SynthHuman
收藏arXiv2025-07-21 更新2025-07-23 收录
下载链接:
https://aka.ms/DAViD
下载链接
链接失效反馈官方服务:
资源简介:
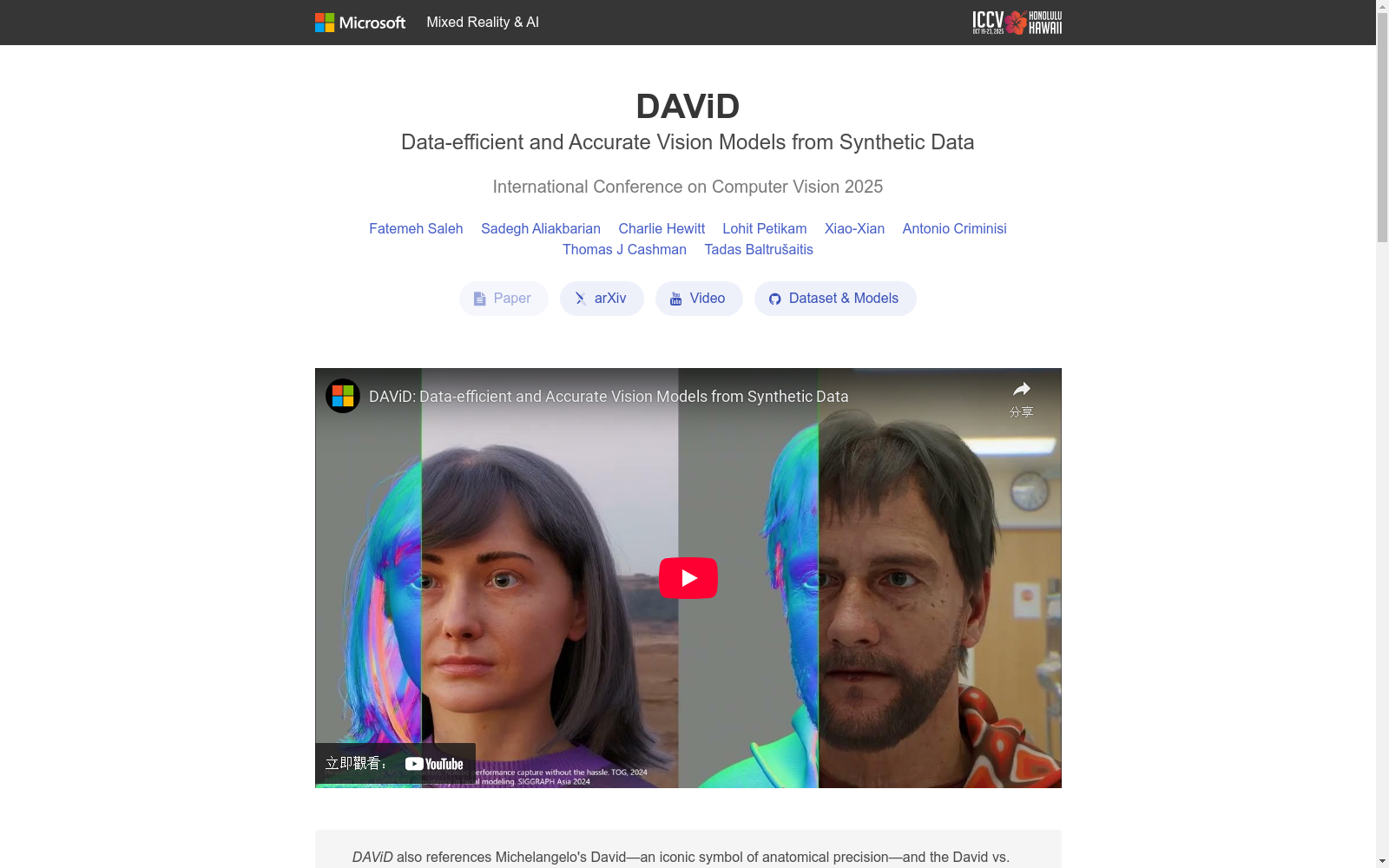
SynthHuman数据集是由微软剑桥团队创建的一个高保真合成数据集,旨在解决人本视觉任务中数据多样性和标注质量的问题。数据集包含30万张分辨率为384x512的图像,涵盖了人脸、上半身和全身场景,并提供了软前景掩码、表面法线和深度标注。该数据集在相对深度估计、表面法线估计和软前景分割等密集预测任务上取得了最先进的准确性,同时模型训练和推理的成本仅为类似精度的基础模型的很小一部分。
The SynthHuman dataset is a high-fidelity synthetic dataset developed by the Microsoft Cambridge Team, which aims to address the challenges of data diversity and annotation quality in human-centric visual tasks. It contains 300,000 images with a resolution of 384×512, covering facial, upper-body, and full-body scenarios, and provides soft foreground masks, surface normals, and depth annotations. This dataset achieves state-of-the-art accuracy on dense prediction tasks including relative depth estimation, surface normal estimation, and soft foreground segmentation, while the cost of model training and inference is only a small fraction of that of baseline models with comparable precision.
提供机构:
微软(Microsoft)
创建时间:
2025-07-21
原始信息汇总
DAViD 数据集概述
基本信息
- 数据集名称: DAViD (Data-efficient and Accurate Vision Models from Synthetic Data)
- 发布会议: International Conference on Computer Vision 2025
- 作者: Fatemeh Saleh, Sadegh Aliakbarian, Charlie Hewitt, Lohit Petikam, Xiao-Xian, Antonio Criminisi, Thomas J. Cashman, Tadas Baltrušaitis
