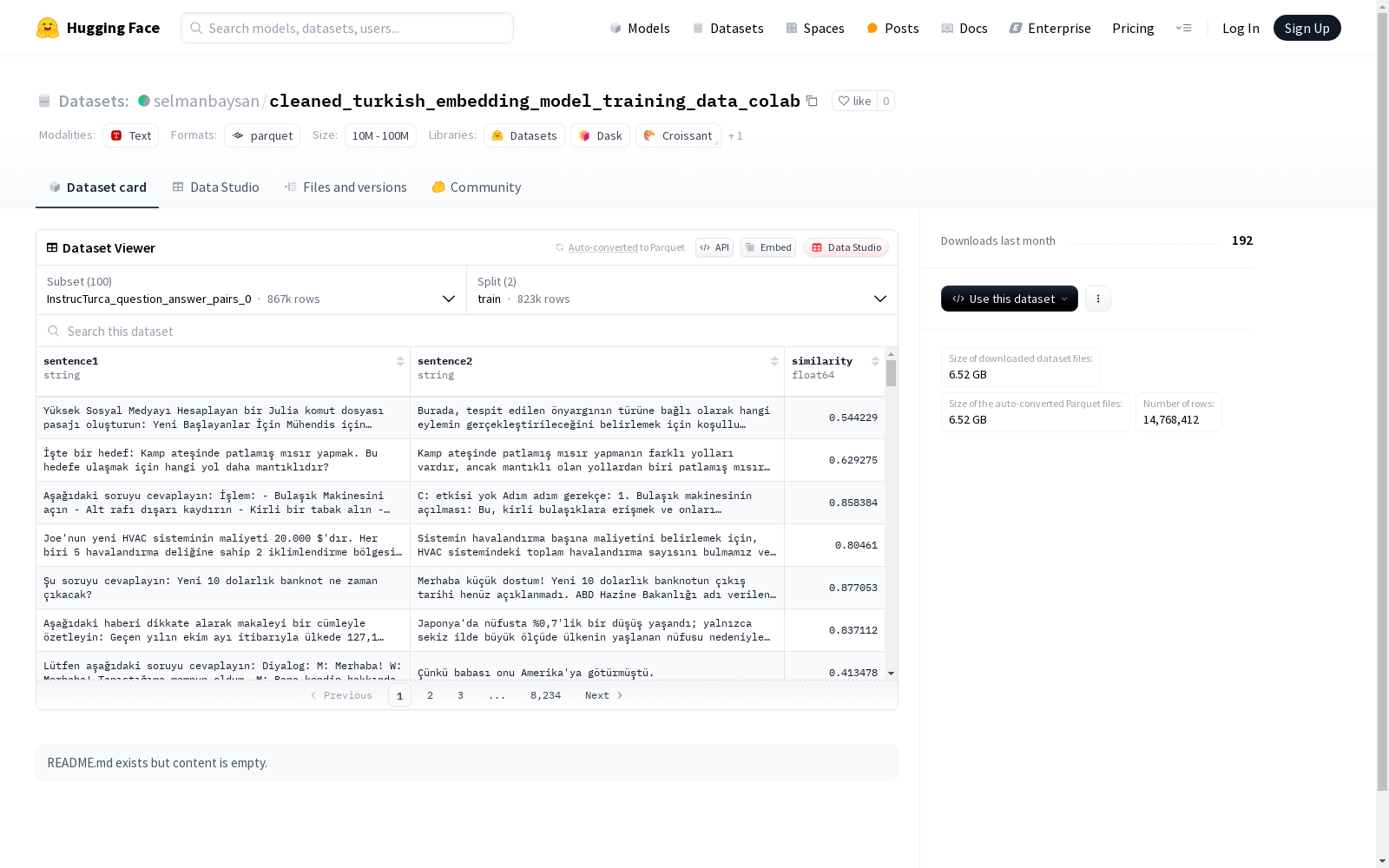
cleaned_turkish_embedding_model_training_data_colab
收藏数据集概述
基本信息
- 数据集名称: cleaned_turkish_embedding_model_training_data_colab
- 数据集地址: https://huggingface.co/datasets/selmanbaysan/cleaned_turkish_embedding_model_training_data_colab
数据集配置
数据集包含多个配置,每个配置包含以下特征:
- sentence1: 字符串类型
- sentence2: 字符串类型
- similarity: 浮点类型
主要配置
-
InstrucTurca_question_answer_pairs_0
- 训练集: 823,337 个样本
- 验证集: 43,205 个样本
- 下载大小: 826,804,138 字节
- 数据集大小: 1,411,126,541 字节
-
InstrucTurca_question_answer_pairs_1
- 训练集: 823,620 个样本
- 验证集: 43,373 个样本
- 下载大小: 827,578,466 字节
- 数据集大小: 1,412,370,690 字节
-
InstrucTurca_question_answer_pairs_2
- 训练集: 476,045 个样本
- 验证集: 24,895 个样本
- 下载大小: 469,451,579 字节
- 数据集大小: 804,226,227 字节
-
LlamaTurk-Instruction-Set_pairs
- 训练集: 39,534 个样本
- 验证集: 2,088 个样本
- 下载大小: 11,113,286 字节
- 数据集大小: 17,736,437 字节
-
MedTurkQuAD_answer_context_pairs
- 训练集: 1,427 个样本
- 验证集: 74 个样本
- 下载大小: 473,183 字节
- 数据集大小: 1,463,956 字节
-
MedTurkQuAD_question_answer_pairs
- 训练集: 1,373 个样本
- 验证集: 81 个样本
- 下载大小: 129,730 字节
- 数据集大小: 206,867 字节
-
MedTurkQuAD_question_context_pairs
- 训练集: 4,621 个样本
- 验证集: 251 个样本
- 下载大小: 831,935 字节
- 数据集大小: 4,964,911 字节
-
OpenOrca-tr_question_answer_pairs
- 训练集: 616,458 个样本
- 验证集: 32,606 个样本
- 下载大小: 636,512,731 字节
- 数据集大小: 1,045,767,311 字节
-
TDK_Sozluk-Turkish_title_text_pairs
- 训练集: 69,299 个样本
- 验证集: 3,532 个样本
- 下载大小: 3,094,284 字节
- 数据集大小: 4,775,574 字节
-
TRTDataWarrriorsDataset_question_answer_pairs
- 训练集: 1,863 个样本
- 验证集: 103 个样本
- 下载大小: 362,135 字节
- 数据集大小: 611,513 字节
-
ThinkingData-200K-Turkish_pairs
- 训练集: 191,956 个样本
- 验证集: 10,150 个样本
- 下载大小: 218,706,225 字节
- 数据集大小: 394,637,509 字节
-
