medmax_data
收藏Hugging Face2024-12-15 更新2024-12-16 收录
下载链接:
https://huggingface.co/datasets/mint-medmax/medmax_data
下载链接
链接失效反馈官方服务:
资源简介:
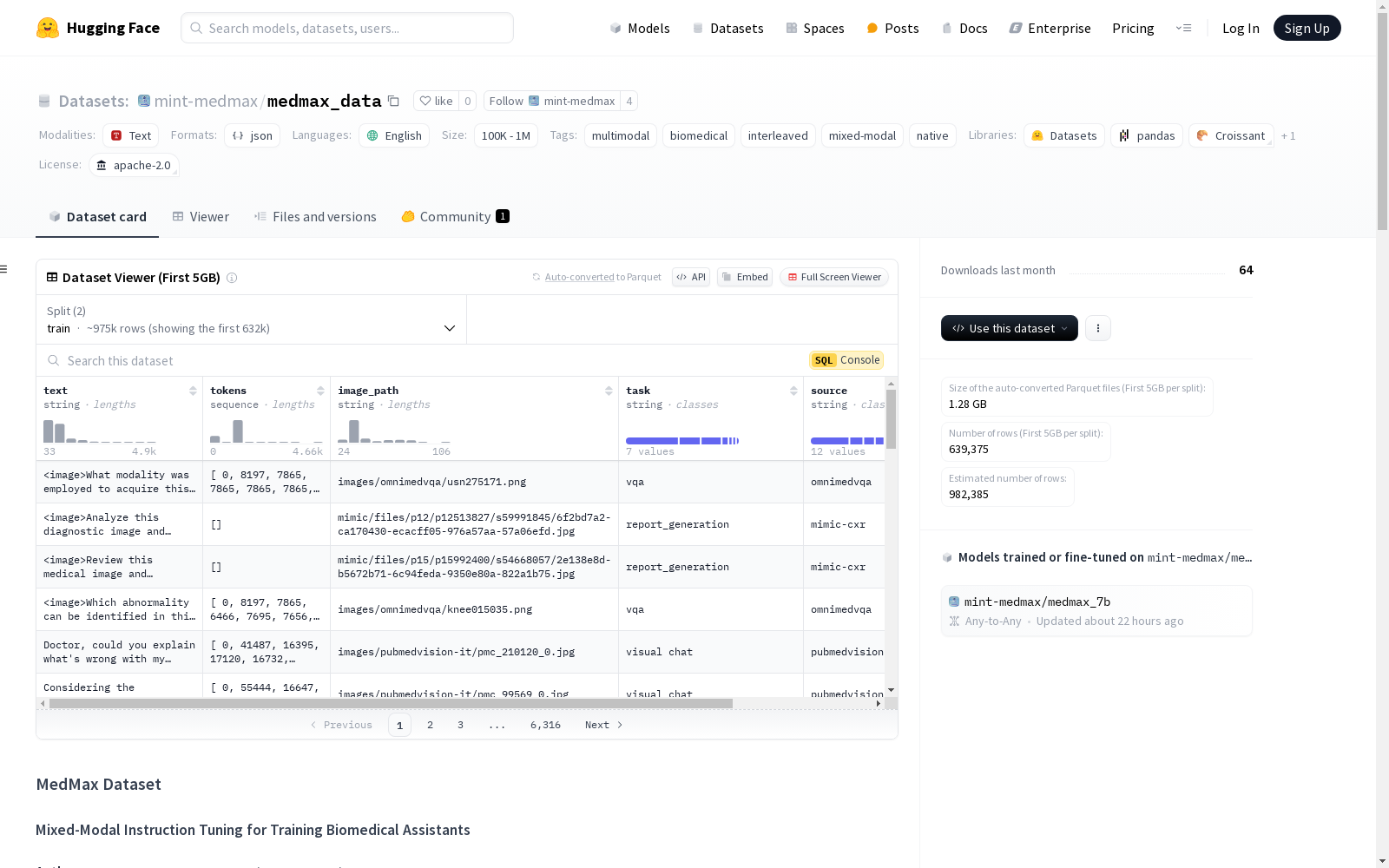
MedMax数据集是一个大规模的多模态生物医学指令调优数据集,旨在为混合模态基础模型提供训练数据。该数据集包含147万个实例,涵盖了多种任务,如多模态内容生成、生物医学图像描述和生成、视觉聊天和报告理解等。数据集的每个实例包括文本、标记化表示、图像路径、任务类型、数据来源和访问级别等信息。数据集的统计信息显示,共有1.47M个实例,725K个唯一图像和947K个唯一单词,总共有1.7B个标记(0.7B视觉标记和1B文本标记)。数据集的来源包括PubMedVision-IT、PMC-VQA等多个生物医学数据源。
The MedMax dataset is a large-scale multimodal biomedical instruction-tuning dataset developed to provide training data for hybrid-modal foundation models. It contains 1.47 million instances spanning a diverse set of tasks, such as multimodal content generation, biomedical image captioning and generation, visual chatting, report understanding, and others. Each instance within the dataset comprises information including text, tokenized representations, image paths, task types, data sources, and access levels. Statistical analyses of the dataset demonstrate that it includes 1.47M instances, 725K unique images, 947K unique words, with a total of 1.7B tokens (0.7B visual tokens and 1B text tokens). The dataset is sourced from multiple biomedical data repositories including PubMedVision-IT and PMC-VQA, among others.
