DD100
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/OpenMol/DD100
下载链接
链接失效反馈官方服务:
资源简介:
DrugSeeker-mini基准数据集是一个简化的评估数据集,用于端到端的药物发现流程,整合了来自多个权威公共数据源的问答和分类任务。该数据集总共包含91个查询,覆盖了药物发现的三个主要阶段:目标识别、先导化合物发现和先导化合物优化。每个查询都有明确的输入/输出描述、标准答案和匹配策略,以便对大型语言模型在生物医学问题上的推理和知识能力进行统一评估。
创建时间:
2025-08-25
原始信息汇总
DrugSeeker-mini 数据集概述
基本信息
- 数据集名称:drugseeker_small
- 维护机构:OpenMol
- 语言:英语
- 许可证:cc-by-nc-4.0
- 规模类别:n<1K
- 任务类别:文本生成
- 领域标签:生物学、化学、药物、药物发现、基准测试
数据集简介
DrugSeeker-mini基准测试是一个用于端到端药物发现流程的简化评估数据集,汇总了来自多个权威公共数据源的问答和分类任务,共包含91个查询。这些查询涵盖药物发现的三个主要阶段:靶点识别(TI)、先导化合物发现(HLD)和先导化合物优化(LO)。每个查询包含清晰的输入/输出描述、标准答案和匹配策略,便于统一评估大型语言模型在生物医学问题中的推理和知识能力。
数据来源
- 主存储库:https://huggingface.co/datasets/OpenMol/Drugseeker_mini_benchmark
- 聚合数据源:
- 靶点识别阶段:IEDB、ProteinLMBench、DGIdb、HuRI、Open Target Platform、PDB、DisGenNET
- 先导化合物发现阶段:Weber、SARS-CoV-2 In Vitro、SARS-CoV-2 3CL Protease、QM7、QM8、QM9、HIV、miRTarBase
- 先导化合物优化阶段:BBB、Bioavailability、ClinTox、DILI、Tox21、Carcinogens、TWOSIDES Polypharmacy Side Effects、DrugBank Multi-Typed DDI、hERG central、hERG blockers、HIA、Pgp,以及各种CYP450相关数据(包括1A2/2C9/2C19/2D6/3A4等的底物和抑制任务)
用途说明
- 预期用途:
- 作为评估大型语言模型在药物发现任务(问答、多项选择、精确匹配)上的基准测试
- 衡量模型的生物知识、药理学理解以及化学/ADMET相关推理能力
- 在典型药物研究问题上实现不同模型/算法的快速小规模比较
- 非预期用途:
- 不适用于任何临床诊断决策、真实患者干预或安全关键决策
- 未经严格验证,不得将评估结论外推至实际研发中
数据结构
数据集采用JSON格式,包含以下主要字段:
- uuid:数据集实例UUID
- name/version/description/created_at:数据集元数据
- total_queries:查询条目总数
- queries:查询条目数组,每个条目包含:
task_name:任务名称task_stage:任务阶段(靶点识别|先导化合物发现|先导化合物优化)task_description:药物发现流程中的任务描述dataset_name/dataset_description/dataset_source:原始来源名称、描述和链接input_description/output_description:输入/输出语义描述input_type/output_type:输入/输出类型query:实际评估提示(包括答案格式要求)ground_truth:标准答案(字符串,可能是选项字母或短文本)matching_strategy:匹配策略(MCQ或精确匹配或分类或回归)created_at/uuid:条目级时间戳和标识符
