xai-questions-dataset
收藏Hugging Face2025-10-24 更新2025-10-25 收录
下载链接:
https://huggingface.co/datasets/lwachowiak/xai-questions-dataset
下载链接
链接失效反馈官方服务:
资源简介:
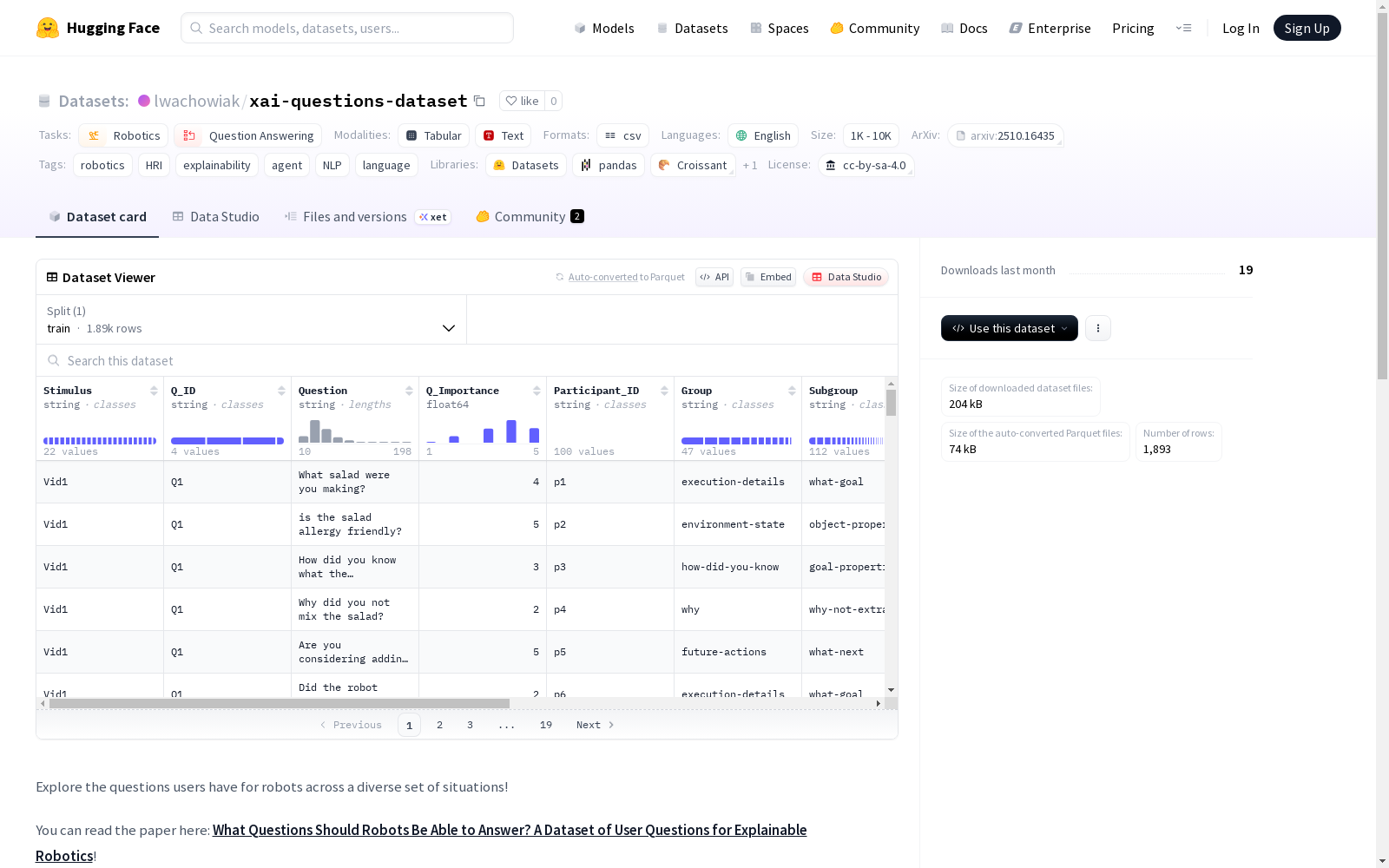
这是一个包含1893个面向家庭机器人的用户问题的数据集,由100名参与者提供,分为12个类别和70个子类别。这些问题涵盖了从任务执行细节到机器人如何处理假设性场景的广泛类型,旨在帮助机器人学家了解他们的机器人需要能够回答哪些问题。
创建时间:
2025-10-16
原始信息汇总
数据集概述
基本信息
- 数据集名称: xai-questions-dataset
- 语言: 英语
- 许可证: CC-BY-SA-4.0
- 数据规模: 1K-10K样本
- 研究领域: 机器人学、人机交互、可解释性、智能体、自然语言处理
- 任务类型: 机器人学、问答系统
数据内容
- 数据总量: 1,893条用户问题
- 数据来源: 100名参与者
- 组织方式: 12个主要类别和70个子类别
- 收集方法: 通过15个视频刺激和7个文本刺激收集,展示机器人执行各种家务任务的情景
主要问题类别分布
- 任务执行细节问题: 22.5%
- 机器人能力问题: 12.7%
- 性能评估问题: 11.3%
数据集特点
- 涵盖广泛的问题类型,从简单执行细节到假设情景中的行为问题
- 提供机器人需要能够回答的用户问题洞察
- 包含不同用户群体(新手与有经验用户)的问题差异分析
应用价值
- 识别机器人需要记录和暴露给对话界面的信息
- 基准测试问答模块
- 设计与用户期望一致的解释策略
相关资源
- 论文: https://arxiv.org/abs/2510.16435
- 代码库: https://github.com/lwachowiak/xai-questions-dataset
- 加载方式: python from datasets import load_dataset dataset = load_dataset("lwachowiak/xai-questions-dataset")
搜集汇总
数据集介绍
构建方式
在可解释机器人研究领域,数据采集方法直接影响研究结果的普适性。该数据集通过精心设计的15个视频刺激与7个文本刺激材料,模拟家庭服务机器人在多样化场景中的任务执行过程。研究团队通过Prolific平台招募100名参与者,针对每个情境提出自然语言问题,最终系统化收集了1,893个用户提问。这种多模态刺激与开放式提问相结合的方法,有效捕捉了用户对机器人行为的真实好奇点与信息需求。
特点
本数据集最显著的特征在于其问题类型的广谱分布,突破了传统可解释性研究聚焦于因果类问题的局限。通过对用户提问进行精细化标注,形成了涵盖12个主类别与70个子类别的分类体系,其中任务执行细节类问题占比22.5%,能力询问类占12.7%,性能评估类占11.3%。特别值得关注的是,数据集揭示了用户对机器人处理复杂情境能力的强烈关注,同时记录了不同技术背景用户提问模式的系统性差异,为个性化解释策略设计提供了数据支撑。
