yuhuanstudio/PTT-pretrain-zhtw
收藏Hugging Face2025-04-01 更新2025-02-15 收录
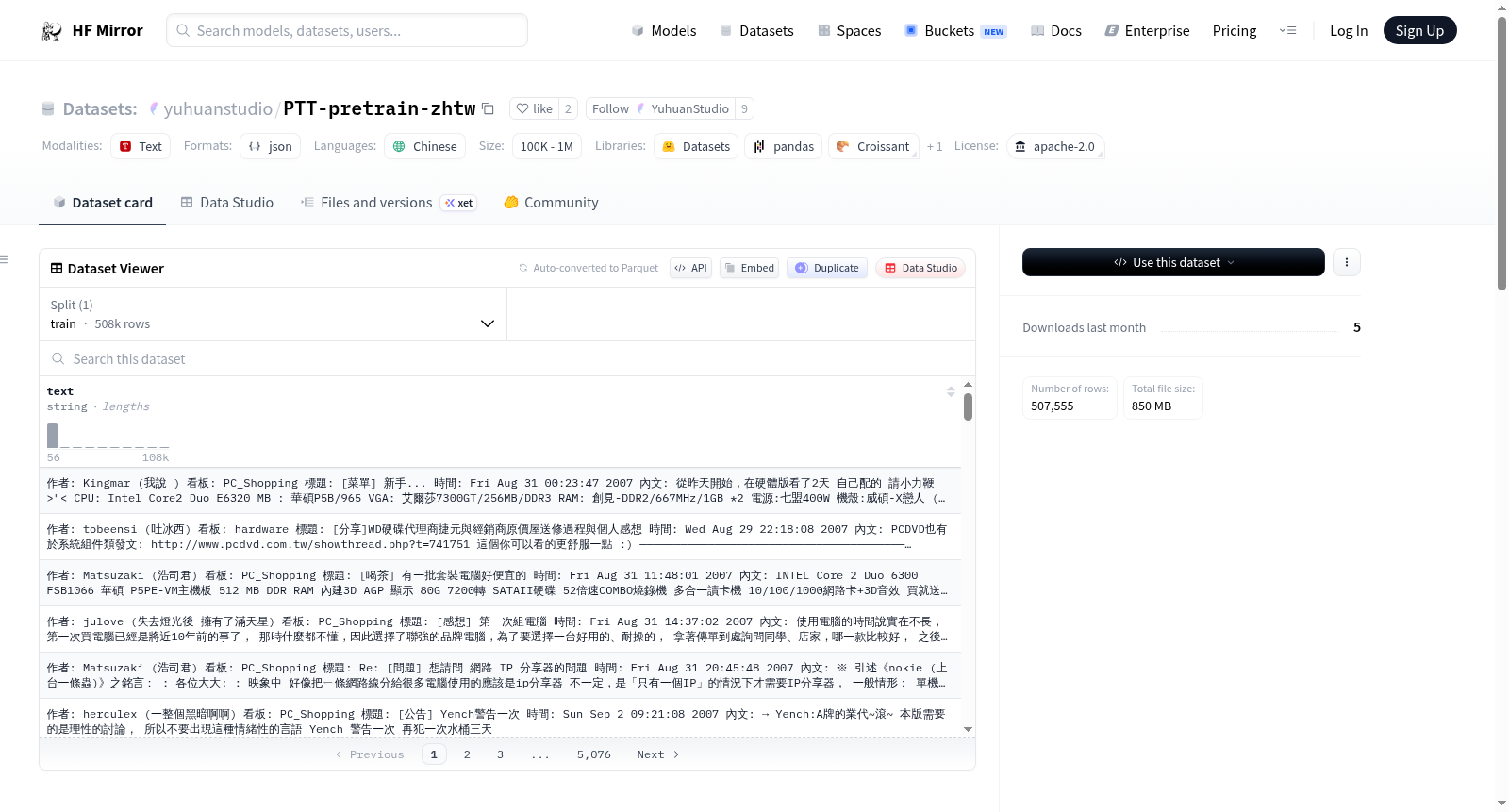
下载链接:
https://hf-mirror.com/datasets/yuhuanstudio/PTT-pretrain-zhtw
下载链接
链接失效反馈官方服务:
资源简介:
本数据集是从台湾最大的BBS讨论区PTT获取的繁体中语文料,包含了Gossiping、Tech_Job、Stock、NBA等多个讨论区的历史与近期讨论内容,适合用于大型语言模型预训练和自然语言处理研究。
This dataset is a collection of Traditional Chinese text from the largest BBS forum in Taiwan, PTT, including historical and recent discussions from boards such as Gossiping, Tech_Job, Stock, NBA, etc., suitable for large-scale language model pre-training and natural language processing research.
