Orange/CoQAR
收藏Hugging Face2024-04-25 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Orange/CoQAR
下载链接
链接失效反馈官方服务:
资源简介:
CoQAR是一个包含4.5K对话的语料库,源自CoQA数据集,共有53K个后续问答对。每个原始问题都手动注释了至少2个最多3个上下文外的重写。CoQAR可用于至少三种NLP任务:问题释义、问题重写和对话式问答。数据集结构包括对话ID、轮次ID、原始问题、问题释义、答案、答案跨度开始、答案跨度结束、答案跨度文本、对话历史、文件名、故事和名称等字段。
CoQAR是一个包含4.5K对话的语料库,源自CoQA数据集,共有53K个后续问答对。每个原始问题都手动注释了至少2个最多3个上下文外的重写。CoQAR可用于至少三种NLP任务:问题释义、问题重写和对话式问答。数据集结构包括对话ID、轮次ID、原始问题、问题释义、答案、答案跨度开始、答案跨度结束、答案跨度文本、对话历史、文件名、故事和名称等字段。
提供机构:
Orange
原始信息汇总
数据集概述
数据集名称
CoQAR
数据集来源
- Repository: https://github.com/Orange-OpenSource/CoQAR/
- Paper: https://arxiv.org/abs/2207.03240
数据集描述
CoQAR是一个包含4.5K对话的语料库,源自Conversational Question-Answering dataset CoQA,总计53K个后续问答对。每个原始问题都手动标注了至少2个最多3个脱离上下文的改写。
语言
英语
数据集结构
数据集由多个对话组成,每行对应一个对话中的一个问题。字段包括:
- conversation_id
- turn_id
- original_question
- question_paraphrases
- answer
- answer_span_start
- answer_span_end
- answer_span_text
- conversation_history
- file_name
- story
- name
许可证信息
- 注释发布在CC-BY-SA 4.0许可证下。
- CoQA数据集的原始内容根据以下不同的许可证发布:
- 文学和维基百科段落共享在CC BY-SA 4.0许可证下。
- 儿童故事来自MCTest,带有MSR-LA许可证。
- 中学/高中考试段落来自RACE,带有自己的许可证。
- 新闻段落来自DeepMind CNN数据集,带有Apache许可证。
引用信息
@inproceedings{brabant-etal-2022-coqar, title = "{C}o{QAR}: Question Rewriting on {C}o{QA}", author = "Brabant, Quentin and Lecorv{e}, Gw{e}nol{e} and Rojas Barahona, Lina M.", booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference", month = jun, year = "2022", address = "Marseille, France", publisher = "European Language Resources Association", url = "https://aclanthology.org/2022.lrec-1.13", pages = "119--126" }