- 相关资源: 论文 | arXiv | 视频 | 数据集与模型
数据集描述
- 数据来源: 完全使用合成数据训练模型
- 合成数据管道: 基于Hewitt等人的数据生成流程,结合Petikam等人的更新面部模型
- 数据集名称: SynthHuman
- 数据规模: 300K张图像
- 图像分辨率: 384×512
- 内容覆盖: 面部、上半身和全身场景,比例均等
- 多样性设计: 包含多样化的姿势、环境、光照和外观
- 标注信息: 每张图像包含软前景掩码、表面法线和深度真实标注
模型架构
- 基础架构: 密集预测变换器(DPT)的变体
- 特点:
- 支持可变输入分辨率
- 单一模型架构处理三个密集预测任务
- 多任务学习能力
性能表现
- 推理速度: 低至21毫秒/帧(在NVIDIA A100上的大型多任务模型)
- 任务表现:
- 深度估计
- 表面法线估计
- 软前景分割
- 优势:
- 高精度
- 高效训练和推理
- 良好的泛化能力
引用信息
bibtex @misc{saleh2025david, title={{DAViD}: Data-efficient and Accurate Vision Models from Synthetic Data}, author={Fatemeh Saleh and Sadegh Aliakbarian and Charlie Hewitt and Lohit Petikam and Xiao-Xian and Antonio Criminisi and Thomas J. Cashman and Tadas Baltrušaitis}, year={2025}, eprint={2507.15365}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2507.15365}, }
机构信息
- 研究机构: Mixed Reality & AI Lab - Cambridge
- 版权信息: © Microsoft 2025
搜集汇总
数据集介绍
构建方式
SynthHuman数据集通过程序化合成方法构建,采用高保真3D渲染技术生成多样化的人类图像。该数据集包含30万张分辨率384×512的图像,涵盖面部、上半身和全身场景。每张图像均附带精确的软前景掩码、表面法线和深度标注。数据生成流程基于Hewitt等人提出的方法,结合了Petikam等人更新的面部模型,确保生成的图像具有高度的真实性和细节表现。数据集在300台配备M60 GPU的机器集群上耗时72小时完成渲染,确保了数据的高质量和多样性。
特点
SynthHuman数据集以其高保真标注和多样性著称。与传统的扫描合成数据相比,该数据集通过程序化生成避免了扫描技术的局限性,能够精确捕捉头发、眼镜和衣物褶皱等细节。数据集在标注质量上具有显著优势,提供了像素级完美的深度、法线和前景分割标注。此外,数据集在姿态、环境、光照和外观方面具有高度多样性,不针对任何特定评估集进行优化,从而确保了模型的泛化能力。
使用方法
