AutomotiveUI-Bench-4K
收藏arXiv2025-05-09 更新2025-05-13 收录
下载链接:
https://huggingface.co/datasets/sparks-solutions/AutomotiveUI-Bench-4K
下载链接
链接失效反馈官方服务:
资源简介:
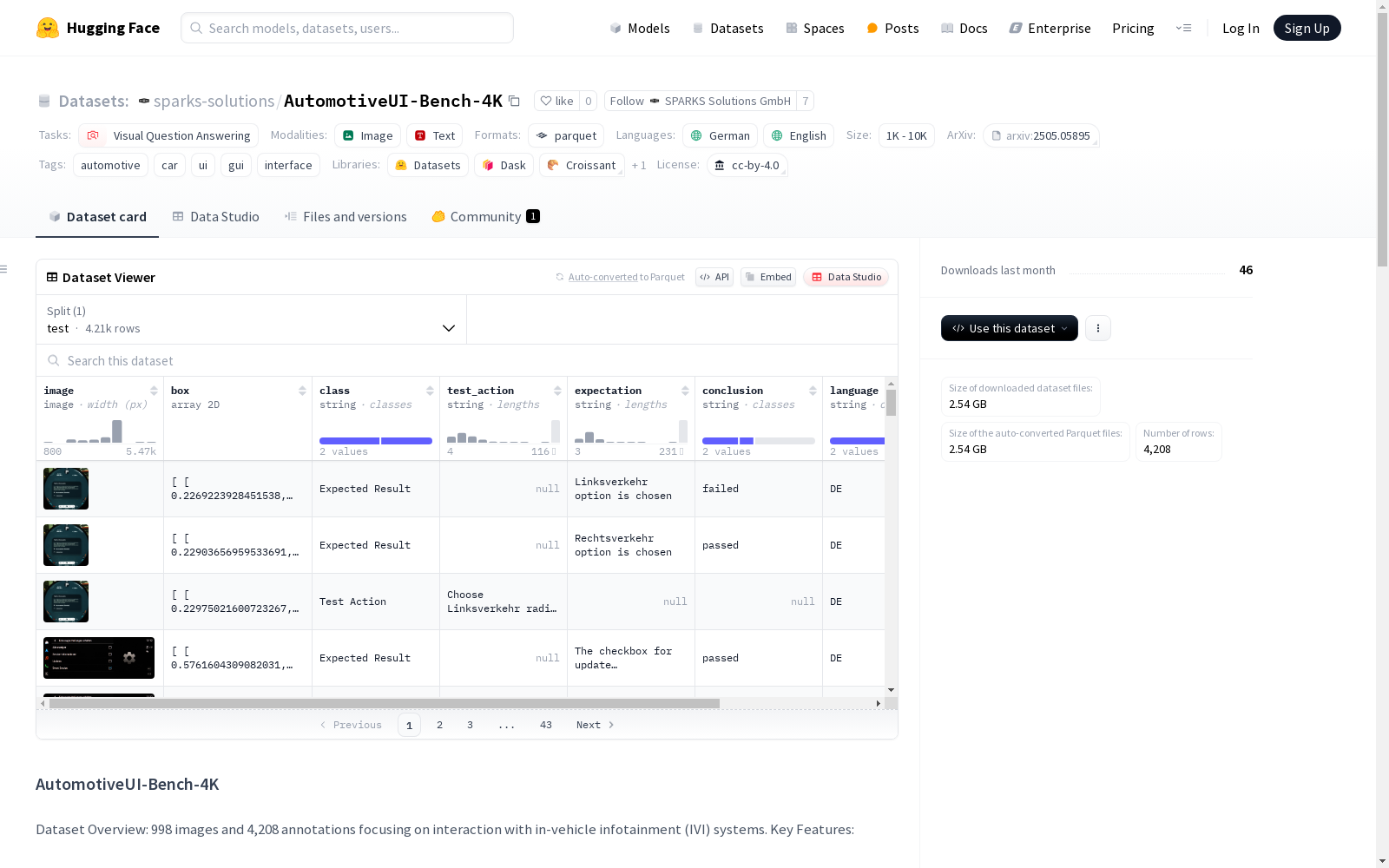
AutomotiveUI-Bench-4K是一个开源数据集,包含998张汽车娱乐系统界面图像,共有4,208个标注。该数据集旨在支持汽车娱乐系统界面的理解和交互研究,特别是帮助视觉语言模型在汽车领域的应用。数据集内容涵盖了不同的UI设计,包括自定义图标、菜单和交互范式。创建过程中使用了合成数据生成管道,通过自动化和人工标注相结合的方式,为模型训练提供了高质量的标注数据。该数据集的应用领域主要包括汽车人机界面(HMI)的理解和交互,旨在解决汽车娱乐系统界面更新频繁、设计多样化等问题。
AutomotiveUI-Bench-4K is an open-source dataset consisting of 998 images of in-car infotainment system interfaces and a total of 4,208 annotations. This dataset aims to support research on the understanding and interaction of in-car infotainment system interfaces, particularly to facilitate the application of vision-language models (VLMs) in the automotive domain. The dataset covers diverse UI designs, including custom icons, menus, and interaction paradigms. During its creation, a synthetic data generation pipeline was employed, and high-quality annotated data for model training was obtained through a combination of automated and manual annotation. The main application scenarios of this dataset include the understanding and interaction of automotive human-machine interfaces (HMIs), and it is designed to address issues such as frequent updates and diverse designs of in-car infotainment system interfaces.