Turkish-Youtube-Comments_question_answer_pairs
- 训练集: 3,320 个样本
- 验证集: 174 个样本
- 下载大小: 912,491 字节
- 数据集大小: 1,744,601 字节
-
WikiRAG-TR_answer_context_pairs
- 训练集: 1,870 个样本
- 验证集: 96 个样本
- 下载大小: 3,529,160 字节
- 数据集大小: 5,629,492 字节
-
WikiRAG-TR_question_answer_pairs
- 训练集: 5,420 个样本
- 验证集: 259 个样本
- 下载大小: 1,351,697 字节
- 数据集大小: 2,163,848 字节
-
WikiRAG-TR_question_context_pairs
- 训练集: 1,968 个样本
- 验证集: 108 个样本
- 下载大小: 3,437,405 字节
- 数据集大小: 5,499,408 字节
-
Wikinews-multilingual_title_text_pairs
- 训练集: 237 个样本
- 验证集: 15 个样本
- 下载大小: 71,997 字节
- 数据集大小: 110,121 字节
-
alpaca-tr_question_answer_pairs
- 训练集: 26,311 个样本
- 验证集: 1,427 个样本
- 下载大小: 16,742,900 字节
- 数据集大小: 30,807,734 字节
-
arc-tr_question_answer_pairs_challenge
- 训练集: 1,691 个样本
- 验证集: 88 个样本
- 下载大小: 149,658 字节
- 数据集大小: 370,510 字节
-
arc-tr_question_answer_pairs_easy
- 训练集: 2,509 个样本
- 验证集: 124 个样本
- 下载大小: 194,816 字节
- 数据集大小: 474,048 字节
-
babel-briefings_answer_context_pairs
- 训练集: 76,490 个样本
- 验证集: 4,020 个样本
- 下载大小: 23,697,664 字节
- 数据集大小: 35,954,625 字节
-
babel-briefings_question_answer_pairs
- 训练集: 102,726 个样本
- 验证集: 5,432 个样本
- 下载大小: 22,055,599 字节
- 数据集大小: 33,739,383 字节
-
babel-briefings_question_context_pairs
- 训练集: 68,040 个样本
- 验证集: 3,608 个样本
- 下载大小: 15,517,778 字节
- 数据集大小: 23,034,680 字节
-
ccnews_2017_pairs
- 训练集: 496,070 个样本
- 验证集: 25,862 个样本
- 下载大小: 594,648,968 字节
- 数据集大小: 1,050,940,586 字节
-
ccnews_pairs
- 训练集: 52,794 个样本
- 验证集: 2,764 个样本
- 下载大小: 59,319,449 字节
- 数据集大小: 102,394,972 字节
-
doktorsitesi_question_answer_pairs
- 训练集: 71,459 个样本
- 验证集: 3,664 个样本
- 下载大小: 39,237,277 字节
- 数据集大小: 61,048,222 字节
-
flickr8k-turkish_title_text_pairs
- 训练集: 6,161 个样本
- 验证集: 316 个样本
- 下载大小: 510,635 字节
