SYNTHLLM
收藏arXiv2025-03-25 更新2025-03-28 收录
下载链接:
http://arxiv.org/abs/2503.19551v1
下载链接
链接失效反馈官方服务:
资源简介:
SYNTHLLM是一个可扩展的框架,能够将预训练语料库转化为多样化、高质量的合成数据集。该数据集通过自动提取和重组合多个文档中的高级概念,使用图算法在不同领域(如数学推理)生成合成数据。研究结果表明,SYNTHLLM生成的合成数据遵循修正的扩展规律,性能提升在达到3000亿个token后趋于平稳,且大型模型在较少的训练token数下即可达到最佳性能。
SYNTHLLM is a scalable framework that transforms pre-trained corpora into diverse, high-quality synthetic datasets. It automatically extracts and recombines high-level concepts from multiple documents, and leverages graph algorithms to generate synthetic data across various domains such as mathematical reasoning. Research findings demonstrate that the synthetic data generated by SYNTHLLM follows a modified scaling law, with performance improvements plateauing after reaching 300 billion tokens, and large models can achieve optimal performance with fewer training tokens.
提供机构:
微软
创建时间:
2025-03-25
搜集汇总
数据集介绍
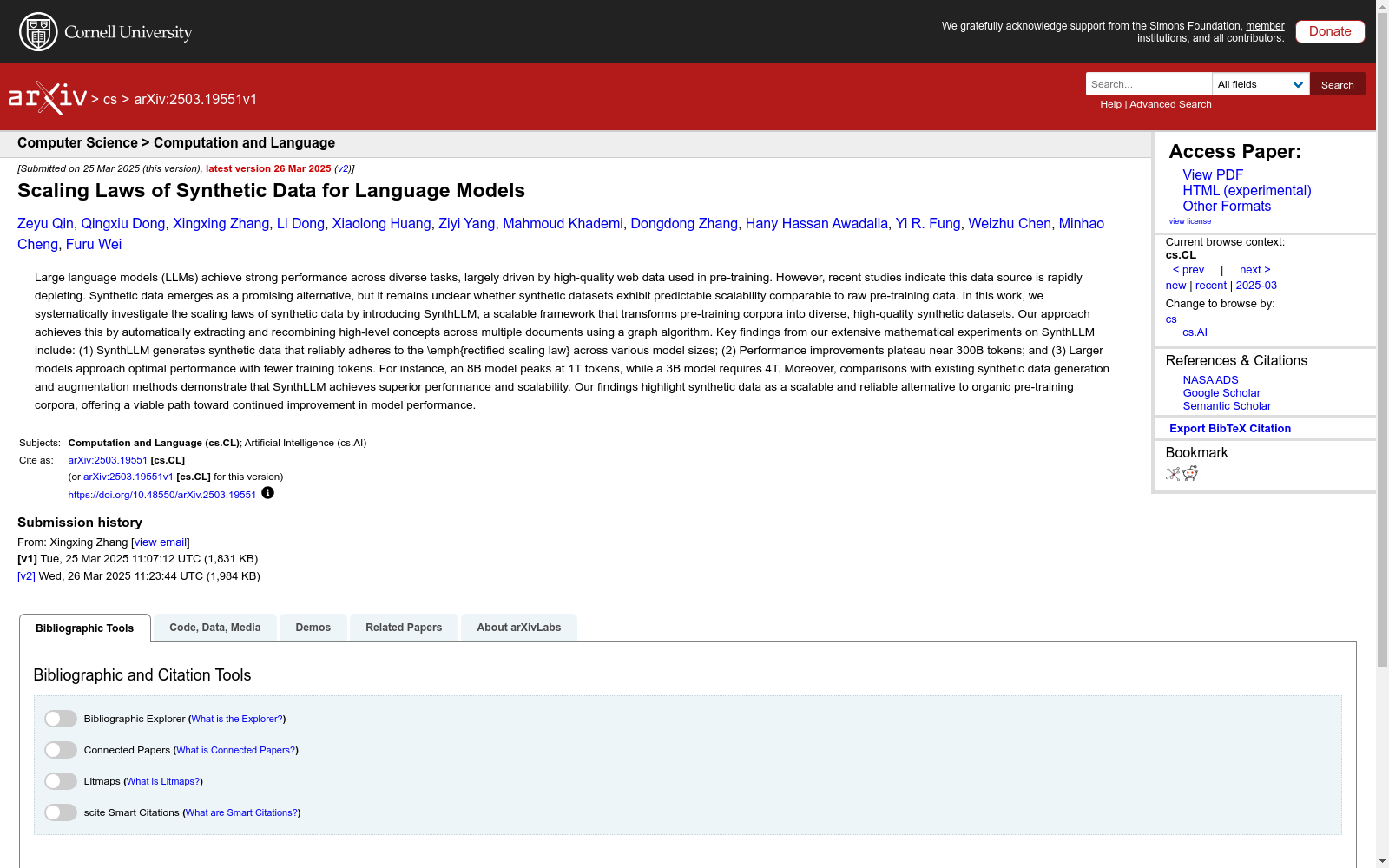
构建方式
SYNTHLLM数据集的构建采用了创新的三阶段流程,通过图算法实现知识概念的跨文档重组。首先从Fineweb-Edu语料库中筛选高质量领域文档,训练基于随机森林的冷启动分类器和细粒度分类器进行文档质量过滤;随后通过三级递进式问题生成机制:基础级直接提取文档问题,进阶级基于单文档概念重组生成问题,专家级构建全局知识图谱实现跨文档概念组合;最后利用开源大模型生成对应答案,形成完整的问答对。这种构建方式突破了传统合成数据对人工种子数据的依赖,实现了基于预训练语料库的规模化知识重组。
特点
该数据集具有显著的规模可扩展性与知识重组特性,其数学推理领域包含740万高质量样本,问题长度中位数达80词。核心特征体现在:严格遵循修正版缩放定律,性能提升在300B标记处达到平台期;通过概念图谱实现知识点的跨文档关联重组,使相同文档的问题相似度降低42%;支持模型尺寸敏感的缩放规律,8B模型在1T标记时即达最优性能。相比传统方法,SYNTHLLM在MATH基准上使3B模型准确率提升12.5%,且展现出优异的跨领域泛化能力。
使用方法