提供机构:
SPARKS Solutions GmbH, Ingolstadt, Germany
创建时间:
2025-05-09
原始信息汇总
AutomotiveUI-Bench-4K 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 视觉问答
- 语言: 德语 (de)、英语 (en)
- 标签: automotive, car, ui, gui, interface
- 数据集大小: 10.8 GB
- 下载大小: 2.54 GB
数据集内容
- 图像数量: 998
- 标注数量: 4,208
- 数据分割: 仅测试集 (test),包含4,208个样本
关键特征
- 用途: 作为车载信息娱乐系统 (IVI) 交互的验证基准
- 覆盖范围: 15个汽车品牌/OEM,车型年份2018-2025
- 图像来源:
- 主要为IVI显示器的照片
- 部分直接截图 (如Android Auto)
标注信息
- 标注类别:
- 测试动作: 边界框 + 自然语言命令
- 预期结果: 边界框 + 自然语言预期结果 + 通过/失败状态
- 语言:
- IVI UI: 德语和英语
- 标注: 仅英语 (德语UI文本已翻译或引用)
品牌分布
| 品牌/OEM | 数量 |
|---|---|
| VW | 170 |
| Kia | 124 |
| Audi | 91 |
| Cupra | 85 |
| Porsche | 78 |
| Ford | 72 |
| Maserati | 72 |
| Mini | 60 |
| BMW | 59 |
| Peugot | 52 |
| Tesla | 51 |
| Toyota | 34 |
| Opel | 30 |
| Apple CarPlay | 13 |
| Google Android Auto | 7 |
模型性能
| 模型 | 测试动作定位 | 预期结果定位 | 预期结果评估 |
|---|---|---|---|
| InternVL2.5-8B | 26.6 | 5.7 | 64.8 |
| TinyClick | 61.0 | 54.6 | - |
| UGround-V1-7B | 69.4 | 55.0 | - |
| Molmo-7B-D-0924 | 71.3 | 71.4 | 66.9 |
| LAM-270M | 73.9 | 59.9 | - |
| ELAM-7B | 87.6 | 77.5 | 78.2 |
引用
latex @misc{ernhofer2025leveragingvisionlanguagemodelsvisual, title={Leveraging Vision-Language Models for Visual Grounding and Analysis of Automotive UI}, author={Benjamin Raphael Ernhofer and Daniil Prokhorov and Jannica Langner and Dominik Bollmann}, year={2025}, eprint={2505.05895}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2505.05895}, }
致谢
- 资助: 德国BMBF项目"KI4BoardNet"
搜集汇总
数据集介绍
构建方式
AutomotiveUI-Bench-4K数据集构建采用多源数据采集与专业标注相结合的方法,涵盖15个汽车品牌的998张4K分辨率信息娱乐系统界面图像。数据来源包括实车拍摄(经经销商授权)和CarPlay/Android Auto屏幕导出,通过透视校正确保界面元素标准化。标注过程由资深HMI测试工程师完成,采用双阶段标注体系:测试动作(2,269条)以祈使句描述交互指令,预期结果(1,939条)包含状态验证及通过/失败判定,特别设计564条失败案例以平衡数据分布。德语和英语界面分别保留原生语言特征,通过GPT-4o等教师模型生成推理链,再经小型模型复述以消除风格偏差。
使用方法
使用该数据集需遵循其双任务评估框架:对于测试动作任务,模型需根据自然语言指令定位对应UI元素坐标(如“将空调设为最大”);预期结果任务则要求模型验证界面状态是否符合描述(如“乘客温区与驾驶员同步-通过”)。基准测试建议采用点坐标包容性验证,即预测点落入标注边界框即为正确。数据集已按语言(英语/德语)分层,支持跨语言能力评估。为充分发挥其价值,建议配合论文提供的Prompt模板进行模型微调,重点提升对汽车专用控件(如ADAS设置)的语义理解能力。
