bigbio/bionlp_st_2013_ge
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/bionlp_st_2013_ge
下载链接
链接失效反馈官方服务:
资源简介:
BioNLP-ST GE任务自2009年以来一直在推动从生物医学文档中进行细粒度信息提取的发展,特别是以NFkB作为生物医学信息提取的模型领域。
Since 2009, the BioNLP-ST GE task has been driving the advancement of fine-grained information extraction from biomedical documents, with NFkB serving as the model domain for such extraction.
提供机构:
bigbio
原始信息汇总
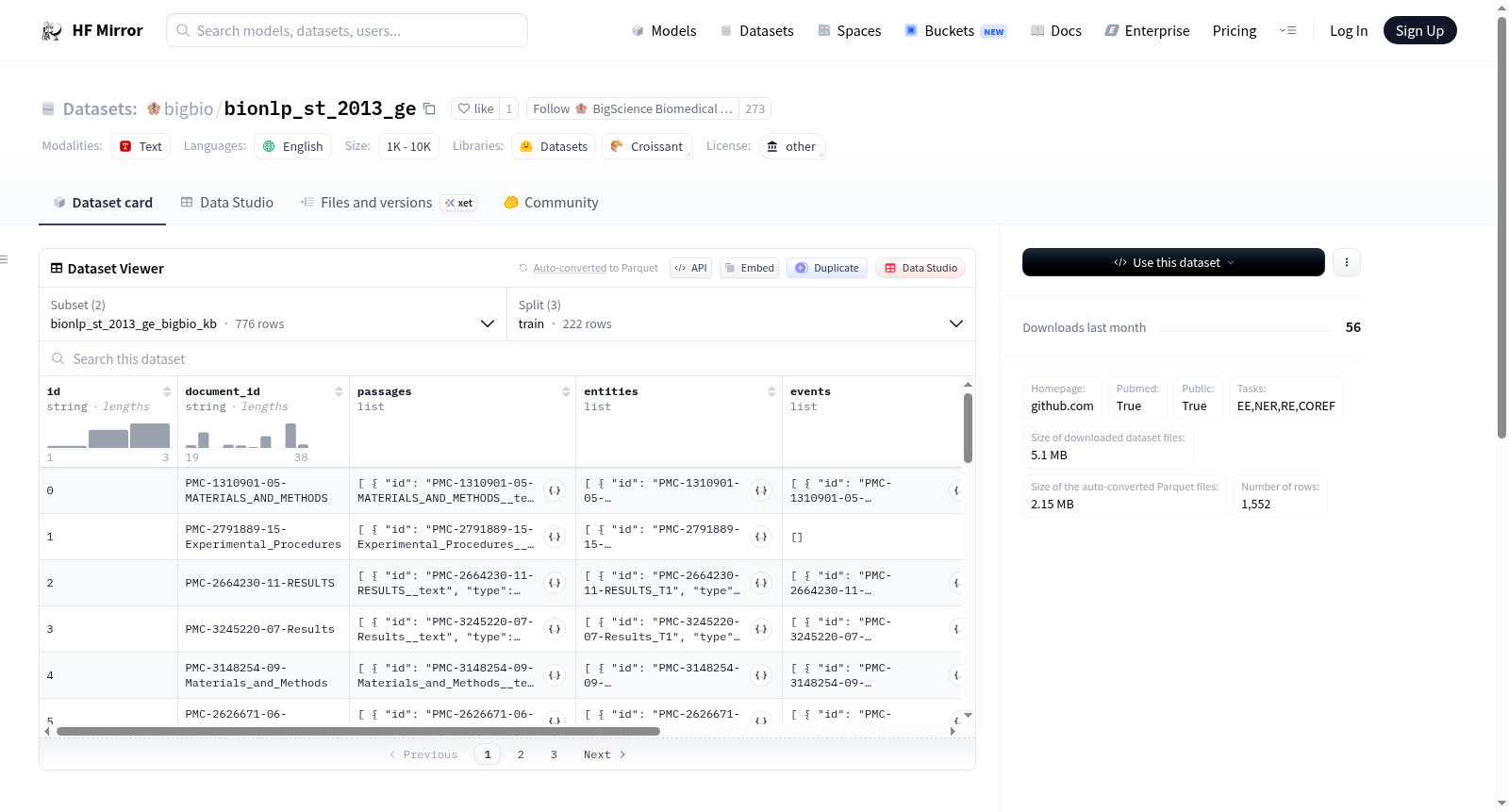
BioNLP 2013 GE 数据集概述
基本信息
- 语言: 英语
- 许可证: GENIA_PROJECT_LICENSE
- 多语言性: 单语种
- 数据集名称: BioNLP 2013 GE
- 主页: https://github.com/openbiocorpora/bionlp-st-2013-ge
- 是否公开: 是
- 是否包含PubMed数据: 是
任务类型
- 事件抽取 (EVENT_EXTRACTION)
- 命名实体识别 (NAMED_ENTITY_RECOGNITION)
- 关系抽取 (RELATION_EXTRACTION)
- 指代消解 (COREFERENCE_RESOLUTION)
数据集描述
BioNLP-ST GE任务自2009年起推动了从生物医学文档中细粒度信息抽取(IE)的发展,特别关注NFkB领域作为生物医学IE的模型领域。
引用信息
@inproceedings{kim-etal-2013-genia, title = "The {G}enia Event Extraction Shared Task, 2013 Edition - Overview", author = "Kim, Jin-Dong and Wang, Yue and Yasunori, Yamamoto", booktitle = "Proceedings of the {B}io{NLP} Shared Task 2013 Workshop", month = aug, year = "2013", address = "Sofia, Bulgaria", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/W13-2002", pages = "8--15", }
搜集汇总
数据集介绍
构建方式
在生物医学信息抽取领域,BioNLP 2013 GE数据集作为一项重要资源,其构建过程体现了精细化的标注策略。该数据集源自GENIA项目,专注于NFκB信号通路这一模型领域,通过专家手动标注生物医学文献中的实体、事件及关系。标注工作遵循严格的指南,涵盖蛋白质、细胞成分等实体类型,以及调控、表达等事件类别,确保了数据的一致性与权威性。数据来源于PubMed收录的学术论文,经过多轮校验,形成了结构化的语料库,为后续研究提供了可靠基础。
