botp/RyokoAI_Syosetu711K
收藏Hugging Face2023-08-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/botp/RyokoAI_Syosetu711K
下载链接
链接失效反馈官方服务:
资源简介:
Syosetu711K是一个包含约711,700部小说的数据集,这些小说是从日本小说自出版网站“小説家になろう”在2023年3月26日至27日期间抓取的。数据集涵盖了网站上发布的大多数小说,无论其长度或质量如何,并包含元数据以便用户过滤和评估内容。
Syosetu711K is a dataset containing approximately 711,700 novels crawled from Japan's self-publishing novel website "Shōsetsuka ni Narō" during March 26–27, 2023. The dataset covers most novels published on the site, regardless of their length or quality, and includes metadata to facilitate users' filtering and content evaluation.
提供机构:
botp
原始信息汇总
数据集卡片:Syosetu711K
数据集描述
- 数据集名称: Syosetu711K
- 数据集概述: Syosetu711K是一个包含约711,700本从日本小说自出版网站“小説家になろう”(Lets Become a Novelist)在2023年3月26日至27日期间抓取的小说数据集。该数据集包含了网站上几乎所有的小说,无论其长度或质量如何,并包含元数据以便用户过滤和评估其内容。
支持的任务和排行榜
- 主要用途: 主要用于文本生成模型的无监督训练,但也可能适用于其他目的。
- 支持的任务:
- 文本分类
- 文本生成
语言
- 日语
数据集结构
数据实例
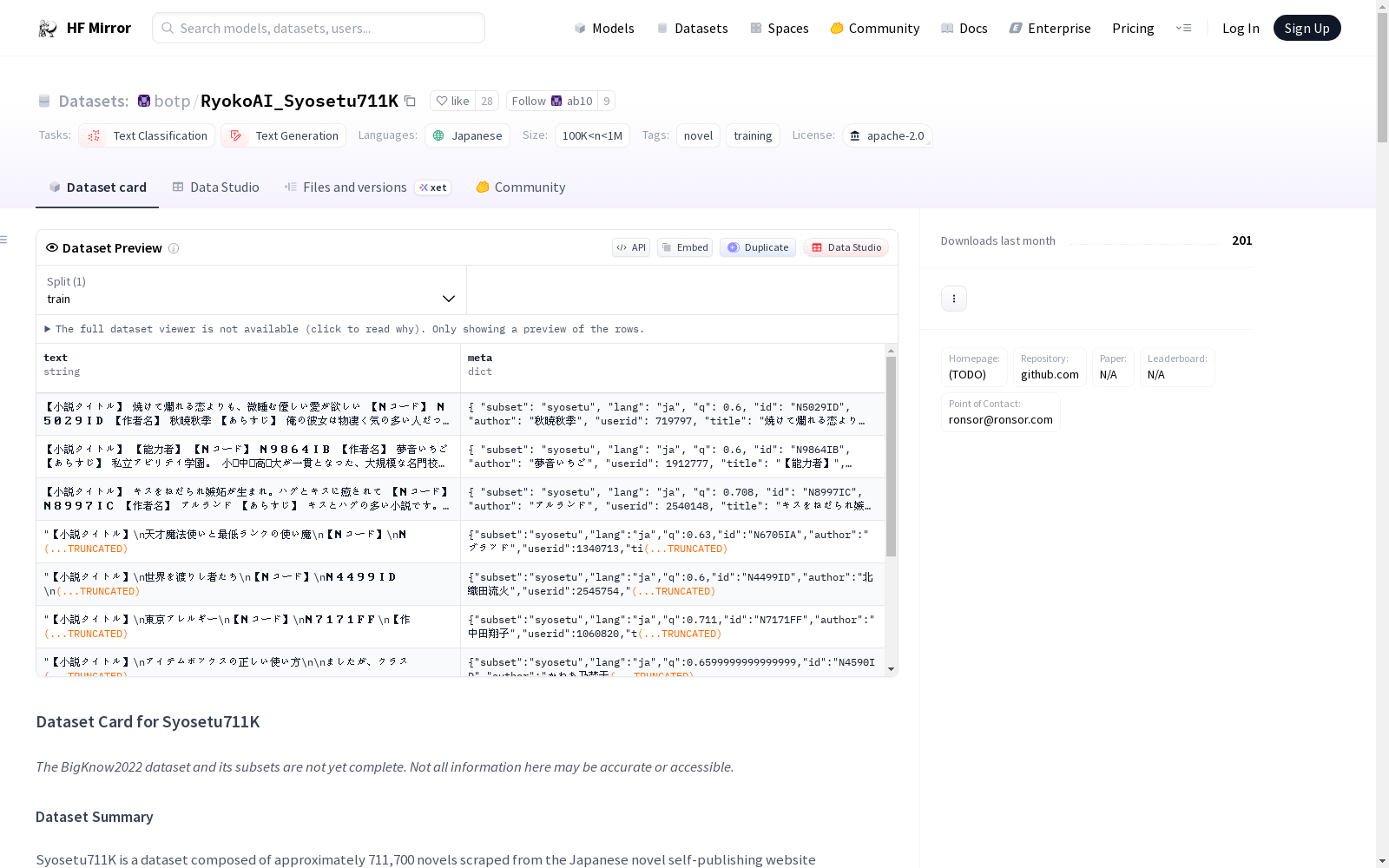
json { "text": "【小説タイトル】 焼けて爛れる恋よりも、微睡む優しい愛が欲しい 【Nコード】 N5029ID 【作者名】 秋暁秋季 【あらすじ】 俺の彼女は物凄く気の多い人だった。 お眼鏡に適う奴が居れば、瞳孔を蕩けさせる人だった。 その癖照れ屋で、すぐに目を逸らす。 な...", "meta": { "subset": "syosetu", "q": 0.6, "id": "N5029ID", "author": "秋暁秋季", "userid": 719797, "title": "焼けて爛れる恋よりも、微睡む優しい愛が欲しい", "length": 871, "points": 0, "lang": "ja", "chapters": 1, "keywords": ["気が多い", "浮気性", "無愛想", "照れる", "嫉妬", "好みではない", "クソデカ感情", "空気のような安心感"], "isr15": 0, "genre": 102, "biggenre": 1 } }
数据字段
