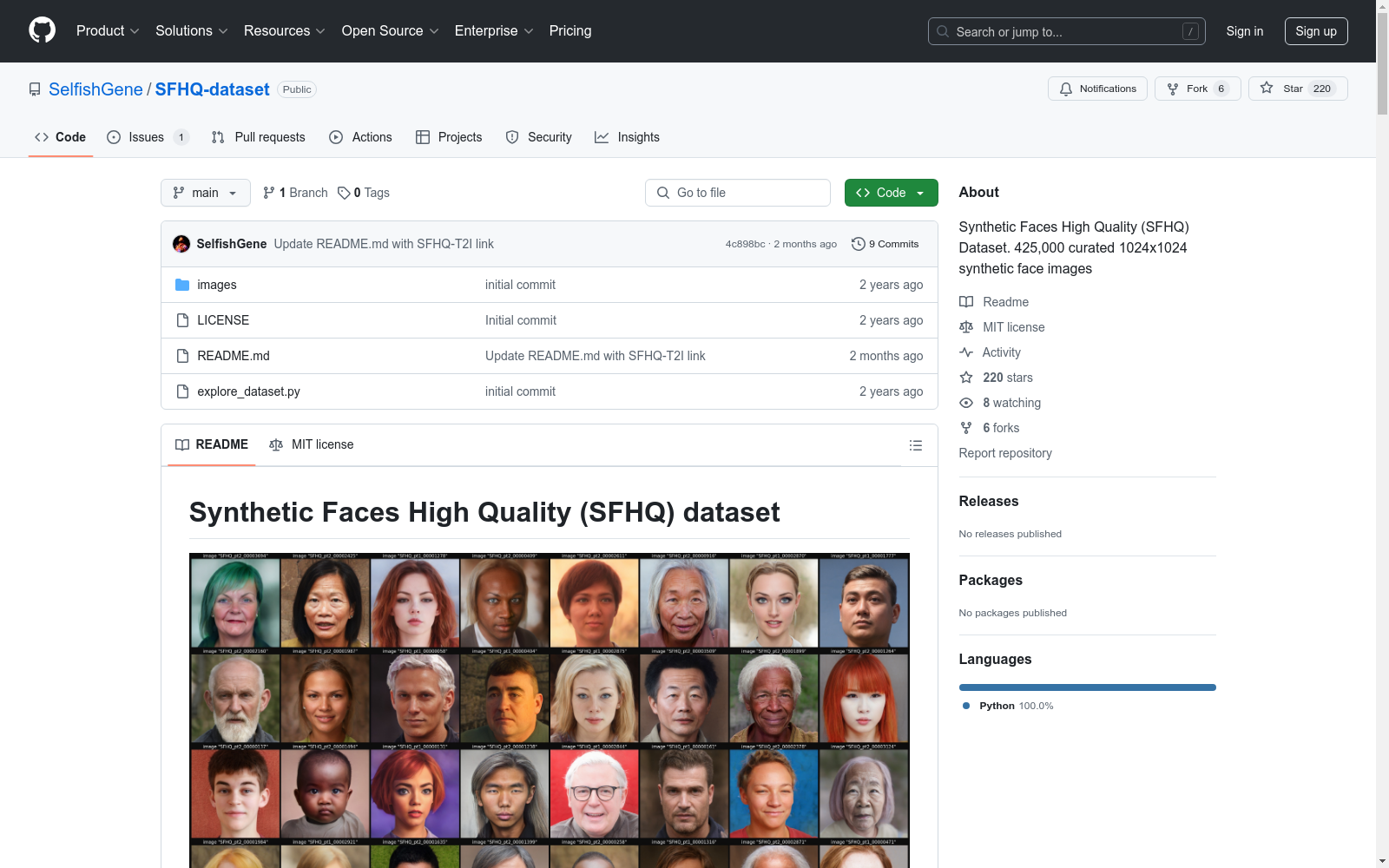
Synthetic Faces High Quality (SFHQ) dataset
收藏github2022-12-20 更新2024-05-31 收录
下载链接:
https://github.com/SelfishGene/SFHQ-dataset
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含约425,000张精心挑选的1024x1024高质量合成人脸图像,这些图像通过将多种灵感来源(如绘画、素描、3D模型、文本到图像生成器等)转化为逼真的人脸图像而创建。数据集还包括面部地标(扩展的110个地标点)和人脸解析的语义分割图。
This dataset comprises approximately 425,000 meticulously selected 1024x1024 high-quality synthetic facial images. These images were created by transforming various sources of inspiration, such as paintings, sketches, 3D models, and text-to-image generators, into realistic facial images. The dataset also includes facial landmarks (extended to 110 landmark points) and semantic segmentation maps for facial parsing.
