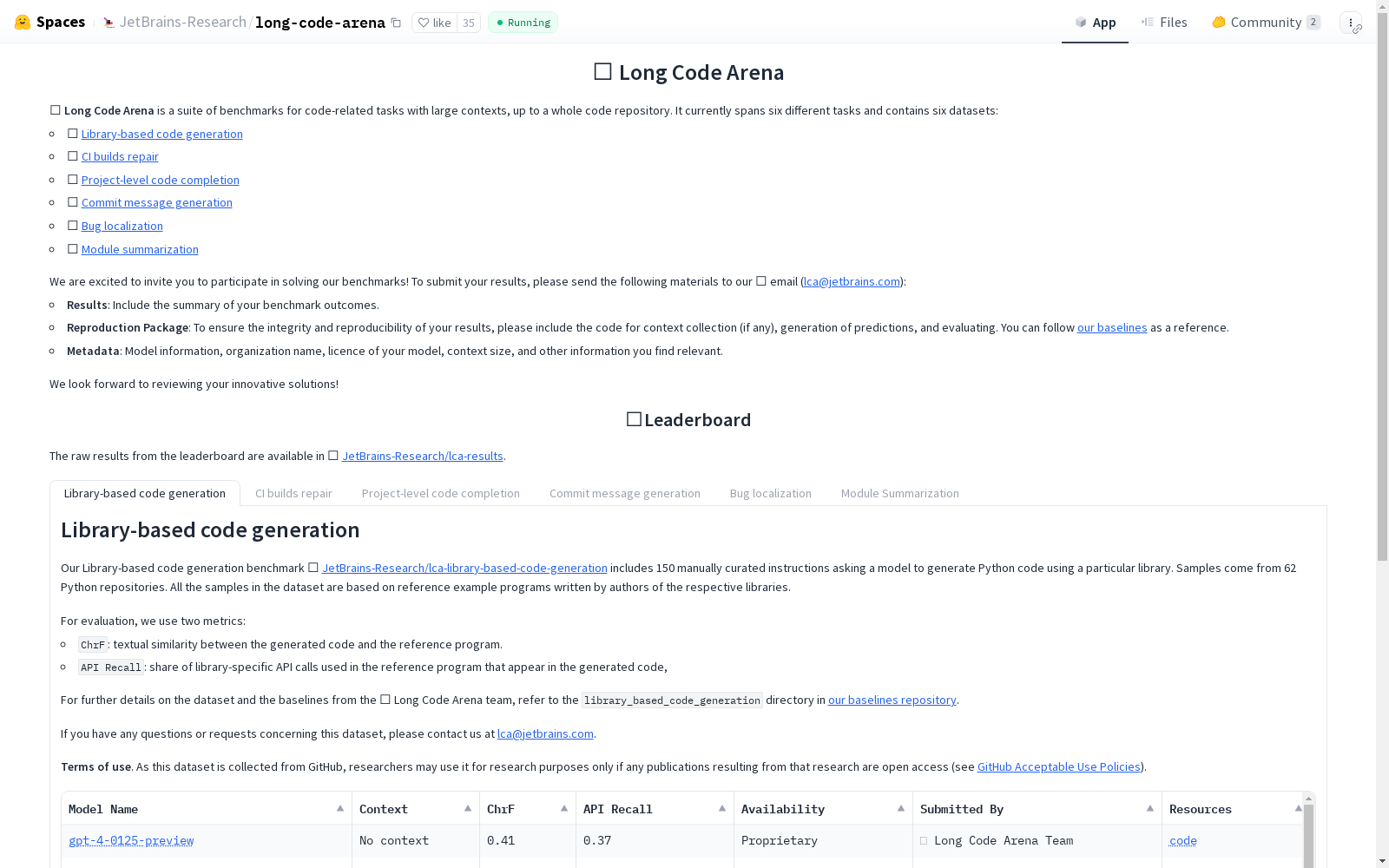
Long Code Arena
收藏arXiv2024-06-17 更新2024-06-19 收录
下载链接:
https://huggingface.co/spaces/JetBrains-Research/long-code-arena
下载链接
链接失效反馈官方服务:
资源简介:
Long Code Arena是由捷德布莱恩斯研究和德尔福特理工大学联合开发的一套包含六个数据集的基准,旨在评估需要项目级上下文的代码处理模型。这些数据集涵盖了代码生成、修复、完成、摘要、处理差异等多个方面,数据来源于开放源代码的GitHub仓库,确保了数据的质量和多样性。创建过程中,数据经过严格的筛选和人工验证,以保证其准确性。该数据集主要应用于机器学习在软件工程领域的研究,特别是在需要长上下文处理的代码模型评估中,解决了现有基准在上下文长度和实际应用案例相似性方面的局限性。
Long Code Arena is a benchmark suite composed of six datasets, co-developed by Jed Bryans Research and Delft University of Technology. It is designed to evaluate code processing models that necessitate project-level context. These datasets cover a wide range of tasks including code generation, code repair, code completion, code summarization, and diff processing. All data is sourced from open-source GitHub repositories, which guarantees both the quality and diversity of the benchmark. During its development, the data underwent rigorous screening and manual validation to ensure its accuracy. This benchmark is primarily used for machine learning research in the field of software engineering, especially for evaluating code models that require long-context processing, and it addresses the limitations of existing benchmarks regarding context length and similarity to real-world application scenarios.