text: 实际的小说文本,包含所有章节meta: 小说的元数据subset: 数据集标签:syosetulang: 数据集语言:ja(日语)id: 小说ID/ncodeauthor: 作者名userid: 作者用户IDtitle: 小说标题length: 小说长度(字数)points: 全球点数(对应于Syosetu API中的global_point)q: q-score(基于points计算的质量分数)chapters: 章节数量(对应于Syosetu API中的general_all_no)keywords: 小说关键词数组(对应于Syosetu API中的keyword,按空格分割)isr15: 小说是否为R15+评级genre: 小说类型ID(可选,参见Syosetu API文档)biggenre: 小说大类型ID(可选,参见Syosetu API文档)isr18: 小说是否为R18+评级nocgenre: 小说类型ID(可选,仅在isr18为真时可用,参见Syosetu API文档)
Q-Score分布
0.00: 0 0.10: 0 0.20: 0 0.30: 0 0.40: 0 0.50: 213005 0.60: 331393 0.70: 101971 0.80: 63877 0.90: 1542 1.00: 2
数据分割
数据未进行分割。
数据集创建
数据来源
- 初始数据收集和规范化: 首先,使用Syosetuka ni Narou API收集所有小说的元数据到一个JSONL文件中。然后,创建一个仅包含小说“ncodes”或ID的次级文本文件,并分发到下载节点。接着,使用姐妹网站https://pdfnovels.net查询每个小说ID,并保存结果PDF以供后续处理。最后,使用
pdftotext工具将PDF文件转换为文本文件,并进行清理,然后将文本文件和其他元数据转换为指定的数据字段模式,并将生成的JSON条目连接到Syosetu711K数据集中。
个人和敏感信息
数据集仅包含虚构作品,不包含任何个人身份信息(PII)。
使用数据的注意事项
数据集的社会影响
该数据集旨在帮助训练模型生成更有趣的日语内容,也可能适用于其他语言的模型。
偏见讨论
该数据集由不同作者的虚构作品组成,因此其内容将反映这些作者的偏见。此外,数据集包含NSFW材料且未经筛选,需注意刻板印象。
其他已知限制
无
搜集汇总
数据集介绍
构建方式
在数字文学蓬勃发展的背景下,Syosetu711K数据集的构建体现了对大规模网络文本资源的系统性采集与整理。该数据集通过自动化流程,首先利用“小説家になろう”网站的官方API,获取了平台上全部小说的元数据列表。随后,基于这些小说ID,从关联站点批量下载对应的PDF格式文档。通过pdftotext工具将PDF转换为原始文本后,经过一系列清洗与规范化脚本处理,最终将文本内容与丰富的元数据整合为结构化的JSON条目,并分割为多个文件进行存储,形成了包含约71.17万部作品的语料库。
特点
作为日本最大的网络小说平台语料集合,该数据集的核心特点在于其规模宏大与内容多样性。它几乎囊括了特定时间截点上该网站的全部公开作品,覆盖了从青春恋爱到奇幻传奇等多种题材,且未对作品长度或文学质量进行预先筛选。数据集为每条记录提供了详尽的元信息,包括作者、标题、字数、章节数、关键词、体裁分类以及基于网站积分计算的Q质量评分,这为研究者进行数据过滤、质量评估及多维度分析提供了坚实基础。同时,数据集明确标注了可能存在的成人内容,提示了其中蕴含的作者群体偏见与未过滤的敏感性材料。