提供机构:
yuhuanstudio
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,获取高质量且具代表性的语料是模型预训练的关键。本数据集源自台湾最大的BBS论坛——批踢踢实业坊(PTT),通过系统性地爬取该平台公开存档的前200页数据构建而成。数据覆盖了包括Gossiping、Tech_Job、Stock、NBA在内的所有讨论区,时间跨度长达多年,确保了语料的广泛性和历史深度。最终,这些包含作者、看板、标题、时间及内文的讨论内容被整理为结构化的JSON格式,为后续的模型训练提供了坚实的数据基础。
使用方法
为便于研究与应用,本数据集已集成于Hugging Face的`datasets`库中。使用者可通过简单的Python代码`load_dataset("yuhuanstudio/PTT-pretrain-zhtw", split="pretrain")`直接加载数据,并利用其进行大型语言模型的预训练或下游自然语言处理任务的微调。鉴于数据源自公开网络论坛,内容可能包含不当言论,建议使用者在应用前进行必要的清洗与过滤,并严格遵守数据集的版权声明,仅将其用于学术研究或个人学习等非商业用途。
背景与挑战
背景概述
在自然语言处理领域,高质量、大规模的中文语料库对于推动语言模型的发展至关重要。yuhuanstudio/PTT-pretrain-zhtw数据集由yuhuanstudio团队构建,旨在为大型语言模型的预训练提供丰富的繁体中文资源。该数据集源自台湾最大的BBS讨论区——批踢踢实业坊(PTT),汇集了包括Gossiping、Tech_Job、Stock、NBA等多个看板的历史与近期讨论内容,时间跨度覆盖多年,数据规模达数十万条贴文与回应。其核心研究问题聚焦于如何利用真实、多样的网络社区语料来提升语言模型对繁体中文的理解与生成能力,尤其在捕捉口语化、领域特定表达方面具有独特价值,对促进中文自然语言处理技术的进步产生了积极影响。
当前挑战
该数据集旨在解决自然语言处理中繁体中文语料稀缺的挑战,特别是在预训练语言模型时,需要大量真实、多样化的文本以捕捉语言的社会文化语境和动态演变。然而,构建过程面临多重困难:PTT作为用户生成内容平台,数据中可能包含不恰当言论或噪声,对语料清洗和质量控制提出了较高要求;各讨论区页面存档不均衡,导致热门版面数据时间分布偏旧,可能影响语料的时效性和代表性;同时,需严格遵守版权法规,确保数据使用仅限于学术研究,这增加了数据采集与分发的合规复杂性。这些挑战共同制约了数据集的广泛应用与模型性能的进一步提升。
常用场景
经典使用场景
在自然语言处理领域,繁体中文语料资源相对稀缺,尤其缺乏反映真实社会互动与口语化表达的文本。yuhuanstudio/PTT-pretrain-zhtw数据集恰好填补了这一空白,其经典使用场景集中于大型语言模型的预训练阶段。研究者利用该数据集包含的数十万条PTT论坛贴文与回应,能够有效训练模型理解和生成贴近台湾地区日常用语习惯的繁体中文文本,为后续的微调任务奠定坚实的语言基础。
解决学术问题
该数据集主要解决了自然语言处理研究中针对繁体中文的模型泛化能力不足、对网络用语及口语化表达理解薄弱等常见学术问题。通过提供大规模、多样化的真实用户生成内容,它使得模型能够学习到标准书面语之外丰富的语言变体与语境信息,显著提升了模型在理解台湾地区社会文化语境下的语言细微差别和情感倾向方面的性能,对推动更具包容性和地域适应性的中文NLP研究具有重要意义。
实际应用
在实际应用层面,基于该数据集训练的模型能够服务于多种面向台湾市场的智能化产品。例如,可以应用于社交媒体内容的情感分析、自动摘要生成,或是构建更贴合本地用户语言习惯的智能客服与聊天机器人。这些应用能够更精准地处理包含大量网络用语、特定社群文化指涉的文本,提升人机交互的自然度与有效性,为相关技术产品在特定区域的落地提供了关键的语言资源支持。
数据集最近研究
最新研究方向
在自然语言处理领域,繁体中文语料资源的稀缺性长期制约着相关模型的发展。yuhuanstudio/PTT-pretrain-zhtw数据集的推出,为基于社群对话的预训练任务提供了关键支持。当前研究前沿聚焦于利用此类富含口语化表达与领域术语的语料,提升大型语言模型在繁体中文语境下的语义理解与生成能力。特别是在社会舆情分析、跨文化语言模型适应性微调以及低资源方言处理等热点方向上,该数据集通过捕捉台湾地区网络社群的真实语言动态,为模型的本土化与场景化应用奠定了数据基础。其影响在于促进了中文自然语言处理技术的多元化发展,对推动区域性人工智能解决方案具有显著的学术与实用价值。
以上内容由遇见数据集搜集并总结生成


