首个AVAGD数据集。该数据集涵盖97种物体与55种可供性类别,包含12,768张图像与5,203段音频,均标注了像素级分割掩码。通过引入听觉这一实时、语义丰富且独立于视觉的模态,AVAGD旨在推动多模态可供性理解,为具身智能系统在复杂场景中的环境感知提供更直观的基准。
当前挑战
AVAGD数据集旨在解决音频驱动的可供性定位问题,其核心挑战在于实现跨模态的细粒度语义对齐。具体而言,模型需从异步的音频与静态图像中,推断出与声音对应的物体部件级交互区域,而非仅仅定位发声物体。这要求模型深入理解物体功能与动作的因果关系,超越了现有音频-视觉分割任务的对象级定位能力。在构建过程中,数据收集与标注面临多重困难:需从多源图像库中筛选并验证复杂场景下的合适样本,同时手动从在线视频中裁剪高质量、无语音干扰的动作音频;此外,定义并标注功能区域与依赖区域这一双重掩码,对标注的一致性与精细度提出了极高要求。
常用场景
经典使用场景
在增强现实与具身智能领域,理解物体可交互区域是实现智能体与环境有效互动的核心挑战。AVAGD数据集通过引入音频线索,为研究者提供了探索视听融合的经典场景。该数据集常用于训练模型从动作声音中分割出物体上对应的功能区域与依赖区域,例如根据削皮声定位削皮器手柄,或依据按压声识别笔帽的按压部位。这种基于音频的交互区域定位,突破了传统文本或视频驱动方法的局限,为多模态感知研究开辟了新路径。
衍生相关工作
围绕AVAGD数据集,研究者已衍生出一系列经典工作,其中最具代表性的是论文同期提出的AVAGFormer模型。该模型设计了语义条件跨模态混合器与双头解码器,有效融合视听信号进行掩码预测,在数据集上取得了领先性能。此外,该任务也促使学界重新审视并改进现有的音频-视觉分割模型,如AVSegFormer、Selm和COMBO-AVS等,这些模型在适配AV-AG任务过程中,推动了跨模态注意力机制与细粒度分割解码器设计的演进,进一步丰富了多模态基础模型的研究生态。
数据集最近研究
最新研究方向
在具身智能与多模态感知领域,AVAGD数据集的推出标志着音频-视觉可承受性接地任务的前沿探索。该数据集突破了传统依赖文本指令或演示视频的局限,通过引入实时、语义丰富且视觉独立的音频线索,为物体交互区域的像素级分割提供了新颖的范式。当前研究聚焦于跨模态对齐机制的优化,如语义条件交叉混合器与双头解码器的设计,旨在深度融合音频与视觉信号,以提升模型在复杂场景下的零样本泛化能力。这一方向不仅推动了多模态基础模型在细粒度推理方面的发展,也为增强现实、机器人交互等应用场景提供了更为直观的环境理解工具,具有重要的理论与实用价值。
相关研究论文
- 1Learning Visual Affordance from Audio南京大学;中国移动通信有限公司研究院 · 2025年
以上内容由遇见数据集搜集并总结生成


