community-datasets/selqa
收藏Hugging Face2024-06-26 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/community-datasets/selqa
下载链接
链接失效反馈官方服务:
资源简介:
SelQA数据集是一个用于选择式问答任务的新基准数据集。它包含两个主要任务:答案选择和答案触发。数据集基于英文,包含多个主题,如音乐、电视、旅行、艺术、体育等。数据集的结构包括多个配置,每个配置都有不同的特征和分割。数据集的创建目的是为了促进选择式问答和答案触发任务的研究,并提供初始基准。
The SelQA dataset is a novel English-based benchmark dataset for selective question answering tasks. It encompasses two core tasks: answer selection and answer triggering. Covering diverse topics including music, television, travel, art, sports, and more, the dataset features multiple configurations, each with distinct characteristics and data splits. Developed to advance research on selective question answering and answer triggering tasks, the SelQA dataset provides an initial benchmark for these tasks.
提供机构:
community-datasets
原始信息汇总
数据集卡片 for SelQA
数据集描述
数据集摘要
SelQA: 一个用于选择型问答的新基准数据集。
支持的任务和排行榜
问答(Question Answering)
语言
英语(English)
数据集结构
数据实例
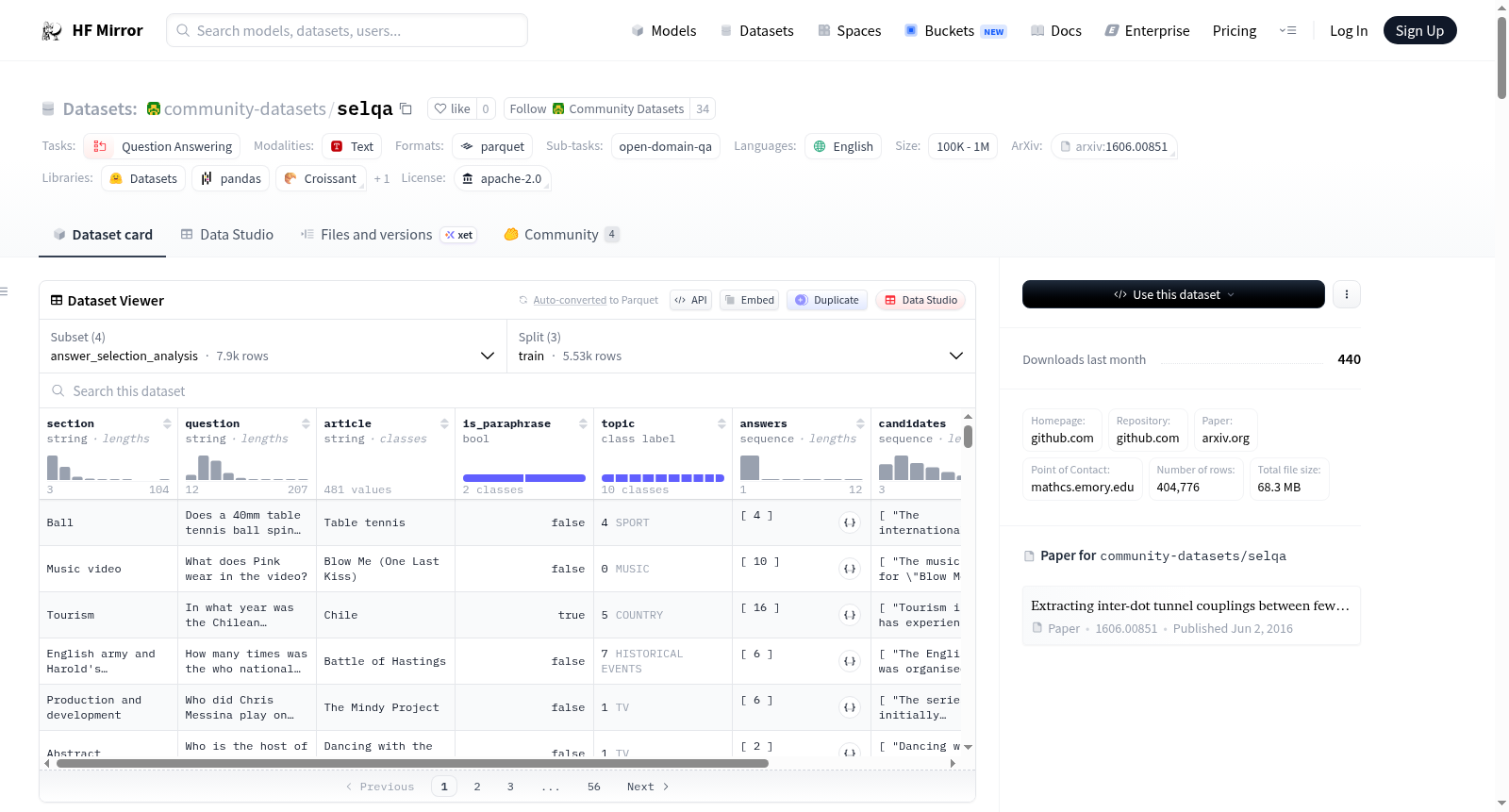
数据集包含多个配置,每个配置有不同的特征和分割。以下是一些示例:
答案选择(Answer Selection)
- 分析数据:包含问题、文章、章节、主题、问题类型、是否为复述、候选句子和答案索引。
- 实验数据:包含问题、候选句子和标签(0表示无答案,1表示有答案)。
答案触发(Answer Triggering)
- 分析数据:包含问题、文章、章节、主题、问题类型、是否为复述和候选列表(包含文章、章节、候选句子和答案索引)。
- 实验数据:包含问题、候选句子和标签(0表示无答案,1表示有答案)。
数据字段
答案选择
-
分析数据:
question: 问题article: 相关维基百科文章section: 相关维基百科文章的章节topic: 问题主题(MUSIC, TV, TRAVEL, ART, SPORT, COUNTRY, MOVIES, HISTORICAL EVENTS, SCIENCE, FOOD)q_types: 问题类型(what, why, when, who, where, how)is_paraphrase: 是否为复述candidates: 相关章节中的句子列表answers: 包含问题答案的候选索引列表
-
实验数据:
