PlausibleQA
收藏arXiv2025-02-23 更新2025-02-26 收录
下载链接:
https://github.com/DataScienceUIBK/PlausibleQA
下载链接
链接失效反馈官方服务:
资源简介:
PlausibleQA是一个大规模的问题回答数据集,由因斯布鲁克大学创建。该数据集包含10,000个问题及每个问题的100个候选答案,每个答案都标注了可信度分数和选择理由。此外,数据集还提供了90万个候选答案之间的两两比较理由,用于进一步细化可信度评估。该数据集旨在为问答系统的研究和大型语言模型性能的提升提供资源,特别是在区分可信的干扰项和正确答案方面。
PlausibleQA is a large-scale question answering dataset created by the University of Innsbruck. It contains 10,000 questions along with 100 candidate answers for each question, where each answer is annotated with a credibility score and a justification for its selection. Additionally, the dataset provides pairwise comparison justifications between 900,000 candidate answers to further refine credibility assessments. This dataset aims to provide resources for research on question answering systems and the improvement of large language model performance, particularly in distinguishing between plausible distractors and correct answers.
提供机构:
因斯布鲁克大学
创建时间:
2025-02-23
搜集汇总
数据集介绍
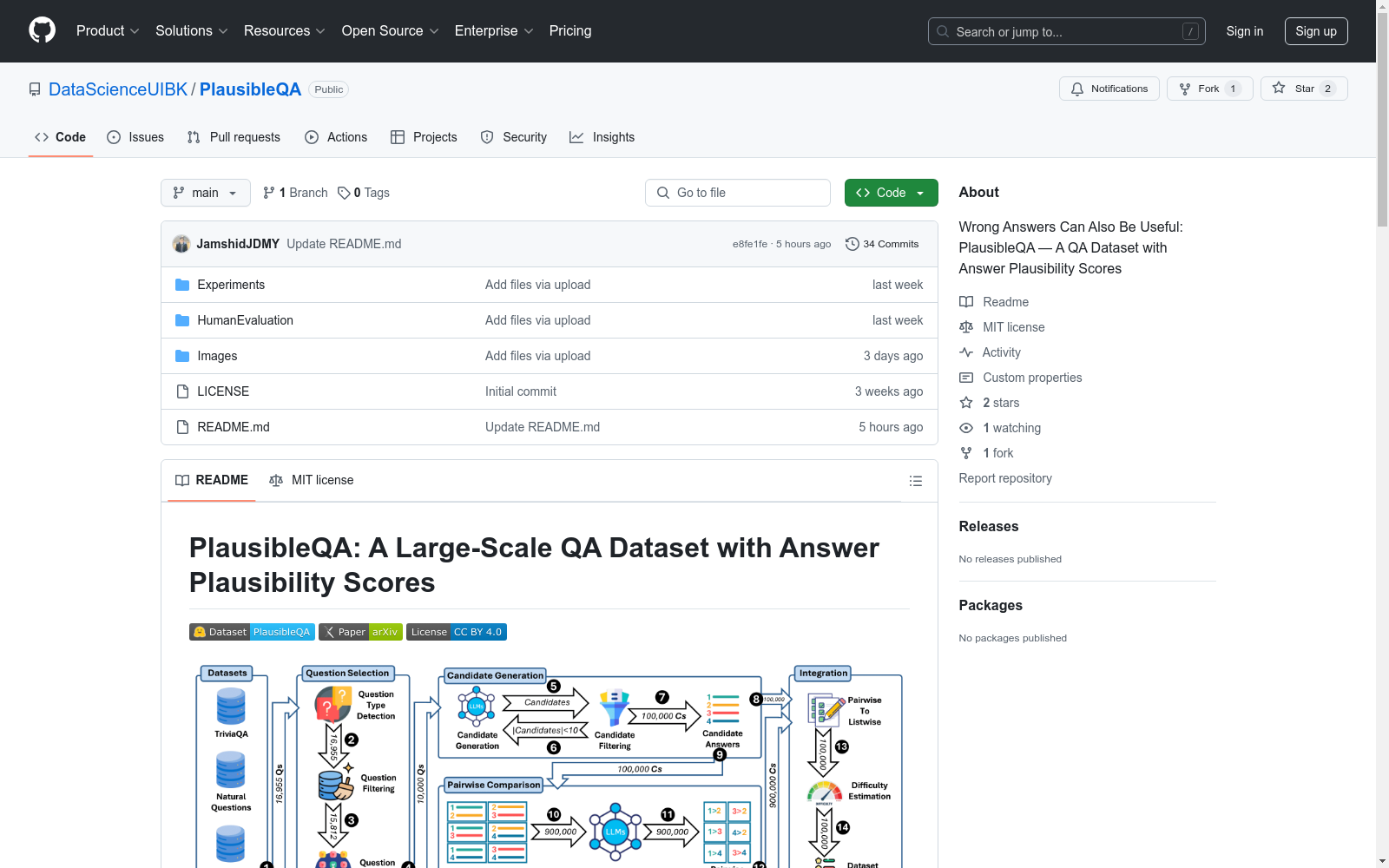
构建方式
PlausibleQA 数据集的构建主要分为三个模块:问题采样、候选答案生成和准备。首先,从 TriviaQA、Natural Questions 和 WebQuestions 三个 QA 数据集中采样 10,000 个问题。然后,使用 LLaMA-3.3-70B 语言模型生成每个问题的 10 个候选答案,并为其分配列表式可信度评分。接着,进行候选答案之间的成对比较,进一步细化可信度评估。最后,将问题、候选答案、列表式和成对比较的可信度评分以及相应的说明存储在 JSON 文件中,形成最终的 PlausibleQA 数据集。
特点
PlausibleQA 数据集具有以下特点:包含 10,000 个问题和 100,000 个候选答案;每个候选答案都标注了可信度评分和选择说明;还包括 900,000 个候选答案之间的成对比较说明;涵盖了各种难度级别的问题和答案;适用于 MCQA 和 QARA 等多种 QA 任务。
使用方法
