anonymous-neurips-2026/memebench
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/anonymous-neurips-2026/memebench
下载链接
链接失效反馈官方服务:
资源简介:
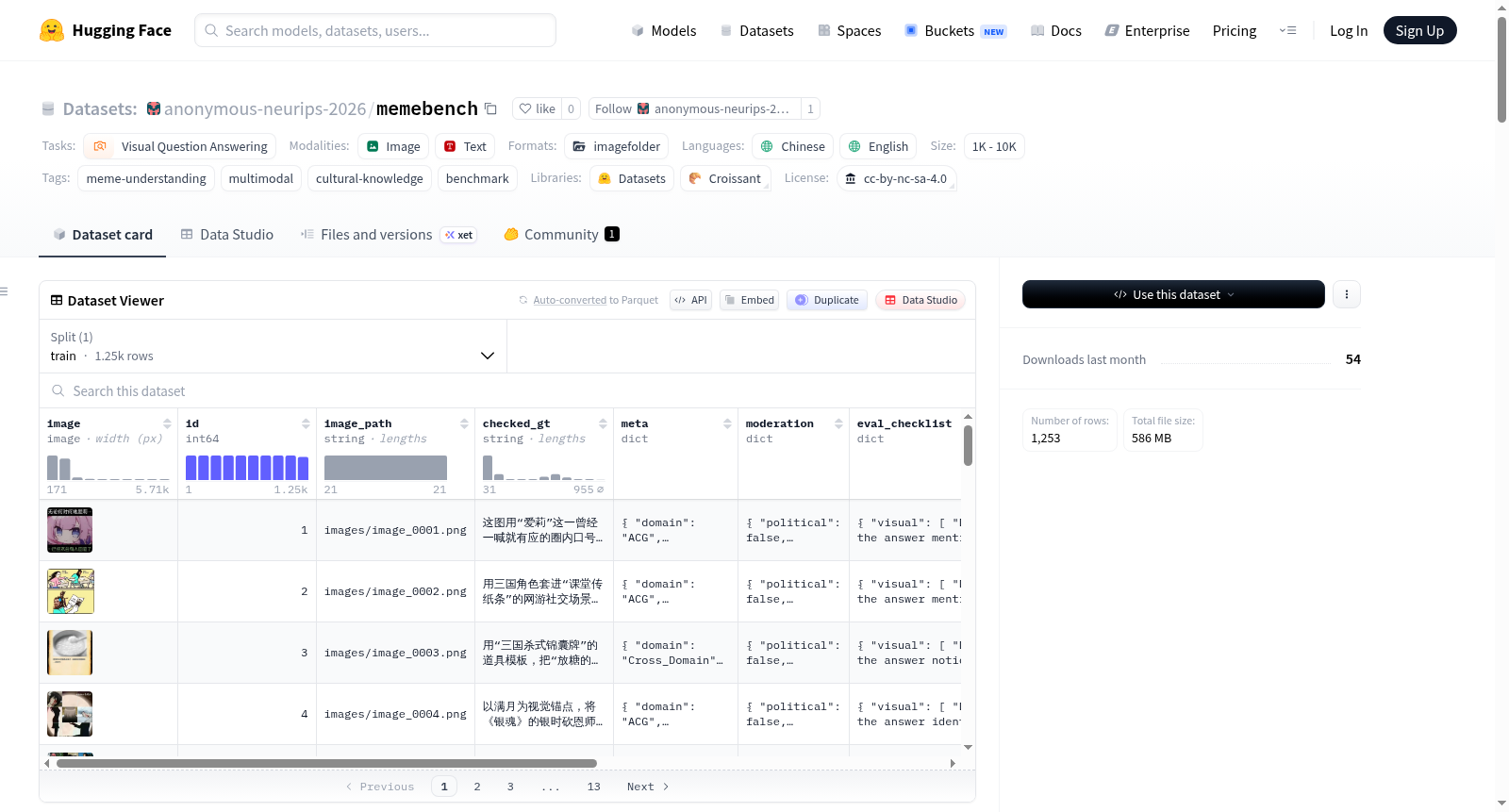
MemeBench是一个双语诊断性基准,用于开放式模因解释,评估大型视觉语言模型的文化语义理解能力。它包含1,253个专家标注的模因,覆盖7个文化领域(中文和英文)。每个模因都标注了结构化的VIKR模式,涵盖四个诊断层:视觉线索(描述所见内容)、身份链接(识别描绘的对象)、知识单元(了解文化背景)和推理机制(解释模因的幽默之处)。数据集还包括详细的元数据、统计信息、评估协议和创建过程。
MemeBench is a bilingual diagnostic benchmark for open-ended meme interpretation, evaluating large vision-language models cultural-semantic understanding. It contains 1,253 expert-annotated memes spanning 7 cultural domains in Chinese and English. Each meme is annotated with a structured VIKR schema covering four diagnostic layers: Visual clues (describing what is seen), Identity links (identifying depicted entities), Knowledge units (understanding cultural background), and Reasoning mechanisms (explaining why the meme is funny). The dataset also includes detailed metadata, statistics, evaluation protocols, and creation processes.