提供机构:
捷德布莱恩斯研究
创建时间:
2024-06-17
搜集汇总
数据集介绍
构建方式
Long Code Arena 数据集的构建基于从 GitHub 上收集的开源仓库数据,涵盖了代码生成、修复、补全、总结等多个任务。首先,通过 GitHub API 获取符合条件的仓库列表,筛选出具有至少 1,000 次提交、10 个贡献者、10,000 行代码且使用宽松许可证的仓库。随后,针对每个任务,进一步过滤数据并手动验证样本的正确性。例如,在库代码生成任务中,从仓库中提取使用示例,并通过 GPT-4 生成生成指令,最终形成包含 150 个样本的数据集。
使用方法
Long Code Arena 数据集的使用方法包括通过 HuggingFace Spaces 访问数据集和排行榜,并通过 GitHub 仓库获取基线模型的代码。研究人员可以使用这些基线模型进行任务评估,并根据任务需求调整模型输入和上下文。例如,在库代码生成任务中,模型需要根据自然语言指令生成代码,并利用库的上下文信息。数据集还提供了详细的评估代码,帮助研究人员在本地或云端运行基准测试。
背景与挑战
背景概述
Long Code Arena 是由 JetBrains Research 和 Delft University of Technology 的研究团队于2024年6月发布的一个基准测试套件,旨在解决代码处理任务中长上下文窗口的挑战。随着自然语言处理和代码处理模型的快速发展,模型支持的上下文窗口大小在过去几年中显著增加,然而,现有的代码处理基准测试大多局限于单个文件或方法的上下文。Long Code Arena 通过引入六个基准测试任务,填补了这一空白,涵盖了库驱动的代码生成、CI构建修复、项目级代码补全、提交信息生成、错误定位和模块摘要等任务。每个任务都提供了手动验证的数据集、评估套件以及基于流行大语言模型的开源基线解决方案,以简化其他研究人员的采用。该数据集的主要目标是评估模型在处理项目级上下文时的能力,推动机器学习在软件工程中的应用。
当前挑战
Long Code Arena 面临的挑战主要包括两个方面:首先,现有的代码处理基准测试大多局限于短上下文,无法充分评估模型在处理长上下文时的表现。其次,构建过程中需要处理大量的开源代码库,确保数据的质量和多样性。具体挑战包括:1) 在库驱动的代码生成任务中,模型需要生成基于自然语言指令的代码,并充分利用给定的库,这对模型的上下文理解和生成能力提出了较高要求;2) 在CI构建修复任务中,模型需要根据失败的构建日志生成修复补丁,并确保补丁的正确性,这对模型的代码理解和修复能力提出了挑战;3) 在项目级代码补全任务中,模型需要利用项目的完整上下文进行代码补全,避免数据泄露问题,这对模型的上下文管理和补全能力提出了较高要求。
常用场景
经典使用场景
Long Code Arena 数据集主要用于评估长上下文代码模型在处理项目级代码任务时的表现。该数据集涵盖了六个不同的代码处理任务,包括基于库的代码生成、CI构建修复、项目级代码补全、提交信息生成、错误定位和模块摘要生成。每个任务都提供了手动验证的测试数据集、评估套件以及基于流行大语言模型的开源基线解决方案,以展示数据集的使用方式并简化其他研究者的采用。
解决学术问题
Long Code Arena 解决了现有代码处理基准的两个主要局限性:上下文长度短和实际用例的有限相似性。通过引入项目级上下文的任务,该数据集使得模型能够在处理整个软件项目时利用更多的信息,从而更好地模拟现实中的软件开发场景。此外,该数据集还提供了多种任务的评估,帮助研究者更好地理解模型在不同代码处理任务中的表现。
实际应用
Long Code Arena 的实际应用场景包括自动化代码生成、持续集成构建修复、项目级代码补全、提交信息生成、错误定位和模块摘要生成。这些任务在软件开发中非常常见,能够显著提高开发效率和质量。例如,CI构建修复任务可以帮助开发者快速修复构建失败的问题,而模块摘要生成任务则可以自动生成项目文档,减少开发者的文档编写负担。
数据集最近研究
最新研究方向
近年来,随着代码和自然语言处理领域的快速发展,模型在处理长上下文窗口方面取得了显著进展。然而,现有的代码处理基准大多局限于单个文件或方法的上下文,难以评估模型在项目级上下文中的表现。为此,Long Code Arena 应运而生,它提供了一套包含六个基准任务的代码处理基准,涵盖了库驱动的代码生成、CI构建修复、项目级代码补全、提交信息生成、缺陷定位和模块摘要生成等任务。这些任务要求模型利用整个项目或模块的上下文信息,从而更贴近实际开发场景。Long Code Arena 的推出填补了这一领域的空白,为评估长上下文代码模型提供了重要的工具。该数据集不仅提供了手动验证的测试数据,还开源了基于流行大语言模型的基线解决方案,旨在简化研究人员的采用过程。通过 HuggingFace Spaces 上的排行榜和数据集链接,Long Code Arena 为研究人员提供了一个开放的实验平台,推动了长上下文代码处理模型的研究与发展。
相关研究论文
- 1Long Code Arena: a Set of Benchmarks for Long-Context Code Models捷德布莱恩斯研究 · 2024年
以上内容由遇见数据集搜集并总结生成