搜集汇总
数据集介绍
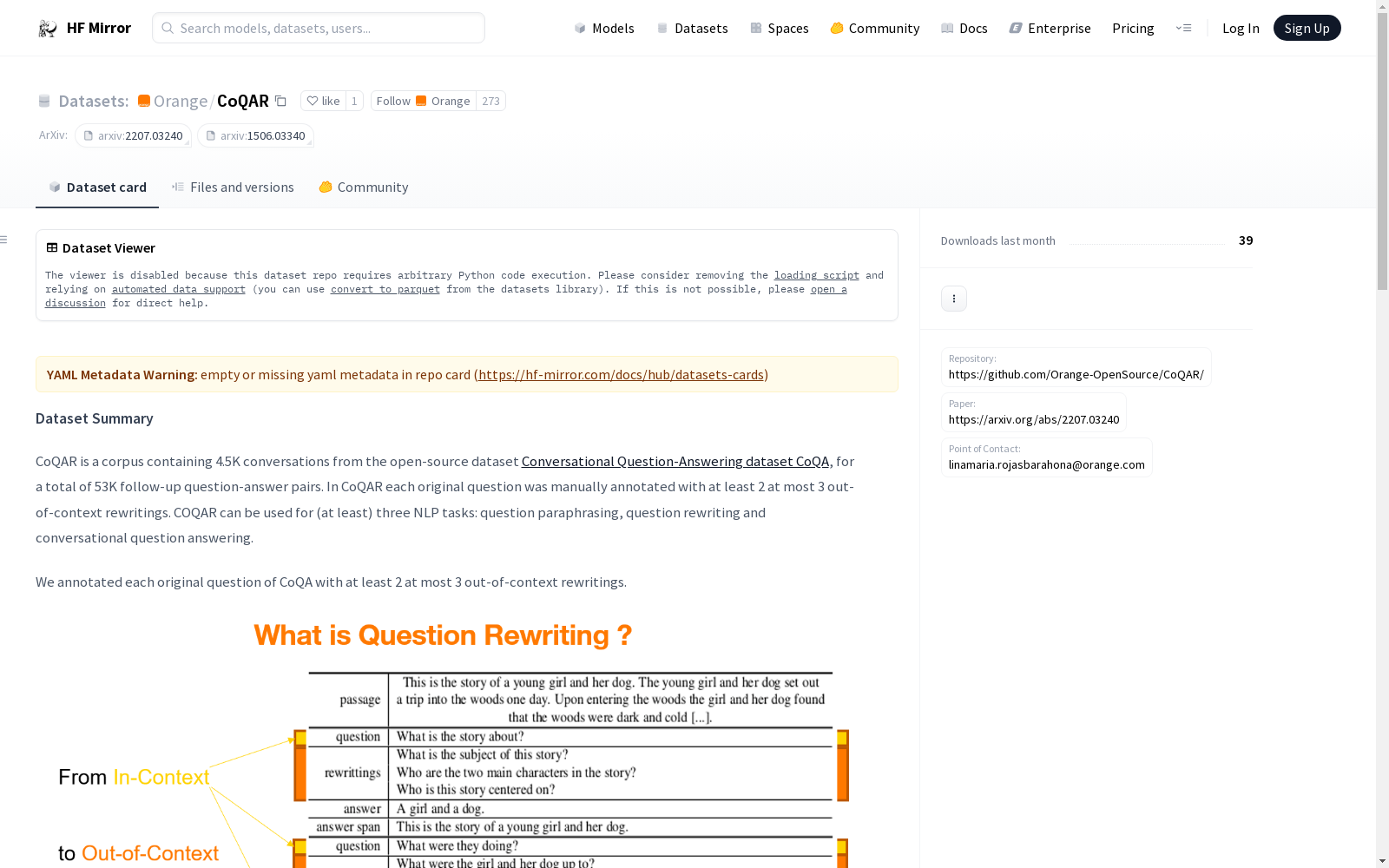
构建方式
CoQAR数据集的构建基于开源的对话式问题回答数据集CoQA,从中选取了4500场对话,共计53000个后续问题-答案对。每一原始问题均由人工标注至少两个至多三个脱离上下文的改写。
特点
CoQAR数据集具有英语语言的特性,专为自然语言处理任务而设计,包括问题释义、问题改写和对话式问题回答等。其独特之处在于对原始问题进行了脱离上下文的改写标注,为研究问题重写提供了丰富的资源。
使用方法
用户可以通过Hugging Face的库方便地加载CoQAR数据集,数据集的结构包括会话ID、对话轮次ID、原始问题、问题改写列表、答案、答案跨度、答案跨度文本、对话历史、文件名和故事上下文。使用者可以根据需要,针对不同的NLP任务进行相应的数据处理和分析。
背景与挑战
背景概述
CoQAR数据集,由Orange公司的研究人员Quentin Brabant、Gwénolé Lecorvé和Lina M. Rojas Barahona等于2022年创建,是一个基于Conversational Question-Answering (CoQA)数据集的语料库。CoQAR针对原始问题进行了人工标注,每个问题至少有两个、最多有三个脱离上下文的改写。该数据集旨在支持自然语言处理领域的三个任务:问题释义、问题改写和对话式问题回答。CoQAR的构建,丰富了对话式问答研究的数据资源,为相关模型训练与评估提供了新的基准。
当前挑战
在构建CoQAR数据集的过程中,研究人员面临的挑战主要包括:如何确保问题改写的质量和多样性,以适应不同的NLP任务;如何在保持数据一致性的同时,处理不同来源和许可证的原始内容;以及如何有效标注和记录问题的上下文信息,以利于后续的模型训练和应用。此外,数据集的多任务适应性也带来了任务间的平衡和优化问题,这需要研究人员进行深入的分析和模型设计上的创新。
常用场景
经典使用场景
在自然语言处理领域,CoQAR数据集因其独特的对话式问题回答特性而被广泛运用。该数据集以CoQA为基础,为每个原始问题提供了至少两个脱语境的改写,从而成为研究问题重写和问题释义的宝贵资源。在构建对话式问答系统时,CoQAR数据集提供了丰富的数据支持,有助于模型学习和优化。
解决学术问题
CoQAR数据集解决了学术研究中如何模拟真实对话环境中的问题多变性这一难题。通过提供问题的多种改写形式,该数据集帮助研究者分析和改进自然语言处理模型在处理语境变化和问题多样化方面的能力,从而推动对话式问答技术的发展。
衍生相关工作
CoQAR数据集的发布催生了一系列相关研究工作,包括对话系统的改进、问题重写技术的优化以及跨领域文本理解的探索。这些研究不仅加深了对话式问答的理论基础,也推动了自然语言处理技术的实际应用,为构建更加智能和人性化的对话系统提供了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