- 数据集大小: 899,804 字节
-
gsm8k-tr_question_answer_pairs
- 训练集: 8,326 个样本
- 验证集: 412 个样本
- 下载大小: 3,423,871 字节
- 数据集大小: 6,830,579 字节
-
legal_nli_TR_V1_title_text_pairs
- 训练集: 182,723 个样本
- 验证集: 9,634 个样本
- 下载大小: 328,215,960 字节
- 数据集大小: 732,877,913 字节
-
lr-sum_text_summary_pairs
- 训练集: 32,085 个样本
- 验证集: 1,667 个样本
- 下载大小: 70,504,497 字节
- 数据集大小: 124,512,950 字节
-
lr-sum_title_summary_pairs
- 训练集: 24,200 个样本
- 验证集: 1,247 个样本
- 下载大小: 4,466,479 字节
- 数据集大小: 6,896,576 字节
-
lr-sum_title_text_pairs
- 训练集: 26,972 个样本
- 验证集: 1,469 个样本
- 下载大小: 55,275,754 字节
- 数据集大小: 98,203,612 字节
-
mfaq_question_answer_pairs
- 训练集: 57,985 个样本
- 验证集: 3,071 个样本
- 下载大小: 5,563,933 字节
- 数据集大小: 15,381,180 字节
-
mlsum_summary_text_pairs
- 训练集: 251,068 个样本
- 验证集: 13,179 个样本
- 下载大小: 348,069,237 字节
- 数据集大小: 626,629,444 字节
-
mlsum_title_summary_text_pairs
- 训练集: 219,641 个样本
- 验证集: 11,387 个样本
- 下载大小: 33,276,981 字节
- 数据集大小: 53,262,116 字节
-
mlsum_title_text_pairs
- 训练集: 214,237 个样本
- 验证集: 11,429 个样本
- 下载大小: 274,132,496 字节
- 数据集大小: 499,816,070 字节
-
multilingual-NLI-26lang-2mil7_tr_anli_pairs
- 训练集: 3,860 个样本
- 验证集: 195 个样本
- 下载大小: 1,066,153 字节
- 数据集大小: 1,650,714 字节
-
multilingual-NLI-26lang-2mil7_tr_fever_pairs
- 训练集: 12,443 个样本
- 验证集: 631 个样本
- 下载大小: 2,930,202 字节
- 数据集大小: 4,486,564 字节
-
multilingual-NLI-26lang-2mil7_tr_ling_pairs
- 训练集: 1,168 个样本
- 验证集: 69 个样本
- 下载大小: 178,692 字节
- 数据集大小: 247,518 字节
-
multilingual-NLI-26lang-2mil7_tr_wanli_pairs
- 训练集: 7,812 个样本
- 验证集: 405 个样本
- 下载大小: 899,630 字节
- 数据集大小: 1,326,540 字节
-
multilingual-reward-bench_question_answer_pairs
- 训练集: 2,448 个样本
- 验证集: 143 个样本
- 下载大小: 1,231,078 字节
- 数据集大小: 2,431,551 字节
-
neural-news-benchmark_title_text_pairs