0: 问题,所有单词分开1: 问题的候选句子,所有单词分开2: 标签(0表示无答案,1表示有答案)
答案触发
-
分析数据:
question: 问题article: 相关维基百科文章section: 相关维基百科文章的章节topic: 问题主题(MUSIC, TV, TRAVEL, ART, SPORT, COUNTRY, MOVIES, HISTORICAL EVENTS, SCIENCE, FOOD)q_types: 问题类型(what, why, when, who, where, how)is_paraphrase: 是否为复述candidate_list: 包含5个候选章节的列表article: 候选文章的标题section: 候选文章的章节candidates: 该候选章节中的句子列表answers: 包含问题答案的候选索引列表(可能为空)
-
实验数据:
0: 问题,所有单词分开1: 问题的候选句子,所有单词分开2: 标签(0表示无答案,1表示有答案)
数据分割
| Train | Valid | Test | |
|---|---|---|---|
| 答案选择 | 5529 | 785 | 1590 |
| 答案触发 | 27645 | 3925 | 7950 |
数据集创建
策划理由
鼓励研究和提供选择型问答及答案触发任务的初始基准。
源数据
初始数据收集和规范化
[需要更多信息]
源语言生产者
[需要更多信息]
注释
注释过程
众包(Crowdsourced)
注释者
[需要更多信息]
个人和敏感信息
[需要更多信息]
使用数据集的注意事项
数据集的社会影响
该数据集旨在帮助开发更好的选择型问答系统。
偏见讨论
[需要更多信息]
其他已知限制
[需要更多信息]
附加信息
数据集策展人
[需要更多信息]
许可信息
Apache License 2.0
引用信息
@InProceedings{7814688, author={T. {Jurczyk} and M. {Zhai} and J. D. {Choi}}, booktitle={2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI)}, title={SelQA: A New Benchmark for Selection-Based Question Answering}, year={2016}, volume={}, number={}, pages={820-827}, doi={10.1109/ICTAI.2016.0128} }
贡献
感谢 @Bharat123rox 添加此数据集。
搜集汇总
数据集介绍
构建方式
在开放域问答研究领域,SelQA数据集的构建体现了对选择式问答任务的深度探索。该数据集源自维基百科文本,通过众包方式对原始语料进行标注,精心构建了答案选择和答案触发两大任务。其构建过程首先从涵盖音乐、电视、旅行、艺术、体育、国家、电影、历史事件、科学与食物等十个主题的维基百科章节中提取文本,形成候选句子集合;随后针对每个章节设计问题,并由标注者从候选句子中识别出包含答案的句子,从而生成带有二元标签的数据对。数据集进一步区分了分析用与实验用两种配置,分析配置保留了完整的元数据如章节、主题、问题类型及同义改写标记,而实验配置则提供了标准化的问答对序列,便于模型训练与评估。这种结构化的构建方法为选择式问答机制的研究提供了系统性的数据基础。
使用方法
