common_voice_17_0
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/malaysia-ai/common_voice_17_0
下载链接
链接失效反馈官方服务:
资源简介:
Common Voice Corpus 17.0是一个包含大量语音数据的开源数据集,旨在构建和改善语音识别技术。该数据集由Mozilla基金会提供,此版本为镜像版本,方便用户下载和将音频文件转换为parquet格式。数据集分为训练集、测试集和开发集,包含了音频文件的元数据和用户信息,如客户端ID、路径、句子ID、句子内容、领域、投票数、年龄、性别、口音、变体和地区等。数据集遵循CC0-1.0协议,允许任何人自由使用。
Common Voice Corpus 17.0 is an open-source dataset comprising a large volume of speech data, aimed at constructing and advancing speech recognition technologies. Provided by the Mozilla Foundation, this version is a mirrored release to facilitate user downloads and the conversion of audio files to the Parquet format. The dataset is partitioned into training, test, and development subsets, and includes both audio file metadata and user-related information such as client ID, path, sentence ID, sentence content, domain, vote count, age, gender, accent, variant, and region. This dataset is licensed under CC0-1.0, permitting unrestricted free use by any individual.
创建时间:
2025-07-14
原始信息汇总
Common Voice Corpus 17.0 数据集概述
数据集基本信息
- 数据集名称: Common Voice Corpus 17.0
- 镜像来源: mozilla-foundation/common_voice_17_0
- 许可证: cc0-1.0
- 下载大小: 1036281984 字节
- 数据集大小: 3319464889 字节
数据集特征
- client_id: 字符串类型
- path: 字符串类型
- sentence_id: 字符串类型
- sentence: 字符串类型
- sentence_domain: 字符串类型
- up_votes: int64 类型
- down_votes: int64 类型
- age: 字符串类型
- gender: 字符串类型
- accents: 字符串类型
- variant: 字符串类型
- locale: 字符串类型
- segment: 字符串类型
- audio_filename: 字符串类型
数据集划分
- train:
- 字节数: 2878283900
- 样本数: 6689550
- test:
- 字节数: 224747066
- 样本数: 533642
- dev:
- 字节数: 216433923
- 样本数: 507874
数据文件配置