- 训练集: 1,845 个样本
- 验证集: 73 个样本
- 下载大小: 1,990,963 字节
- 数据集大小: 4,374,126 字节
-
oasst1_pairwise_rlhf_reward_question_answer_pairs
- 训练集: 4 个样本
- 验证集: 1 个样本
- 下载大小: 17,142 字节
- 数据集大小: 4,809 字节
-
onedio_haberler_title_text_pairs
- 训练集: 56,613 个样本
- 验证集: 2,935 个样本
- 下载大小: 68,456,840 字节
- 数据集大小: 117,406,082 字节
-
oo-gpt4-filtered-tr_question_answer_pairs
- 训练集: 81,477 个样本
- 验证集: 4,275 个样本
- 下载大小: 93,182,046 字节
- 数据集大小: 153,541,569 字节
-
patient-doctor-qa-tr-19583_text_summary_pairs
- 训练集: 62,172 个样本
- 验证集: 3,228 个样本
- 下载大小: 58,844,399 字节
- 数据集大小: 101,418,950 字节
-
patient-doctor-qa-tr-19583_title_summary_pairs
- 训练集: 52,470 个样本
- 验证集: 2,800 个样本
- 下载大小: 33,730,078 字节
- 数据集大小: 58,854,972 字节
-
patient-doctor-qa-tr-19583_title_text_pairs
- 训练集: 64,992 个样本
- 验证集: 3,442 个样本
- 下载大小: 25,000,647 字节
- 数据集大小: 41,898,750 字节
-
se_data_set_question_answer_pairs
- 训练集: 729 个样本
- 验证集: 36 个样本
- 下载大小: 60,836 字节
- 数据集大小: 300,966 字节
-
seahorse_summarization_evaluation_answer_summary_pairs
- 训练集: 6 个样本
- 验证集: 1 个样本
- 下载大小: 3,217 字节
- 数据集大小: 339 字节
-
tapaco_paraphrase_pairs
- 训练集: 159,339 个样本
- 验证集: 8,459 个样本
- 下载大小: 5,685,499 字节
- 数据集大小: 12,544,213 字节
-
tr_news_abstract_content_pairs
- 训练集: 282,777 个样本
- 验证集: 14,906 个样本
- 下载大小: 396,318,402 字节
- 数据集大小: 657,438,453 字节
-
tr_news_title_abstract_pairs
- 训练集: 256,046 个样本
- 验证集: 13,503 个样本
- 下载大小: 46,971,519 字节
- 数据集大小: 66,876,755 字节
-
tr_news_title_content_pairs
- 训练集: 246,260 个样本
- 验证集: 13,016 个样本
- 下载大小: 305,656,407 字节
- 数据集大小: 510,288,373 字节
-
turkish-law-chatbot_question_answer_pairs
- 训练集: 11,930 个样本
- 验证集: 592 个样本
- 下载大小: 1,350,505 字节
- 数据集大小: 4,352,199 字节
-
turkish_exam_instructions_question_answer_pairs
- 训练集: 数据不完整