有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
情感分类:
情感分析和问答:
新闻标题分类:
命名实体识别:
结构边界检测:
corpus 文件: .jsonl 格式,包含文档标识符、标题和文本。queries 文件: .jsonl 格式,包含查询标识符和查询文本。qrels 文件: .tsv 格式,包含查询ID、文档ID和分数。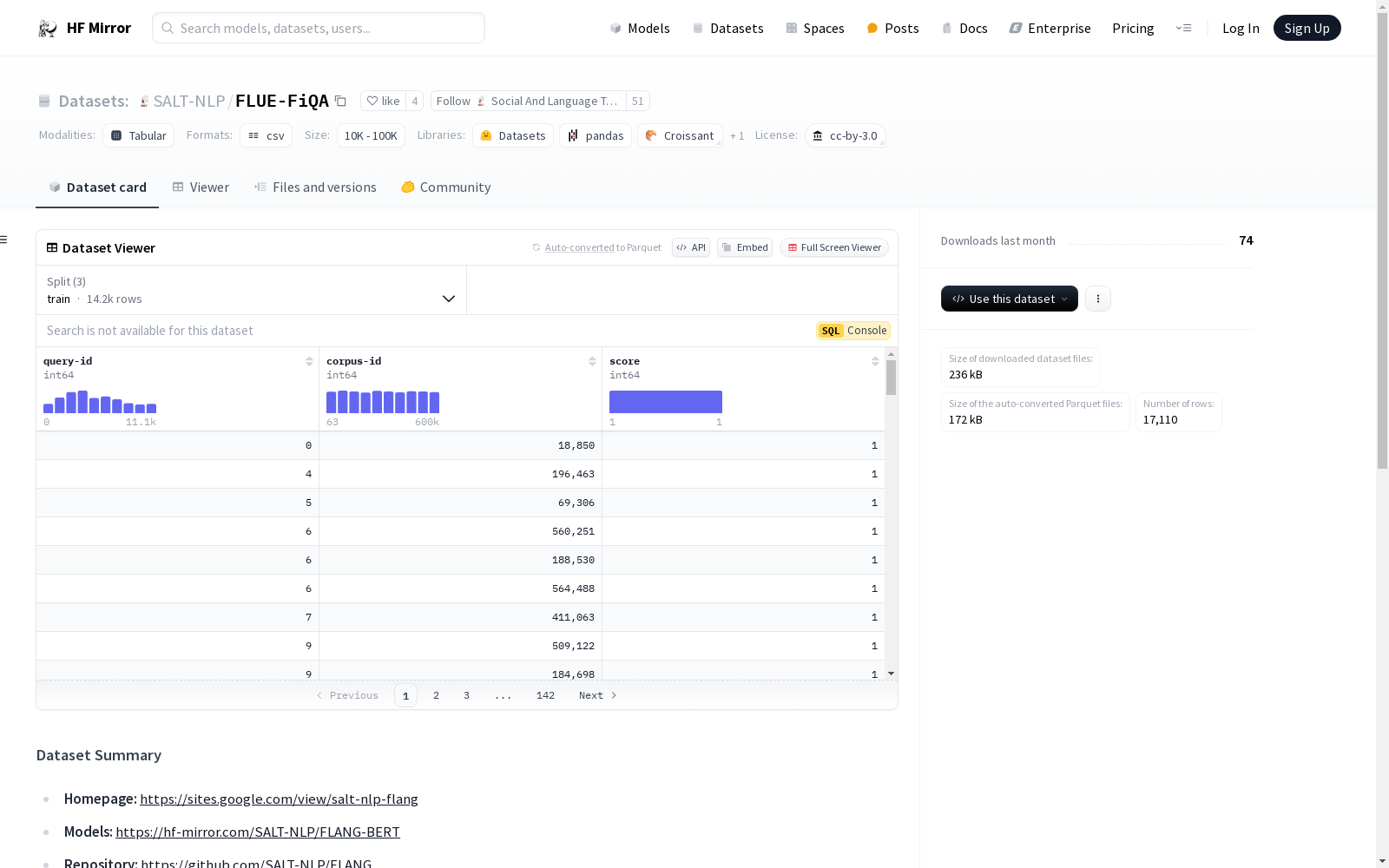
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
中国1km分辨率逐月平均气温数据集(1901-2024)
该数据为中国逐月平均温度数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2024.12。数据格式为NETCDF,即.nc格式。数据单位为0.1 ℃。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
SwimXYZ
SwimXYZ是由法国中央高等电力学院等机构创建的大型合成游泳动作和视频数据集,包含340万帧标注了2D和3D关节的图像,以及240个游泳动作序列。数据集通过使用GANimator生成多样化的游泳动作,并在Unity环境中模拟真实的水下环境。SwimXYZ旨在解决传统运动捕捉系统在游泳等水下运动中应用的局限性,特别是在缺乏标注数据的情况下。该数据集适用于游泳动作分析、2D和3D姿态估计等研究领域,有助于提升运动员训练和比赛表现的技术支持。
arXiv 收录
IMF International Financial Statistics (IFS)
国际货币基金组织(IMF)的国际金融统计(IFS)数据集提供了全球各国的金融和经济数据,包括货币供应、利率、国际收支、国际储备等。该数据集是研究国际金融和经济趋势的重要资源。
www.imf.org 收录
N-Caltech 101 (Neuromorphic-Caltech101)
The Neuromorphic-Caltech101 (N-Caltech101) dataset is a spiking version of the original frame-based Caltech101 dataset. The original dataset contained both a "Faces" and "Faces Easy" class, with each consisting of different versions of the same images. The "Faces" class has been removed from N-Caltech101 to avoid confusion, leaving 100 object classes plus a background class. The N-Caltech101 dataset was captured by mounting the ATIS sensor on a motorized pan-tilt unit and having the sensor move while it views Caltech101 examples on an LCD monitor as shown in the video below. A full description of the dataset and how it was created can be found in the paper below. Please cite this paper if you make use of the dataset.
Papers with Code 收录