创建时间:
2022-09-04
原始信息汇总
数据集概述
数据集名称
- Synthetic Faces High Quality (SFHQ) dataset
数据集组成
- 总图像数量:约425,000张
- 图像分辨率:1024x1024
- 数据集分为四部分:
- Part 1:89,785张图像,灵感来源包括Artstation-Artistic-face-HQ Dataset (AAHQ)、Close-Up Humans Dataset和UIBVFED Dataset。
- Part 2:91,361张图像,灵感来源包括Face Synthetics Dataset和Stable Diffusion v1.4模型。
- Part 3:118,358张图像,灵感来源为StyleGAN2 mapping network。
- Part 4:125,754张图像,灵感来源为Stable Diffusion v2.1模型。
数据集生成过程
- 灵感来源:包括绘画、3D模型、文本到图像生成器等多种来源。
- 图像处理:通过StyleGAN2 latent space编码和微调,转化为照片级真实感的图像。
- 图像筛选:采用半自动半手动的方式,使用visual taste approximator工具进行筛选。
附加信息
- 面部特征:包含110个面部地标点和面部解析语义分割图。
- 数据集工具:提供
explore_dataset.py脚本,用于访问地标、分割图和文本搜索。 - 隐私与许可:所有图像均为合成生成,无隐私或版权问题。
数据集用途
- 用于训练机器学习模型,特别是生成对抗网络(如StyleGAN)。
- 提供高度的身份、种族、年龄、姿态、表情、光照条件、发型和发色的多样性。
数据集下载
- 可通过Kaggle下载各部分数据集。
搜集汇总
数据集介绍
构建方式
SFHQ数据集的构建过程融合了多种先进技术与资源。首先,从多个灵感来源(如绘画、3D模型和文本生成图像)中提取原始图像,这些图像随后通过StyleGAN2的潜在空间编码进行处理,生成候选图像。这些候选图像经过半自动化的质量筛选过程,利用视觉品味近似工具进行进一步的精细化处理,确保最终图像的高真实感。此外,通过CLIP特征去除相似度过高的图像,确保数据集的多样性。
特点
SFHQ数据集以其高分辨率(1024x1024)和高质量的合成面部图像著称,涵盖了广泛的年龄、种族、表情和发型等多样性。数据集还包含了面部标志点和语义分割图,提供了丰富的面部特征信息。此外,数据集通过预训练的CLIP特征,支持快速文本查询,增强了数据集的实用性和灵活性。
使用方法
SFHQ数据集可通过Kaggle平台下载,分为四个部分,每个部分包含不同来源的合成面部图像。数据集附带了一个示例脚本,展示了如何访问面部标志点、分割图以及进行文本查询。用户可以利用这些预处理的数据进行面部识别、图像生成模型的训练等多种应用。此外,数据集的多样性和高质量使其成为研究和开发新一代面部生成模型的理想选择。
背景与挑战
背景概述
Synthetic Faces High Quality (SFHQ) 数据集是由 David Beniaguev 创建的,旨在提供高质量的合成人脸图像。该数据集包含约425,000张1024x1024分辨率的图像,分为四个部分。这些图像通过多种来源(如绘画、3D模型、文本到图像生成器等)生成,并经过StyleGAN2潜在空间的编码和微调,以达到照片级真实感。SFHQ数据集不仅包含面部特征点(扩展到110个点)和面部解析语义分割图,还提供了预训练特征,便于文本查询和数据探索。该数据集的创建旨在为机器学习模型提供高质量的训练数据,特别是在生成对抗网络(GAN)和面部识别领域。
当前挑战
SFHQ数据集在构建过程中面临多个挑战。首先,从多种来源生成高质量的合成图像需要复杂的图像处理和编码技术,如StyleGAN2和Stable Diffusion。其次,确保图像的真实感和多样性,同时去除相似度过高的图像,是一个技术难题。此外,数据集的多样性虽然涵盖了身份、种族、年龄等多个维度,但在配饰和遮挡方面存在不足,这可能影响其在某些应用场景中的表现。最后,数据集继承了其原始数据集和生成模型的偏见,需要在实际应用中加以考虑和校正。
常用场景
经典使用场景
在计算机视觉领域,Synthetic Faces High Quality (SFHQ) 数据集被广泛用于训练和评估人脸生成与识别模型。其高分辨率(1024x1024)和多样化的面部特征使其成为研究人脸合成、风格迁移和面部属性编辑的理想选择。通过结合多种生成技术,如StyleGAN2和Stable Diffusion,SFHQ数据集能够提供高度逼真且多样化的合成人脸图像,从而支持深度学习模型在人脸相关任务中的性能提升。
实际应用
在实际应用中,SFHQ数据集被用于增强人脸识别系统的鲁棒性,特别是在低光照、遮挡或极端表情等复杂场景下。此外,该数据集还支持虚拟现实和增强现实应用中的人脸生成与编辑,如虚拟角色的创建和个性化定制。通过提供高质量的合成数据,SFHQ数据集有助于减少对真实数据的依赖,降低数据采集和处理的隐私风险。
衍生相关工作
SFHQ数据集的发布催生了一系列相关研究工作,特别是在人脸生成和编辑领域。例如,基于SFHQ数据集的研究已经推动了StyleGAN2和Stable Diffusion模型的改进,提升了生成图像的质量和多样性。此外,该数据集还被用于开发新的面部属性编辑工具和算法,如基于CLIP的文本到图像搜索和面部语义分割。这些衍生工作进一步扩展了SFHQ数据集的应用范围,推动了计算机视觉技术的进步。
以上内容由遇见数据集搜集并总结生成


