reddit_dataset_157
收藏Hugging Face2025-03-29 更新2025-03-30 收录
下载链接:
https://huggingface.co/datasets/tensorshield/reddit_dataset_157
下载链接
链接失效反馈官方服务:
资源简介:
Bittensor Subnet 13 Reddit数据集是一个包含预处理后的Reddit数据的数据集,由Bittensor Subnet 13去中心化网络中的矿工持续更新,提供实时的Reddit内容流,用于各种分析和机器学习任务。
创建时间:
2025-03-28
原始信息汇总
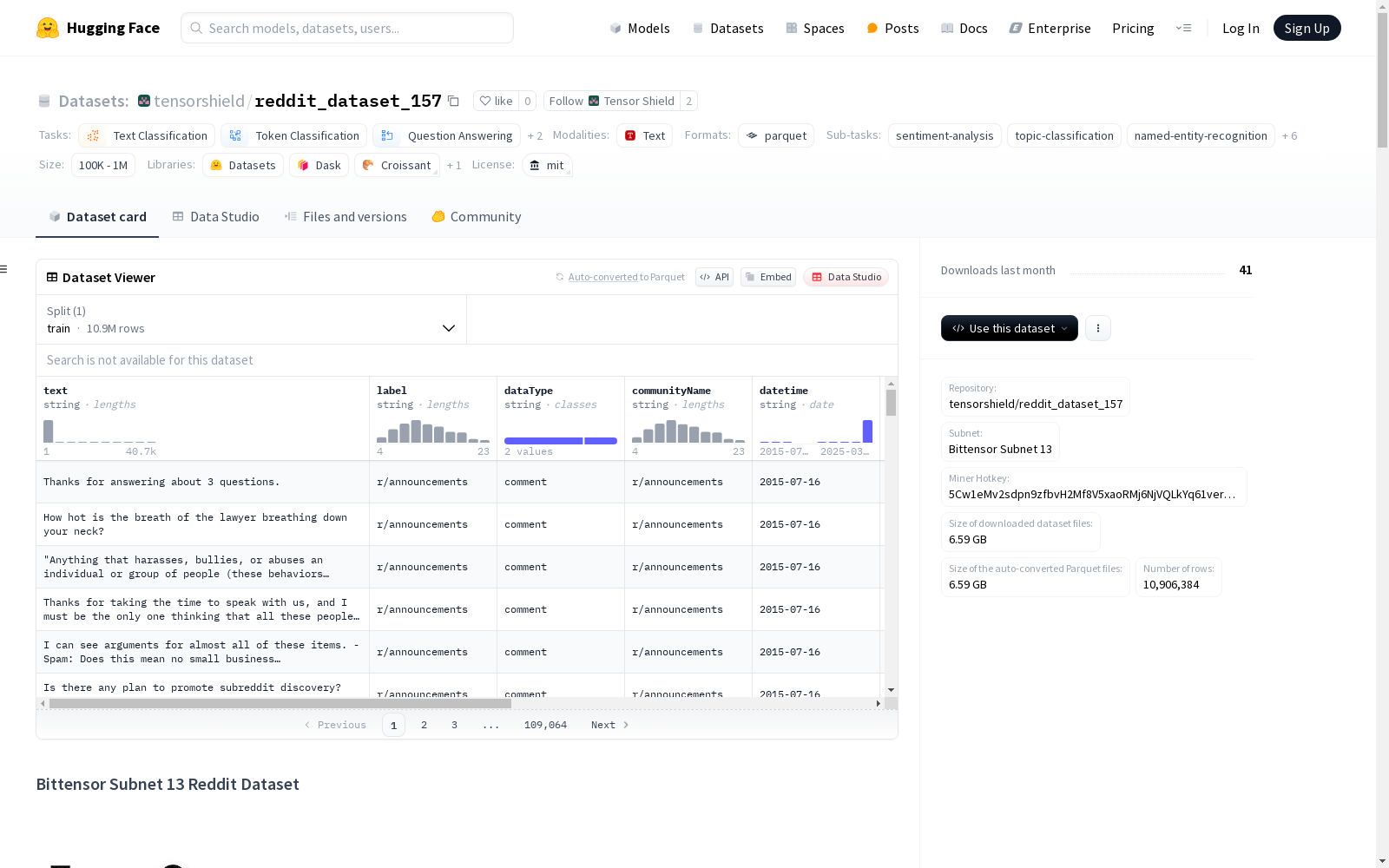
数据集概述:Bittensor Subnet 13 Reddit Dataset
基本信息
- 数据集名称: Bittensor Subnet 13 Reddit Dataset
- 数据集仓库: tensorshield/reddit_dataset_157
- 许可证: MIT
- 多语言支持: 主要英语,可能包含多语言内容
- 数据来源: 原始数据(Reddit公开帖子和评论)
数据集摘要
- 子网: Bittensor Subnet 13
- 矿工热键: 5Cw1eMv2sdpn9zfbvH2Mf8V5xaoRMj6NjVQLkYq61verzNbq
- 数据更新: 由网络矿工持续更新,提供实时Reddit内容流
支持任务
- 文本分类
- 标记分类
- 问答系统
- 文本摘要
- 文本生成
- 情感分析
- 主题分类
- 命名实体识别
- 语言建模
- 文本评分
- 多类分类
- 多标签分类
- 抽取式问答
- 新闻文章摘要
数据集结构
数据实例
每个实例代表一个Reddit帖子或评论。
数据字段
text: 帖子或评论的主要内容label: 内容的情感或主题类别dataType: 帖子或评论的类型communityName: 发布内容的子版块名称datetime: 内容发布时间username_encoded: 编码后的用户名(保护隐私)url_encoded: 编码后的URL(保护隐私)
数据分割
数据集持续更新,无固定分割,用户需根据需求自行分割。
数据集创建
来源数据
数据收集自Reddit的公开帖子和评论,遵循平台的服务条款和API使用指南。
隐私保护
所有用户名和URL均经过编码处理,不包含个人或敏感信息。
使用注意事项
社会影响与偏见
数据集可能包含Reddit固有的偏见,不代表一般人群的观点。
局限性
- 数据质量可能因来源不同而有所差异
- 可能包含噪音、垃圾或无关内容
- 可能存在时间偏差
- 仅包含公开子版块内容
附加信息
引用信息
@misc{tensorshield2025datauniversereddit_dataset_157, title={The Data Universe Datasets: The finest collection of social media data the web has to offer}, author={tensorshield}, year={2025}, url={https://huggingface.co/datasets/tensorshield/reddit_dataset_157}, }
数据集统计
- 总实例数: 1,775,956
- 日期范围: 2015-07-16T00:00:00Z 至 2025-03-03T00:00:00Z
- 最后更新时间: 2025-03-29T20:32:17Z
- 数据分布:
- 帖子: 81.72%
- 评论: 18.28%
热门子版块
- r/announcements: 122,166 (6.88%)
- r/blackmagicfuckery: 42,640 (2.40%)
- r/place: 27,246 (1.53%)
- r/YouShouldKnow: 25,270 (1.42%)
- r/HealthyFood: 18,777 (1.06%)