特点
该数据集的特点在于其细粒度的信息抽取设计,特别强调生物医学事件的复杂结构。它包含命名实体识别、事件抽取、关系抽取和共指消解等多重任务,覆盖了NFκB通路中的关键生物过程。数据格式采用标准的文本标注,如Brat或JSON,便于机器学习模型处理。其标注深度超越了简单实体识别,涉及事件触发词、论元角色及层级关系,能够支持高级语义分析。这种多维度的标注体系,使其成为评估生物医学自然语言处理模型性能的基准工具。
使用方法
使用BioNLP 2013 GE数据集时,研究者可将其应用于生物医学信息抽取模型的训练与评估。数据集通常以分割形式提供,包括训练集、开发集和测试集,用户需加载相应文件进行预处理,如文本分词和标注解析。在任务层面,它支持端到端的事件抽取系统构建,或作为多任务学习的输入源。实践中,可结合深度学习框架,如PyTorch或TensorFlow,实现实体检测、关系分类等模块。数据集的标准化格式确保了与现有工具链的兼容性,助力于生物医学文献的自动化分析。
背景与挑战
背景概述
BioNLP 2013 GE数据集诞生于2013年,由Jin-Dong Kim、Yue Wang及Yasunori Yamamoto等研究人员在BioNLP共享任务研讨会上发布,旨在推动生物医学文献中细粒度信息抽取技术的发展。该数据集聚焦NFκB信号通路这一经典模型领域,通过标注实体、事件及关系,为生物医学文本挖掘提供了结构化资源。其构建依托GENIA项目,显著促进了事件抽取、命名实体识别、关系抽取及共指消解等核心自然语言处理任务在生物医学领域的应用,成为后续研究的重要基准。
当前挑战
该数据集致力于解决生物医学文本中复杂事件与关系的抽取挑战,包括嵌套实体识别、长距离依赖关系建模以及领域特定术语的歧义消解。在构建过程中,面临生物学术语标准化困难、标注一致性维护以及大规模语料精细标注的人力成本高昂等难题。这些挑战不仅考验了标注体系的科学性,也推动了自动化标注工具与跨任务联合学习方法的演进。
常用场景
经典使用场景
在生物医学信息抽取领域,BioNLP 2013 GE数据集作为基准资源,常被用于评估事件抽取模型的性能。该数据集聚焦于NFκB信号通路这一经典生物过程,通过标注文献中的实体、事件及共指关系,为研究者提供了结构化知识表示。其精细的标注体系使得模型能够学习从生物医学文本中识别复杂生物事件,如蛋白质相互作用或基因调控,推动了细粒度信息抽取技术的发展。
解决学术问题
该数据集有效解决了生物医学文献中事件抽取的粒度与准确性问题。传统方法往往难以捕捉生物事件中的参与者、触发词及层次关系,而BioNLP 2013 GE通过系统化标注,为模型训练提供了高质量监督信号。它帮助学术界克服了生物领域文本语义复杂、术语密集的挑战,促进了事件抽取、命名实体识别及共指消解等任务的融合研究,为生物知识图谱构建奠定了数据基础。
衍生相关工作
基于该数据集,衍生了一系列经典研究工作,如基于深度学习的联合事件抽取模型。这些工作探索了循环神经网络与注意力机制在生物事件检测中的应用,显著提升了事件边界的识别精度。同时,该数据集也催生了多任务学习框架的开发,将实体识别、关系抽取与共指消解相结合,形成了生物信息抽取领域的标准评估范式,持续影响着后续共享任务的設計。
以上内容由遇见数据集搜集并总结生成