使用方法
该数据集为机器人对话系统开发提供了多维度的应用场景。研究者可通过HuggingFace平台直接加载数据集,利用其结构化的问题分类体系训练机器人问答模块。在系统设计层面,数据集可指导机器人日志系统的信息采集重点,确保关键状态信息能被有效记录与调用。此外,各类问题的分布规律为解释策略的优先级设置提供了实证依据,使得机器人解释能力的开发更贴合用户实际需求。
背景与挑战
背景概述
随着大型语言模型与对话式接口在人类-机器人交互领域的广泛应用,机器人应答用户提问的能力已成为关键研究议题。xai-questions-dataset由Lennart Wachowiak等学者于2025年创建,聚焦于家庭服务机器人场景下用户提问的系统性收集与分类。该数据集通过视频与文本双模态刺激材料,采集了来自100位参与者的1,893个问题,构建起涵盖12个主类别与70个子类别的语义框架。其核心价值在于突破了传统可解释机器人研究局限于“为什么”类问题的范式,首次全面揭示了用户对机器人行为细节、能力边界及假设情景推演的多元信息需求,为人机交互系统的语义理解与应答机制设计提供了实证基础。
当前挑战
在领域问题层面,该数据集直面家庭场景中机器人动态应答能力的核心挑战:如何构建覆盖多粒度语义空间的问答系统,包括从基础任务执行细节到复杂伦理推理的连续统。具体体现为对非结构化用户提问的意图识别难题,以及跨模态情境下问题泛化能力的缺失。在数据构建过程中,研究团队需克服刺激材料生态效度与数据标注一致性的双重压力:通过精心设计的15组视频与7组文本情境,平衡真实场景复杂性与实验可控性;同时采用多级分类体系解决用户提问的语义重叠问题,并针对机器人领域新手与专家用户的认知差异进行数据分层处理。
常用场景
经典使用场景
在可解释机器人学领域,xai-questions-dataset为研究人机交互中的对话系统提供了关键支撑。该数据集通过1893个用户提问的系统分类,揭示了家庭服务机器人面临的多维度咨询需求,涵盖任务执行细节、能力边界评估及假设场景推演等12个核心类别。研究者可基于这些真实语料构建机器人问答模块的测试基准,特别适用于验证对话系统在复杂家居环境中的语义理解与知识推理能力。
实际应用
在智能家居场景中,该数据集直接指导服务机器人的功能优化。基于用户对任务执行细节(22.5%)和能力边界(12.7%)的高频关注,开发者可针对性强化机器人的状态报告与异常处理模块。医疗陪护机器人通过集成数据集中揭示的假设场景问答能力,能有效缓解用户对突发状况的焦虑。工业巡检机器人则可借鉴其性能评估类问题的处理逻辑,构建更透明的作业报告体系。
衍生相关工作
该数据集已催生多项人机对话系统的创新研究。斯坦福团队基于其构建的Hierarchical-QA框架实现了多轮对话的场景迁移,MIT研究者则利用其细粒度分类体系开发了自适应解释生成模型。后续工作进一步扩展了数据集的边界,如卡耐基梅隆大学开发的X-Plain基准测试集,以及欧盟HORIZON项目中的跨文化机器人解释行为研究,共同推动了可解释机器人学的方法论发展。
以上内容由遇见数据集搜集并总结生成