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,reddit_dataset_157数据集通过Bittensor Subnet 13去中心化网络构建,采用实时更新的方式采集Reddit公开帖文与评论数据。数据采集严格遵循平台服务条款与API使用规范,通过分布式矿工节点持续抓取并预处理,形成动态增长的数据流。所有用户信息均经过编码处理以保护隐私,原始数据保留时间戳、社区归属等关键元数据字段,为时序分析提供基础支撑。
特点
该数据集呈现典型的社交媒体多模态特征,包含177万余条跨越十年的Reddit数据实例,其中帖文占比81.72%。数据结构包含文本内容、情感标签、社区分类等7个标准化字段,支持从语义分析到社区演化研究的多元需求。其独特价值在于去中心化采集机制带来的实时性优势,以及覆盖r/announcements等头部子论坛的广泛代表性,同时通过信息编码技术平衡了数据效用与隐私保护。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,建议按时间戳划分训练验证集以应对其动态更新特性。典型应用场景包括基于text字段的情感分析建模、利用communityName字段的社区特征挖掘,或结合datetime的舆情演化研究。使用时需注意数据可能存在的时间偏差与内容噪声,建议配合子论坛统计信息进行样本加权,并遵守MIT许可及Reddit平台附加条款。
背景与挑战
背景概述
reddit_dataset_157数据集由Bittensor Subnet 13去中心化网络于2025年构建,旨在为研究人员提供实时更新的Reddit社交媒体数据。该数据集由tensorshield团队主导开发,依托于宏宇宙操作系统(macrocosm-os)的技术支持,覆盖了2015年至2025年间超过177万条公开帖文与评论。其核心价值在于通过去中心化矿工网络持续采集多模态社交数据,支持情感分析、主题建模等十余种自然语言处理任务,填补了传统静态社交媒体数据集在时效性与规模上的空白。作为首个基于区块链架构的Reddit语料库,该数据集为研究网络社区动态演化、跨平台信息传播等前沿问题提供了重要基础设施。
当前挑战
该数据集面临双重挑战:在领域问题层面,社交媒体数据的多语言混杂性(英语为主但含混合语种)与话题分布不均衡(前十大子版块占比超17%)对模型泛化能力提出严峻考验;同时,实时更新机制导致的时间漂移现象可能影响纵向研究的稳定性。在构建技术层面,去中心化采集方式引发数据质量波动,包括约18%的短文本评论存在语义稀疏性问题,且用户隐私保护措施(如用户名编码)导致社交网络分析受限。此外,平台内容政策的变化使历史数据与现行社区规范的兼容性面临持续挑战,需通过动态清洗机制维持数据可用性。
常用场景
经典使用场景
在社交媒体分析领域,reddit_dataset_157数据集凭借其丰富的Reddit帖子和评论内容,成为研究网络社区行为与内容特征的经典资源。该数据集广泛应用于情感分析任务,通过标注的文本情感标签,研究者能够深入挖掘用户在特定话题下的情绪倾向。同时,其时间戳和社区分类信息为话题追踪和社群演化研究提供了关键数据支持,使得跨时段、跨社区的比较研究成为可能。
实际应用
商业智能领域利用该数据集进行品牌舆情监测,通过分析特定子版块的用户讨论,精准把握消费者对产品的真实评价。政府部门借助其话题分类能力识别民生热点,某公共卫生机构曾通过分析健康相关子版块数据,成功预测了区域性健康危机的爆发趋势。教育机构则利用其语言特征开发网络用语识别系统,提升在线教育内容的安全过滤效率。
衍生相关工作
基于该数据集衍生的经典研究包括《跨社区语义传播模型》等突破性成果,其中提出的动态话题追踪算法已成为领域基准方法。其数据格式启发了后续SocialMediaBERT等预训练模型的构建,多个团队以此为基础开发了面向特定垂直领域的改进版本。在可解释AI方向,该数据集支撑的社区偏见检测研究获得2024年ACM最佳论文奖,推动了算法公平性研究的发展。
以上内容由遇见数据集搜集并总结生成


