exp025_GPT54_high_postfix
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/HyeonSang/exp025_GPT54_high_postfix
下载链接
链接失效反馈官方服务:
资源简介:
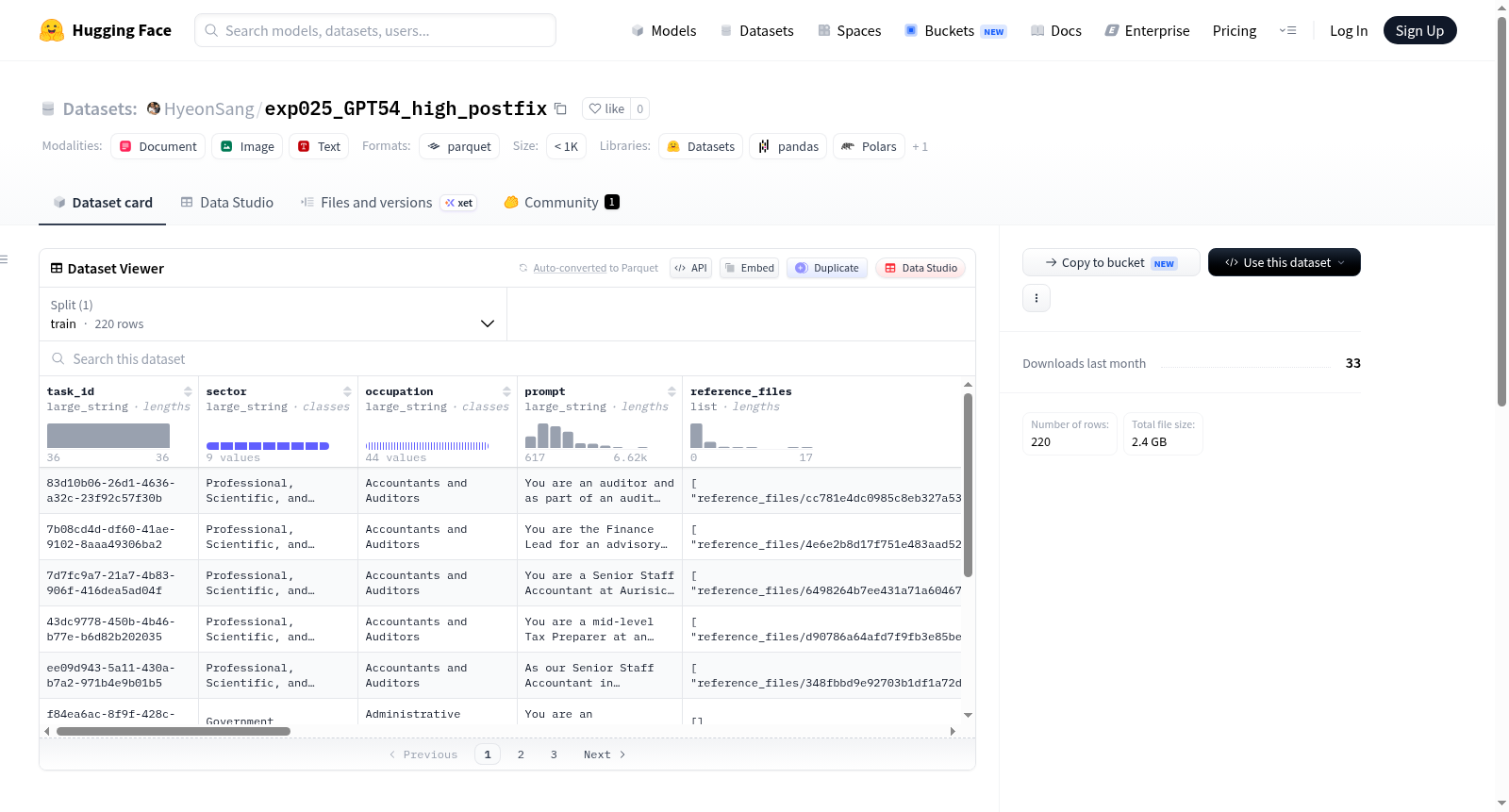
GDPval 是一个用于评估AI模型在现实世界具有经济价值任务上性能的数据集。它包含220个真实世界知识任务,覆盖44种不同职业,每个任务由一个文本提示和一组支持性参考文件构成。数据集的构建旨在反映实际职业场景中的多样化需求,包括可能涉及敏感内容(如性、酒精、粗俗语言和政治主题)的任务,这些内容被保留以体现真实职业主题。数据集包含对第三方品牌和商标的引用,仅用于研究和评估目的,不表示任何隶属或认可。其中部分图像和视频包含AI生成的人物或已获许可的真实人物,私人个体的姓名和识别信息均为虚构。该数据集适用于AI模型在复杂、多领域现实任务中的性能评估与基准测试。
GDPval is a dataset for evaluating the performance of AI models on real-world tasks with economic value. It contains 220 real-world knowledge tasks covering 44 different professions, each consisting of a text prompt and a set of supporting reference files. The dataset is designed to reflect the diverse demands of actual occupational scenarios, including tasks that may involve sensitive content (such as sex, alcohol, vulgar language, and political topics), which are retained to represent authentic professional themes. The dataset includes references to third-party brands and trademarks for research and evaluation purposes only, without implying any affiliation or endorsement. Some images and videos contain AI-generated individuals or licensed real individuals, and the names and identifying information of private individuals are fictional. This dataset is suitable for evaluating and benchmarking AI models on complex, multi-domain real-world tasks.