使用方法
该数据集主要服务于自然语言处理领域的研究与应用,尤其适用于日文文本的生成模型训练。使用者可通过HuggingFace等平台加载数据集,利用其提供的元数据字段,如`q`(质量分数)、`genre`(体裁)、`keywords`(关键词)等,灵活构建训练子集或进行可控文本生成实验。鉴于数据未经分割,研究人员需自行划分训练、验证与测试集。在模型训练前,建议结合`isr15`或`isr18`字段对内容进行审查,并根据研究目标对数据进行必要的清洗与预处理,以应对数据中可能存在的噪声与偏见。
背景与挑战
背景概述
在自然语言处理领域,大规模高质量文本语料库的构建对于推动语言模型的发展至关重要。Syosetu711K数据集由Ronsor实验室于2023年3月创建,其核心目标在于汇集日本知名小说投稿平台“小説家になろう”上的海量原创作品,为日语文本生成与分类任务提供丰富的训练资源。该数据集涵盖了超过71万部小说,不仅反映了当代日本网络文学的多样性与创造力,也为研究日语语言模型的学者提供了宝贵的实证材料,对促进日语自然语言处理技术的进步具有显著影响力。
当前挑战
Syosetu711K数据集致力于解决日语文本生成模型训练中高质量、大规模语料稀缺的核心问题,其挑战在于如何从异构且质量参差的网络文本中提取有效信息,并确保生成内容的连贯性与创造性。在构建过程中,面临多重技术难题:首先,需通过自动化爬虫与API接口高效采集海量小说数据,同时处理PDF转换中的格式错乱与字符编码问题;其次,数据清洗环节需剔除低质量文本并保留关键元数据,如作者、章节结构与关键词标签,以支持后续的过滤与分析;此外,数据集包含未经过滤的成人内容与作者主观偏见,这要求使用者具备审慎的数据处理与偏差识别能力。
常用场景
经典使用场景
在日语自然语言处理领域,大规模高质量文本语料的稀缺性长期制约着相关模型的发展。Syosetu711K数据集以其超过71万部日本网络小说的庞大规模,为日语文本生成模型的训练提供了珍贵的资源。该数据集最经典的应用场景在于无监督语言模型的预训练,研究者能够利用其丰富的叙事结构和多样化的文学表达,训练出具备更强日语理解和创作能力的生成模型。这些模型在续写故事、风格模仿等任务中展现出卓越性能,为日语生成式人工智能奠定了数据基础。
实际应用
超越学术研究范畴,Syosetu711K数据集在产业界催生了多样化的实际应用。基于该数据集训练的模型已被集成到智能写作助手、互动叙事游戏以及个性化内容推荐系统中。在数字出版领域,这类技术能够辅助创作者进行情节构思或风格润色;在教育领域,可作为日语学习工具,生成符合学习者水平的阅读材料。此外,其蕴含的丰富文化元素也为开发具有日本文化特色的对话机器人或虚拟角色提供了内容支撑,展现了从数据资源到实际生产力的转化路径。
衍生相关工作
围绕Syosetu711K数据集,学术界和工业界已衍生出一系列经典研究工作。在模型架构方面,催生了针对日语长文本生成优化的Transformer变体,这些模型在篇章连贯性和风格一致性上取得了显著提升。在评估方法上,研究者开发了专门针对日语文学文本生成质量的自动化评估指标。同时,基于该数据集进行的过滤与质量控制研究,为从海量用户生成内容中构建高质量训练集提供了方法论指导。这些工作共同构成了日语生成式人工智能研究的重要分支,持续推动着该领域的技术边界向前拓展。
以上内容由遇见数据集搜集并总结生成