SynthHuman数据集支持多种密集预测任务,包括深度估计、表面法线估计和软前景分割。使用时,研究人员可以采用统一的模型架构(如基于ViT的DPT架构)进行多任务学习。数据集适用于零样本跨数据集评估,能够直接在真实图像上验证模型性能。对于特定任务,用户可通过调整输出通道数和损失函数(如使用余弦相似度损失进行表面法线估计)来优化模型。数据集的合成特性还确保了在隐私、版权和多样性方面的合规性。
背景与挑战
背景概述
SynthHuman数据集由微软剑桥研究院的研究团队于2025年提出,旨在解决人本计算机视觉领域中高精度密集预测任务的训练数据瓶颈问题。该数据集通过程序化合成技术生成30万张高保真人体图像,包含像素级精确标注的深度图、表面法线图和前景分割图。作为DAViD项目的核心组成部分,SynthHuman突破了传统真实数据采集在标注质量、隐私合规和数据多样性方面的限制,其创新性体现在三个方面:采用影视级渲染管线实现亚毫米级几何细节还原;通过艺术资产库构建覆盖3572种体型、548种发型的多样性样本;建立透明物体与毛发的特殊标注规范。该数据集推动了从数据驱动到合成驱动的研究范式转变,相关成果在CVPR等顶会论文中显示,其训练模型在深度估计等任务上以16倍效率优势达到SOTA性能。
当前挑战
SynthHuman面临的挑战主要体现在两个维度:在领域问题层面,需解决真实场景中复杂人体几何的精确建模,包括头发丝、眼镜反光等高频细节的捕捉,以及极端光照条件下表面法线的准确预测。数据集构建过程中,研究团队需攻克三大技术难题:首先是毛发标注的保真度问题,传统体素化方法导致法线图出现锯齿噪声,需设计基于代理网格的渐进式法线映射算法;其次是透明材质的标注歧义,需建立双通道标注规范分别记录介质表面与背景深度;最后是数据多样性与计算成本的平衡,采用分块渲染策略在300台M60 GPU集群上完成72小时分布式渲染。这些挑战的突破为合成数据在密集预测任务中的应用建立了新的技术标准。
常用场景
经典使用场景
在计算机视觉领域,SynthHuman数据集以其高保真合成数据特性,成为训练人像深度估计、表面法线预测和前景分割模型的理想选择。该数据集通过程序化生成技术,为研究者提供了像素级精确标注的多样化人像样本,涵盖不同姿态、光照条件和环境背景,为模型训练提供了丰富且可控的数据源。
解决学术问题
SynthHuman有效解决了真实数据标注成本高昂且精度受限的学术难题。传统方法依赖复杂相机阵列或专业传感器获取的带噪声真实数据,而该数据集通过合成技术完美标注了深度、法线和前景等密集预测任务所需的真值,显著提升了模型在细粒度特征(如发丝、眼镜反光)上的预测精度,同时规避了数据隐私和版权问题。
衍生相关工作
SynthHuman启发了多项前沿研究,包括BEDLAM全身动作合成数据集和DAViD多任务学习框架。其数据生成范式被Depth Anything v2采用作为教师模型训练源,而Sapiens等基础模型通过引入该数据集的合成样本显著提升了细粒度预测能力。这些衍生工作共同推动了合成数据在计算机视觉领域的标准化进程。
以上内容由遇见数据集搜集并总结生成