创建时间:
2024-12-14
原始信息汇总
MedMax Dataset
概述
MedMax 是首个大规模多模态生物医学指令调优数据集,用于混合模态基础模型的训练。该数据集包含147万条实例,涵盖多种任务,包括多模态内容生成(交错图像-文本数据)、生物医学图像描述和生成、视觉聊天和报告理解。这些任务涉及放射学和组织病理学等多个医学领域。
数据集详情
数据结构
每个数据集实例包括:
text:指令、上下文和预期响应(可以是纯文本或多模态)。tokens:文本和图像的标记化表示(需要用户下载图像并进行标记化)。image_path:对应图像文件的引用。task:生物医学任务类型(如VQA、图像生成、报告理解)。source:数据来源。credential:访问级别(yes/no),指示是否需要特殊凭证。
任务与来源
任务: 视觉聊天、VQA(视觉问答)、图像描述、多模态生成、图像生成、报告理解
来源: PubMedVision-IT, PMC-VQA, PMC_OA, QUILT_1M, QUILT_Instruct, PubMedVision-Alignment, MIMIC-CXR, OmniMedVQA, LLaVA-Med-IT, LLaVA-Med-PMC, PathVQA, SLAKE, VQA-RAD
数据集统计
- 总实例数:1.47M
- 唯一图像数:725K
- 唯一词数:947K
- 标记分布:1.7B tokens(0.7B视觉,1B文本)
使用数据集
非凭证数据(credential=no)
-
下载图像: bash cat images.tar.gz.* | tar -xzf -
-
直接从数据集文件中访问文本和标记化数据。
凭证数据(credential=yes)
- 从相应来源获取原始图像(如MIMIC-CXR、Quilt)。
- 处理图像以生成标记。
凭证图像访问
MIMIC-CXR数据集
- 访问PhysioNet并完成所需的培训课程以获取凭证。
- 下载图像文件。
Quilt和Quilt-Instruct数据集
- 通过官方表单提交访问请求。
- 下载图像后,将图像路径映射回数据集的图像路径,并使用VQGAN编码器自行标记化这些图像。
许可证
Apache 2.0
搜集汇总
数据集介绍
构建方式
MedMax数据集的构建旨在填补多模态生物医学领域中数据稀缺的空白。该数据集通过整合多种生物医学任务,如多模态内容生成、图像字幕生成、视觉聊天和报告理解,构建了一个包含1.47百万实例的大规模多模态生物医学指令调优数据集。每个实例包含文本指令、上下文、预期响应、图像路径、任务类型和数据来源等信息,确保了数据的多样性和广泛性。
特点
MedMax数据集的显著特点在于其多模态性和任务多样性。数据集不仅涵盖了文本和图像的混合模态,还涉及多种生物医学任务,如视觉问答、图像生成和报告理解。此外,数据集的构建考虑了不同访问级别的图像数据,包括需要特殊权限的图像,确保了数据的安全性和合法性。
使用方法
使用MedMax数据集时,用户需首先下载数据集仓库,并根据数据访问权限下载相应的图像数据。对于非权限数据,用户可以直接解压图像文件并访问文本和标记化数据。对于权限数据,用户需从相应源获取原始图像,并自行处理生成标记。数据集提供了详细的使用指南和图像处理说明,确保用户能够顺利进行数据处理和模型训练。
背景与挑战
背景概述
在多模态信息处理与生物医学领域的交叉研究中,大型语言模型(LLMs)和大型多模态模型(LMMs)展现了其在图像分析、诊断及数据集构建方面的巨大潜力。然而,这些模型在医学领域的应用仍受限于数据稀缺、领域覆盖狭窄及数据来源单一等问题。为应对这些挑战,加州大学洛杉矶分校的研究团队,由Hritik Bansal、Daniel Israel、Siyan Zhao等人领导,推出了MedMax数据集。作为首个大规模多模态生物医学指令调优数据集,MedMax包含了147万条实例,涵盖了多模态内容生成、生物医学图像描述与生成、视觉对话及报告理解等多种任务,广泛应用于放射学和病理学等领域。该数据集的发布不仅填补了生物医学AI领域的数据空白,还为多模态基础模型的训练提供了宝贵的资源。
当前挑战
MedMax数据集的构建面临多重挑战。首先,多模态数据的整合与标注过程复杂,涉及图像与文本的交错处理,要求高精度的跨模态对齐。其次,生物医学领域的数据获取难度大,部分数据源如MIMIC-CXR和Quilt需要特殊权限,增加了数据集构建的复杂性和时间成本。此外,数据集的多样性和覆盖范围也是一个挑战,确保不同医学领域的任务和数据源的广泛性,以提升模型的泛化能力。最后,数据集的规模和质量控制也是一大难题,如何在保证数据量的同时,确保每条数据的准确性和相关性,是MedMax团队必须克服的挑战。
常用场景
经典使用场景
MedMax数据集在多模态生物医学领域中展现了其独特的应用价值,尤其是在图像与文本的交错生成、生物医学图像的描述与生成、视觉对话以及报告理解等任务中。通过整合多种医学领域的数据源,如放射学和组织病理学,该数据集为训练生物医学助手提供了丰富的资源,使得模型能够在复杂的医学场景中进行精准的多模态信息处理。
解决学术问题
MedMax数据集有效解决了生物医学领域中多模态数据稀缺、领域覆盖狭窄以及数据来源受限等关键学术问题。通过提供大规模的多模态指令调优数据,该数据集为研究者提供了丰富的资源,推动了多模态模型在生物医学图像分析、诊断和数据生成等方面的研究进展,为生物医学AI的发展奠定了坚实的基础。
衍生相关工作
基于MedMax数据集,研究者们开发了多种多模态生物医学模型,如用于视觉问答(VQA)的模型、图像生成模型以及报告理解模型等。这些模型在生物医学图像分析、诊断辅助和医学教育等领域展现了显著的应用潜力。此外,MedMax还激发了更多关于多模态数据融合和指令调优的研究,推动了生物医学AI领域的技术创新和应用拓展。
以上内容由遇见数据集搜集并总结生成