搜集汇总
数据集介绍
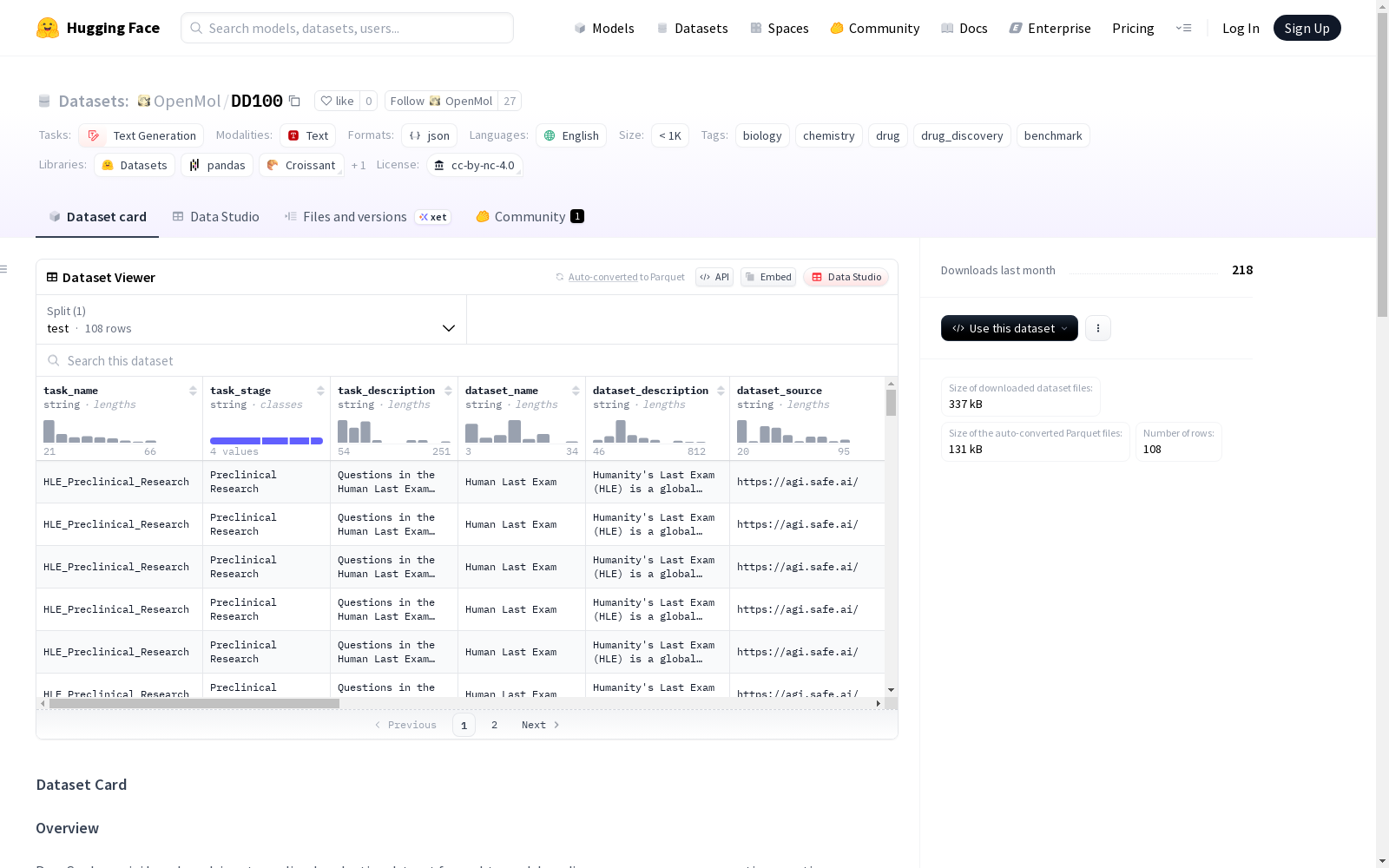
构建方式
在药物发现领域,DD100数据集通过整合多个权威公共数据源精心构建而成,涵盖目标识别、先导化合物发现和先导优化三大关键阶段。该数据集采用严格的筛选流程,从IEDB、ProteinLMBench、DGIdb等专业数据库中提取91个高质量查询,每个查询均包含清晰的输入输出描述、标准答案及匹配策略,确保数据集的科学性和可靠性。
特点
DD100数据集以其跨学科综合性著称,深度融合生物学、化学和药理学知识,涵盖从分子相互作用到临床毒理学的全方位评估维度。其特色在于采用多类型任务设计,包括问答、多项选择和精确匹配等多种评估模式,能够全面检验大型语言模型在生物医学领域的知识储备和推理能力。数据集结构清晰,每个查询都配有详细的元数据描述,为研究者提供透明可追溯的实验基础。
使用方法
研究人员可通过加载标准JSON格式文件快速接入DD100数据集,利用其统一的结构化评估框架对语言模型进行系统测试。使用时应遵循数据集设计的匹配策略,包括多选题判断、精确文本匹配和分类回归等评估方式,确保结果的可比性。需要注意的是,该数据集仅限研究评估用途,严禁用于临床决策或实际药物开发场景,所有结论需经过严格验证才能应用于实践。
背景与挑战
背景概述
DD100数据集由OpenMol团队精心构建,聚焦于药物发现领域的智能评估需求。该数据集整合了来自IEDB、ProteinLMBench、DGIdb等权威公共数据源的多维度任务,涵盖靶点识别、先导化合物发现和先导优化三大关键研究阶段。通过91个精心设计的查询项,它不仅促进了大型语言模型在生物医学问题中的推理与知识能力评估,更推动了计算药物研发方法的标准化进程,为人工智能在制药领域的应用提供了重要基准。
当前挑战
构建DD100数据集面临多重挑战:在领域问题层面,需要精准建模药物发现中复杂的多阶段决策流程,包括生物靶点互作预测、化合物活性筛选及ADMET属性评估等高度专业化的任务;在数据处理层面,需协调来自不同实验平台、具有异构格式和标准化差异的数据源,同时确保化学结构表征与生物活性数据的准确对齐。这些挑战要求数据集既保持科学严谨性,又具备可扩展的评估框架。
常用场景
经典使用场景
在药物研发领域,DD100数据集作为标准化评估工具,主要应用于测试大型语言模型在生物医学知识推理方面的性能。其经典使用场景涵盖靶点识别、先导化合物发现和先导化合物优化三大关键阶段,通过91个精心设计的查询任务,系统评估模型对蛋白质相互作用、化合物活性及ADMET属性的理解能力,为算法在药物发现流程中的实际效用提供量化依据。
实际应用
实际应用中,DD100被制药企业和研究机构用于快速筛选具备药物研发潜力的AI模型,特别是在虚拟筛选和毒性预测环节发挥重要作用。研究人员通过该数据集对比不同模型在特定任务(如hERG阻断预测、CYP450酶抑制判断)上的表现,显著降低了实验验证成本,加速了候选化合物的优化流程,为临床前研究提供了可靠的计算支持。
衍生相关工作
基于DD100的评估框架,衍生出多项经典研究工作,包括融合分子图神经网络与语言模型的跨模态推理方法、针对ADMET属性的多任务学习架构,以及结合强化学习的分子生成策略。这些工作显著提升了模型在药物亲和力预测、毒性规避等细分任务的性能,推动了AI驱动药物研发范式的标准化和规模化发展。
以上内容由遇见数据集搜集并总结生成