背景与挑战
背景概述
AutomotiveUI-Bench-4K是由SPARKS Solutions GmbH的研究团队于2025年发布的开源数据集,专注于汽车信息娱乐系统(Infotainment Systems)的视觉与语言理解。该数据集包含998张高分辨率图像和4,208个标注,涵盖了15个汽车品牌的不同界面设计,旨在推动视觉语言模型(VLM)在汽车人机交互(HMI)领域的应用。研究团队通过合成数据生成管道和基于Molmo-7B的模型微调,显著提升了模型在跨域任务中的表现,如ScreenSpot任务中实现了5.2%的性能提升。这一工作填补了汽车UI领域基准数据集的空白,并为智能汽车界面的动态适应和语义理解提供了重要支持。
当前挑战
AutomotiveUI-Bench-4K面临的挑战主要包括两方面:领域问题的挑战和构建过程的挑战。在领域问题方面,汽车信息娱乐系统的UI设计具有高度异构性,不同品牌和车型的界面布局、图标语义和交互范式差异显著,要求模型具备强大的跨设计泛化能力。同时,复杂的交互场景需要模型不仅能定位UI元素,还需理解其功能状态和上下文关系。在构建过程中,数据标注面临对象级描述的复杂性,需融合功能、位置和视觉属性;合成数据与真实数据的语义鸿沟问题,以及人工标注中失败案例的认知偏差,均对数据质量提出了较高要求。此外,模型需在有限训练数据下实现高精度,并满足汽车行业对数据隐私和本地化部署的严格需求。
常用场景
经典使用场景
AutomotiveUI-Bench-4K数据集在汽车信息娱乐系统(Infotainment Systems)的研究中扮演着关键角色,尤其在视觉-语言模型(VLM)的开发和评估中。该数据集包含998张高分辨率图像和4,208个标注,涵盖了15个不同品牌的汽车信息娱乐界面,包括Apple CarPlay和Google Android Auto。研究人员利用这一数据集训练和优化模型,使其能够准确理解和交互复杂的汽车用户界面。通过提供多样化的UI设计和交互场景,AutomotiveUI-Bench-4K成为评估模型在视觉定位、语义理解和多语言处理能力方面的黄金标准。
解决学术问题
AutomotiveUI-Bench-4K解决了汽车信息娱乐系统研究中多个关键学术问题。首先,它填补了现有数据集在汽车UI领域的空白,为视觉-语言模型提供了专门的训练和测试平台。其次,该数据集支持对模型跨品牌、跨设计的泛化能力研究,解决了传统方法因UI动态更新和多语言支持不足而导致的性能下降问题。此外,通过引入合成数据生成管道,该数据集进一步推动了小规模模型(如7B参数模型)在有限资源下的高效微调技术,为学术界提供了低成本、高效益的研究方案。
实际应用
在实际应用中,AutomotiveUI-Bench-4K被广泛用于汽车信息娱乐系统的自动化测试和验证。例如,汽车制造商和供应商利用该数据集训练模型,以自动化执行功能测试用例,如检查界面元素的可见性、状态和交互逻辑。此外,该数据集还支持开发智能助手,帮助驾驶员通过自然语言指令操作信息娱乐系统,提升用户体验和安全性。其高精度的标注和多样化的场景覆盖,使得模型在实际车载环境中的表现更加可靠和鲁棒。
数据集最近研究
最新研究方向
随着智能座舱技术的快速发展,AutomotiveUI-Bench-4K数据集的发布为车载信息娱乐系统的人机交互研究提供了重要基准。该数据集聚焦于视觉语言模型在汽车UI领域的应用,特别是针对动态界面理解与交互的挑战。当前研究热点集中在三个方面:一是基于合成数据管道的参数高效微调方法,通过LoRa技术实现小规模VLM模型的性能提升;二是跨域泛化能力的探索,研究显示微调后的ELAM-7B模型在ScreenSpot基准上实现了5.2%的性能提升;三是多模态评估框架的构建,将视觉定位与自然语言推理相结合,以应对车载UI特有的图标语义理解难题。这些研究方向不仅推动了车载HMI测试技术的智能化转型,也为解决实际工程中频繁的OTA更新带来的界面适配问题提供了新思路。
相关研究论文
- 1Leveraging Vision-Language Models for Visual Grounding and Analysis of Automotive UISPARKS Solutions GmbH, Ingolstadt, Germany · 2025年
以上内容由遇见数据集搜集并总结生成