针对SelQA数据集的应用,研究者可依据具体任务目标灵活选用其四种配置。对于答案选择任务,分析配置提供了完整的结构化信息,包括问题、候选句子列表、答案索引及丰富的元数据,适用于深入的错误分析与模型诊断;实验配置则提供了预处理后的问答对序列与二元标签,可直接用于训练分类模型,如判断给定候选句子是否包含问题答案。对于答案触发任务,分析配置包含了跨多个文章章节的候选列表,支持对文档级答案定位的研究;实验配置同样提供了标准化的输入输出对。使用时可利用HuggingFace数据集库加载相应配置,并按照训练、验证与测试划分进行模型开发与评估,其清晰的接口设计便于集成至现代机器学习流程中,服务于选择式问答模型的性能提升与比较研究。
背景与挑战
背景概述
在自然语言处理领域,开放域问答系统的发展长期受限于高质量基准数据集的稀缺。SelQA数据集由埃默里大学的研究团队于2016年创建,旨在为基于选择的问答任务提供新的评估基准。该数据集聚焦于从候选句子中精准定位答案的核心研究问题,涵盖了音乐、电视、旅行、艺术、体育、国家、电影、历史事件、科学与食物等十大主题领域。通过引入答案选择和答案触发两大任务,SelQA推动了问答系统在语义理解和上下文匹配方面的深入研究,为后续的模型优化与算法创新奠定了重要基础。
当前挑战
SelQA数据集致力于解决开放域问答中答案选择的挑战,其核心在于模型需从多个语义相近的候选句子中准确识别包含答案的文本片段,这对语义相似度计算与上下文推理能力提出了较高要求。在构建过程中,研究团队面临数据质量控制的难题,包括如何通过众包方式确保问题与答案对的准确性与多样性,以及如何从维基百科等复杂源文本中提取结构化的候选句子并标注答案位置。此外,数据集中包含的释义问题与多类型疑问词进一步增加了标注的一致性与任务设计的复杂性。
常用场景
经典使用场景
在开放域问答研究领域,SelQA数据集以其独特的基于选择的问答任务设计,为模型评估提供了经典场景。该数据集通过提供问题、候选答案句子及标注,使研究者能够训练和测试模型从多个候选句子中精准识别正确答案的能力。其涵盖音乐、电视、旅行、艺术、体育、国家、电影、历史事件、科学与食物等十大主题,确保了任务的多领域覆盖性,为模型泛化性能的验证奠定了坚实基础。
解决学术问题
SelQA数据集有效应对了传统问答系统中答案生成与答案选择之间的研究空白,专注于解决基于选择的问答这一核心学术问题。它通过构建大规模、高质量的问题-候选答案对,并引入答案触发任务,推动了模型在无需生成文本的情况下直接从给定文本中定位答案的能力研究。该数据集的建立,促进了问答系统从生成范式向选择范式的演进,为评估模型的理解精度与效率提供了可靠基准,对自然语言处理领域的任务定义与评估方法产生了深远影响。
实际应用
在实际应用层面,SelQA数据集支撑的问答技术可广泛应用于智能客服、教育辅助与信息检索系统。例如,在知识库或文档集合中,系统能够快速定位与用户问题最相关的句子或段落,从而提供精确答案,而非生成可能包含不实信息的文本。这种基于选择的机制增强了回答的可靠性与可解释性,适用于对准确性要求高的场景,如法律咨询、医疗信息查询或学术资料查找,提升了人机交互的效率和信任度。
数据集最近研究
最新研究方向
在开放域问答领域,SelQA数据集凭借其独特的基于选择的问答架构,为模型评估提供了精细化的基准。当前研究聚焦于利用该数据集的多主题结构和答案触发任务,探索跨领域知识迁移与上下文理解的前沿问题。随着大语言模型在复杂推理任务中的广泛应用,SelQA的候选句子选择机制成为评估模型语义匹配与噪声过滤能力的关键工具。相关研究进一步结合对比学习与多任务框架,旨在提升模型对细粒度语义差异的敏感性,推动问答系统向更精准、鲁棒的方向演进。
以上内容由遇见数据集搜集并总结生成