使用 PlausibleQA 数据集的方法包括:在 MCQA 任务中生成具有不同难度级别的多选选项;在 QARA 任务中评估模型对高度可信但错误的答案的鲁棒性;在对比学习中改进负面示例选择;利用可信度评分估计问题难度;支持自动提示生成和评估研究。
背景与挑战
背景概述
随着大型语言模型(LLMs)在信息检索领域的革命性发展,聊天机器人已成为回答用户查询的重要来源。然而,LLMs设计上优先生成正确答案,而高度合理但错误的答案(候选答案)的价值往往被忽视。然而,这些答案仍然很有用,例如,它们在多项选择题回答(MCQA)和QA鲁棒性评估(QARA)等任务中发挥着关键作用。现有的QA数据集主要关注正确答案,而没有明确考虑其他候选答案的可信度,这限制了模型评估的机会。为了填补这一空白,我们介绍了PlausibleQA,这是一个包含10,000个问题和100,000个候选答案的大型数据集,每个候选答案都带有可信度分数和对选择理由的说明。此外,数据集还包括90万个候选答案之间的成对比较的说明,进一步细化了可信度评估。我们通过人工评估和实证实验评估了PlausibleQA,展示了它在MCQA和QARA分析中的实用性。我们的发现表明,具有可信度意识的策略对MCQA干扰项生成和QARA是有效的。我们发布PlausibleQA作为推进QA研究的资源,并增强LLMs区分合理干扰项和正确答案的性能。
当前挑战
PlausibleQA数据集的研究背景主要在于LLMs在生成候选答案时的局限性。尽管LLMs在生成流畅和语境适当的响应方面取得了显著进展,但它们通常只关注正确答案,而忽略了错误但合理的答案。这种二元的处理方式限制了模型评估的深度和准确性。PlausibleQA的创建旨在解决这一挑战,通过引入可信度分数,为评估模型提供了更精细的视角。在构建过程中,主要挑战包括如何生成高质量的候选答案、如何评估和量化候选答案的可信度,以及如何确保数据集的多样性和平衡性。此外,PlausibleQA还面临如何在实际应用中有效利用可信度分数的挑战,例如在MCQA中动态调整干扰项选择,以及在QARA中评估模型对错误答案的鲁棒性。
常用场景
经典使用场景
PlausibleQA 数据集被广泛应用于构建具有挑战性的多选题选项,特别是在需要评估问答系统鲁棒性的情况下。通过提供每个候选答案的可信度评分,PlausibleQA 使得研究人员能够生成各种难度的干扰项,从而更好地评估问答系统的性能。此外,该数据集还用于评估问答系统的鲁棒性,通过测量模型在拒绝高度可信但错误的答案方面的能力。
解决学术问题
PlausibleQA 数据集解决了现有问答数据集主要关注正确答案而忽视其他候选答案可信度的问题。通过提供可信度评分,该数据集使得研究人员能够更细致地评估问答模型,超越了传统的二元正确性框架,为模型推理提供了更深入的见解。此外,PlausibleQA 还为生成高质量的不正确答案提供了一个重要的资源,这对于多选题问答和问答系统鲁棒性评估等任务具有重要意义。
衍生相关工作
PlausibleQA 数据集的发布推动了问答领域的研究,衍生出了许多相关工作。例如,一些研究利用 PlausibleQA 数据集来评估问答系统的鲁棒性,并提出了改进模型鲁棒性的方法。此外,PlausibleQA 数据集还为生成高质量的不正确答案提供了一种新的思路,从而促进了多选题问答领域的研究。最后,该数据集还为自动提示生成和评估提供了重要的资源,帮助用户更好地理解问题。
以上内容由遇见数据集搜集并总结生成