创建时间:
2026-05-17
原始信息汇总
数据集概述
数据集名称: exp025_GPT54_high_postfix
相关研究: 该数据集基于论文 GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks,旨在评估AI模型在真实世界具有经济价值的任务上的表现。
数据集组成与规模:
- 包含 220个真实世界的知识任务,覆盖 44种职业。
- 每个任务由 一个文本提示(text prompt) 和 一组支持性参考文件(supporting reference files) 组成。
数据文件:
- 配置文件名称:
default - 数据文件路径:
data/train-*(训练集分割)
额外说明:
- 数据集包含敏感内容,如性、酒精、粗俗语言和政治主题,这些内容保留了职业任务中的真实反映。
- 数据集包含有限的第三方品牌和商标引用,仅用于研究和评估目的;所有商标归各自所有者所有。
- 部分图像和视频包含AI生成的个体以及获得许可的真实人物;数据集中对私人的姓名和识别性引用均为虚构。
搜集汇总
数据集介绍
构建方式
该数据集源自GDPval研究项目,旨在评估人工智能模型在真实世界高经济价值任务中的表现。其构建方式涵盖44种职业的220项知识密集型任务,每项任务均包含一段文本提示以及一组配套的参考文件。数据集的命名‘exp025_GPT54_high_postfix’暗示其可能基于GPT-4等模型生成或筛选,采用高后缀策略以突出任务的经济相关性。数据以单一默认配置存储,训练集分布在多个文件切片(train-*)中,便于分布式加载与处理。
使用方法
使用时,用户可通过HuggingFace Datasets库加载该数据集,指定配置名‘default’与数据路径‘data/train-*’。每项任务需结合文本提示与参考文件共同输入模型,以模拟完整的工作场景。评估前需注意部分任务包含NSFW内容,研究者应提前审查并设置合适的内容过滤机制。数据集专为基准测试设计,不适用于模型微调,其‘canary’字符串用于内部追踪,外部使用时应严格遵守学术引用规范及第三方权利声明。
背景与挑战
背景概述
exp025_GPT54_high_postfix 数据集源于 OpenAI 发布的 GDPval 评估框架,旨在衡量人工智能模型在真实世界高经济价值任务上的表现。该数据集创建于 2025 年,由 OpenAI 研究团队主导开发,围绕 44 种职业构建了 220 个真实知识任务,每个任务包含文本提示与配套参考文件。其核心研究问题在于超越传统基准测试,量化 AI 在涉及法律、金融、医疗等专业领域中的经济实用性。作为 AI 评估领域的重要里程碑,GDPval 数据集推动了从学术性能指标向实际经济影响评估的范式转变,为政策制定、产业部署和伦理讨论提供了实证基础。
当前挑战
该数据集面临的挑战首先体现在领域问题的复杂性上:真实经济任务往往需要模型整合多模态信息、处理模糊语境,并输出可操作建议,远超传统问答或分类任务。此外,任务涵盖的 44 种职业中涉及敏感内容(如性、酒精、政治主题),如何在保留生态效度的同时确保研究伦理成为构建时的核心难题。数据集构建过程中还面临第三方版权与隐私保护问题,尽管声明引用均为研究目的,但涉及品牌商标、AI 生成图像及真实人物信息时,需兼顾法律合规与数据代表性。最后,任务结果的经济价值量化缺乏统一标准,使得模型间对比评估充满不确定性。
常用场景
经典使用场景
在人工智能评估领域,GDPval数据集以其独特的真实世界经济价值任务设计而备受瞩目。该数据集包含了横跨44种职业的220项真实知识任务,每项任务均由文本提示和配套的参考文件构成。经典使用场景聚焦于评估AI模型在模拟实际职业工作流程中的表现,例如分析法律文件、撰写商业报告或处理影视剧本中的敏感内容。研究者通过此数据集能够系统性地测试模型在复杂、多模态信息处理中的鲁棒性与准确性,从而揭示其在高价值经济场景下的真实能力边界。
解决学术问题
GDPval数据集的出现有效填补了现有基准测试中缺乏经济价值导向任务的空白。传统评估指标多侧重学术性能,如准确率或F1分数,却忽视了模型在真实职业任务中的实际效用。该数据集通过引入跨领域、跨职业的多样化任务,帮助学术界深入探究AI模型在知识密集型与经济产出相关场景中的表现差异。其意义在于推动了从‘能否完成任务’到‘能否创造经济价值’的评价范式转变,为衡量人工智能对劳动力市场的潜在影响提供了量化工具,并引发了关于模型公平性、安全性及职业替代风险的跨学科讨论。
实际应用
在实际应用层面,GDPval数据集已被广泛用于企业级AI系统的能力审计与风险控制。例如,金融科技公司利用该数据集测试模型在风险评估报告撰写中的合规性,而法律科技平台则将其用于验证AI在法律文档分析中的专业水平。数据集中的NSFW内容也促使开发者优化内容审核模型,确保在影视、文学等创意产业中实现文化敏感性与生产高效性的平衡。此外,政府机构与咨询公司借助GDPval评估AI辅助决策系统在公共政策分析中的可靠性,从而推动技术落地的责任边界制定。
数据集最近研究
最新研究方向
基于真实世界经济价值任务的大语言模型评估体系正成为前沿焦点。GDPval数据集通过覆盖44个职业的220个具象化知识任务,首次将模型性能与经济产出价值直接挂钩,突破了传统静态基准测试的局限。其研究方向聚焦于评估AI在劳动力市场中的实际替代能力,特别是处理包含敏感内容(如政治、性等)的专业场景时的表现边界。该数据集引发的核心议题在于:模型能否在不依赖预设立场的条件下,准确完成具有经济意义的工作流程。这一探索不仅为AI商业化部署提供了可量化的可信基准,更推动社会重新思考生产力重塑进程中的人机协作范式,其长远影响将辐射至劳动经济学与人工智能伦理的交汇地带。
以上内容由遇见数据集搜集并总结生成