使用SYNTHLLM需遵循知识引导的微调范式:建议采用1e-5学习率的AdamW优化器,批量大小512,训练3个epoch。对于不同规模模型,8B参数模型推荐1T训练标记量,3B模型需4T标记以达到性能饱和。在数学推理任务中,该数据集可使Llama-3.2-3B在GSM8K和MATH基准分别提升至80.7%和60%准确率。使用者可通过调节概念组合的随机游走步长(1-4步)控制问题多样性,并利用Jaccard相似度实现多文档知识关联。
背景与挑战
背景概述
SYNTHLLM是由微软、香港科技大学、北京大学和宾夕法尼亚州立大学的研究团队于2025年提出的一个可扩展的合成数据生成框架,旨在解决大规模语言模型预训练数据源枯竭的问题。该数据集通过图算法自动提取和重组多个文档中的高级概念,将预训练语料库转化为多样化的高质量合成数据。SYNTHLLM的核心研究问题是探索合成数据是否遵循与原始预训练数据相似的扩展规律,以及如何利用合成数据持续提升模型性能。这一研究为语言模型的发展提供了新的数据来源,对自然语言处理领域具有重要意义。
当前挑战
SYNTHLLM面临的挑战主要包括两个方面:首先,在领域问题方面,该数据集旨在解决数学推理等复杂任务的性能提升问题,但如何确保合成数据的多样性和质量以覆盖广泛的数学概念和应用场景是一个关键挑战;其次,在构建过程中,研究人员需要克服从有限的高质量参考文档中提取足够多知识概念的困难,以及设计有效的算法来重组这些概念以生成新颖且具有挑战性的问题。此外,验证合成数据是否真正遵循扩展规律,以及如何确定最佳的数据规模以避免性能饱和,也是构建过程中需要解决的重要技术难题。
常用场景
经典使用场景
SYNTHLLM数据集在自然语言处理领域中被广泛用于研究大语言模型(LLMs)的预训练和微调过程。特别是在数学推理任务中,该数据集通过生成多样化的数学问题和解答,为模型提供了丰富的训练材料。研究人员利用SYNTHLLM来探索模型在不同规模数据下的表现,验证数据扩展对模型性能的影响。
衍生相关工作
SYNTHLLM数据集衍生了一系列关于合成数据生成和扩展规律的研究工作。例如,基于该数据集的研究提出了新的数据生成方法,如知识图谱引导的问题生成技术。同时,SYNTHLLM也启发了对多领域合成数据扩展规律的探索,推动了语言模型在医疗、物理等专业领域的发展。
数据集最近研究
最新研究方向
在大型语言模型(LLMs)预训练数据资源日益枯竭的背景下,SYNTHLLM数据集通过创新的图算法实现了预训练语料向多样化合成数据的高效转化,为数学推理等领域提供了可扩展的解决方案。最新研究表明,该数据集生成的合成数据严格遵循修正后的缩放定律,且在300B标记量附近呈现性能提升饱和现象。值得注意的是,较大规模模型能以更少训练标记接近最优性能,如8B模型在1T标记时即达峰值,而3B模型需4T标记。与现有合成数据生成方法相比,SYNTHLLM展现出卓越的性能可预测性和规模扩展性,为缓解人类生成数据依赖提供了新范式。当前研究热点集中于将该框架扩展至代码生成、物理化学等多元领域,并探索其在持续预训练阶段的适用性。
相关研究论文
- 1Scaling Laws of Synthetic Data for Language Models微软 · 2025年
以上内容由遇见数据集搜集并总结生成