提供机构:
anonymous-neurips-2026
搜集汇总
数据集介绍
构建方式
MemeBench数据集精心构建于一个多阶段流水线之上,首先从中文与英文互联网社区(涵盖论坛、社交媒体及图像平台)广泛采集迷因图像,覆盖ACG、影视、历史等七大文化领域。随后,借助大语言模型生成初步的VIKR结构化标注,再由领域专家逐一核查与修正,确保注释的精确性。程序化质量审计进一步强制执行实体双链连接、层级分离等架构不变量。最后,通过自动化过滤与人工覆写机制完成内容安全审核,从而产出包含1,253个专家标注样本的高质量双语诊断基准。
特点
该数据集的核心特色在于其开创性的VIKR诊断架构,将迷因理解分解为视觉线索、身份链接、知识单元与推理机制四个可溯源的层次,每个层次配备1至4个二元核查问题,实现细粒度的能力剖析。数据集涵盖中文与英文双语境,聚焦ACG与跨领域内容,并精心统计了身份碰撞、反讽等六种幽默逻辑类型分布。作为仅用于评估的基准,它强调零知识视觉描述与知识-推理分离,确保诊断结果能够精准反映模型在文化语义理解上的真实短板。
使用方法
MemeBench的使用遵循严格的LLM作为评判者的评估协议,研究者需将迷因图像与开放式问题输入待评估的大视觉语言模型,获取其解释性回答。随后,依据VIKR架构中每个维度的核查清单,利用语言模型对模型输出进行二元评分,只有当视觉、身份、知识与推理四个维度全部达标(即每项核查均通过)时,该迷因才被判定为完全理解。主要评估指标为完全通过率,通过逐层消融分析,可系统诊断模型在跨文化迷因理解中的具体能力缺陷。
背景与挑战
背景概述
在大型视觉语言模型(LVLMs)迅猛发展的背景下,如何评估其对蕴含文化语义的复杂多模态内容的理解能力,成为亟待解决的学术前沿问题。MemeBench数据集应运而生,由匿名研究团队于2026年在NeurIPS的评测与数据集轨道发布,聚焦于通过网络迷因(meme)这一载体,诊断模型在文化知识、身份识别与幽默推理等方面的深层理解。该数据集包含1,253张经领域专家精标注的中英双语迷因图片,横跨动漫游戏、影视、历史、政治等七大文化领域,并创新性地提出了VIKR四层诊断框架,分别考察模型的视觉描述、身份链接、知识背景与推理机制,为多模态理解研究提供了结构化、可溯源的评测基准,在文化计算与人工智能交叉领域产生了重要影响力。
当前挑战
MemeBench所致力于解决的领域核心挑战在于,现有视觉语言模型在面对高度依赖文化背景的迷因时,往往仅停留在浅层视觉识别,难以捕捉跨域文化暗喻、双关及幽默逻辑。具体挑战包括:1)文化知识的断层——模型需调用ACG、历史事件等特定文化事实才能破解迷因的幽默机制;2)多模态语义融合——要求模型同时处理图像中的实体、文本OCR及隐含的文化代码,并建立跨模态的逻辑映射;3)语言与文化偏差——数据集虽覆盖中英双语,但中文样本占比61.3%、ACG领域占比过半,导致评测结果易受训练语料偏见影响。在构建过程中,团队面临的挑战尤为严苛:4)标注质量的平衡——需在LLM辅助生成与人工专家校验间反复迭代,确保VIKR各层语义分离且实体双重链接无误;5)安全与伦理边界——针对政治与仇恨言论等敏感内容,必须设计自动过滤与人工裁定的双重机制,以保障数据集的负责任使用。
常用场景
经典使用场景
在视觉与语言理解领域,MemeBench作为一项双语诊断基准,被广泛用于评估大型视觉语言模型对文化语义的深层把握能力。该数据集精选了1,253个经专家标注的梗图,跨越中文与英文两大语系,涵盖动画、影视、历史等七个文化领域。其核心使用方式为通过VIKR四层诊断框架——视觉线索、身份链接、知识单元与推理机制——对模型进行结构化评估。研究者常以此基准对模型进行逐层剖析,判断其是否能够完整理解梗图的幽默本质与文化内涵。
解决学术问题
该数据集瞄准了当前视觉语言模型在跨文化理解上的关键短板,即模型往往仅能识别表层视觉元素,却难以捕捉隐含的文化符号与幽默机制。通过提供带有精细标注的VIKR框架,MemeBench使得学术界能够精准定位模型在哪个环节出现理解断裂——是视觉描述不足、身份识别失误、文化知识缺失,还是推理链条断裂。这一诊断能力推动了多模态理解研究从整体性能评估迈向细粒度能力剖析,为后续改进模型的文化敏感性提供了理论依据与实验抓手。
衍生相关工作
MemeBench的出现激发了多项后续研究。一方面,研究者基于其VIKR标注体系展开了针对性的模型微调实验,开发出专门增强文化知识模块的视觉语言模型,如引入外部知识库进行推理增强。另一方面,该数据集的诊断框架被迁移至其他多模态理解任务,催生了诸如文化常识问答、跨域幽默理解等一系列衍生基准。同时,围绕LLM-as-Judge的评估协议,学术界涌现出大量关于自动化梗图解释与幽默生成的工作,进一步丰富了这一研究方向的理论与实践体系。
以上内容由遇见数据集搜集并总结生成