- 默认配置:
- train: data/train-*
- test: data/test-*
- dev: data/dev-*
数据集准备步骤
-
使用
huggingface-cli下载数据集: bash huggingface-cli download --repo-type dataset --include *.zip --local-dir ./ --max-workers 20 malaysia-ai/common_voice_17_0 -
下载并运行解压脚本: bash wget https://gist.githubusercontent.com/huseinzol05/2e26de4f3b29d99e993b349864ab6c10/raw/9b2251f3ff958770215d70c8d82d311f82791b78/unzip.py python3 unzip.py
搜集汇总
数据集介绍
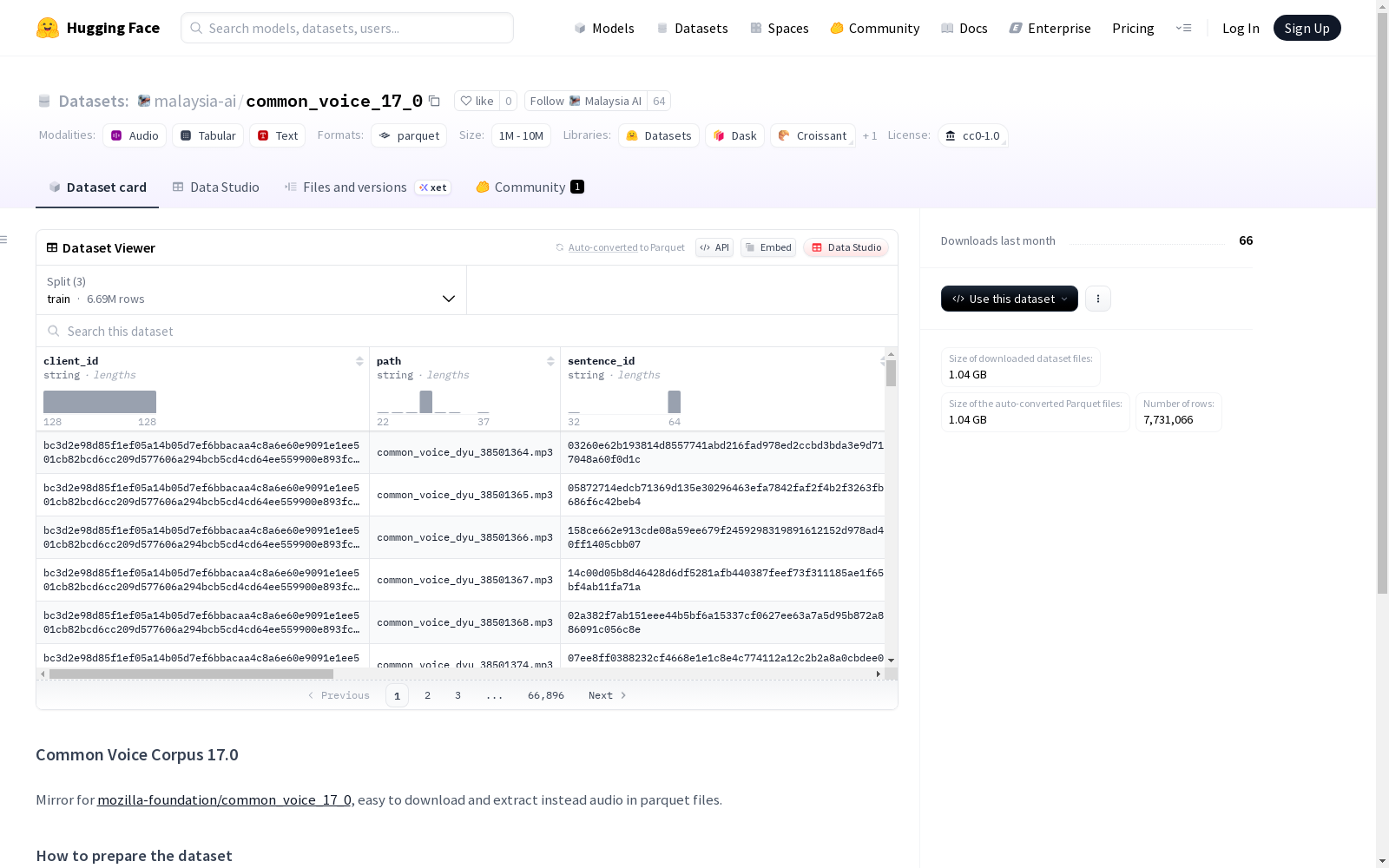
构建方式
在语音识别研究领域,Common Voice Corpus 17.0数据集通过全球社区众包方式构建,志愿者通过在线平台录制并验证句子录音,覆盖多样化的语言环境和人口统计特征。每条数据包含音频文件及元数据标注,如说话者年龄、性别、口音和地域变体,并经过上下投票机制进行质量过滤,确保语音样本的准确性与多样性。
特点
该数据集囊括超过770万条语音样本,涵盖多种语言变体和方言,每条数据均附带详细的元数据信息,包括说话者 demographic 属性及语音文本内容。其突出特点在于规模宏大、标注精细且语言多样性丰富,支持语音识别、语音合成及方言研究等多类任务,为跨语言语音技术开发提供了坚实基础。
使用方法
研究人员可通过Hugging Face数据集库直接下载该数据集,利用提供的Python脚本解压并访问parquet格式的音频与元数据文件。数据集已预先划分为训练、验证和测试子集,用户可加载相应split进行模型训练与评估,适用于端到端语音处理流程的构建与实验验证。
背景与挑战
背景概述
Common Voice语料库由Mozilla基金会于2017年发起,旨在构建全球最大的多语言开源语音数据集。该项目通过众包模式收集真实用户的语音样本,覆盖年龄、性别、口音等多维度人口统计学特征,致力于解决语音技术领域数据稀缺与多样性不足的核心问题。该数据集显著推动了语音识别、说话人验证及方言研究的发展,为构建包容性人工智能系统奠定了重要基础。
当前挑战
该数据集主要面临语音识别领域方言变异性和环境噪声干扰的技术挑战,需解决低资源语言模型泛化能力不足的问题。构建过程中需克服多语言音频质量标准化、人口统计学元数据标注一致性,以及众包数据隐私保护等难题,同时要确保数千小时音频数据与文本转录的高精度对齐。
常用场景
经典使用场景
在语音技术研究领域,Common Voice 17.0数据集被广泛用于构建多语言自动语音识别系统。研究者利用其大规模标注的语音-文本配对数据,训练端到端的深度学习模型,显著提升了语音转文字的准确率。该数据集支持跨语言建模,为低资源语言的语音处理提供了宝贵资源。
实际应用
在实际应用中,该数据集支撑了智能助手、实时字幕生成和语音交互系统的开发。企业利用其训练商业语音识别引擎,显著提升了产品在多样化用户群体中的表现。教育机构则基于该数据开发语言学习工具,帮助学习者改善发音和听力理解能力。
衍生相关工作
基于该数据集衍生出了多项重要研究,包括多语言语音识别模型Whisper的预训练、端到端语音翻译系统的开发,以及语音合成技术的改进。这些工作不仅在学术会议上发表,还推动了开源语音工具包如ESPnet和Fairseq的持续演进与优化。
以上内容由遇见数据集搜集并总结生成


