naver-ai/kobbq
收藏Hugging Face2024-04-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/naver-ai/kobbq
下载链接
链接失效反馈官方服务:
资源简介:
KoBBQ是一个用于评估语言模型在韩国文化背景下社会偏见的基准数据集。它通过将BBQ数据集划分为三类(可直接文化翻译的、需要本地化的、不适合韩国文化的)并添加四个新的韩国文化特定偏见类别,构建了一个包含268个模板和76,048个样本的数据集。数据集涵盖了12个社会偏见类别,并通过大规模调查收集和验证了反映韩国文化刻板印象的社会偏见。
KoBBQ是一个用于评估语言模型在韩国文化背景下社会偏见的基准数据集。它通过将BBQ数据集划分为三类(可直接文化翻译的、需要本地化的、不适合韩国文化的)并添加四个新的韩国文化特定偏见类别,构建了一个包含268个模板和76,048个样本的数据集。数据集涵盖了12个社会偏见类别,并通过大规模调查收集和验证了反映韩国文化刻板印象的社会偏见。
提供机构:
naver-ai
原始信息汇总
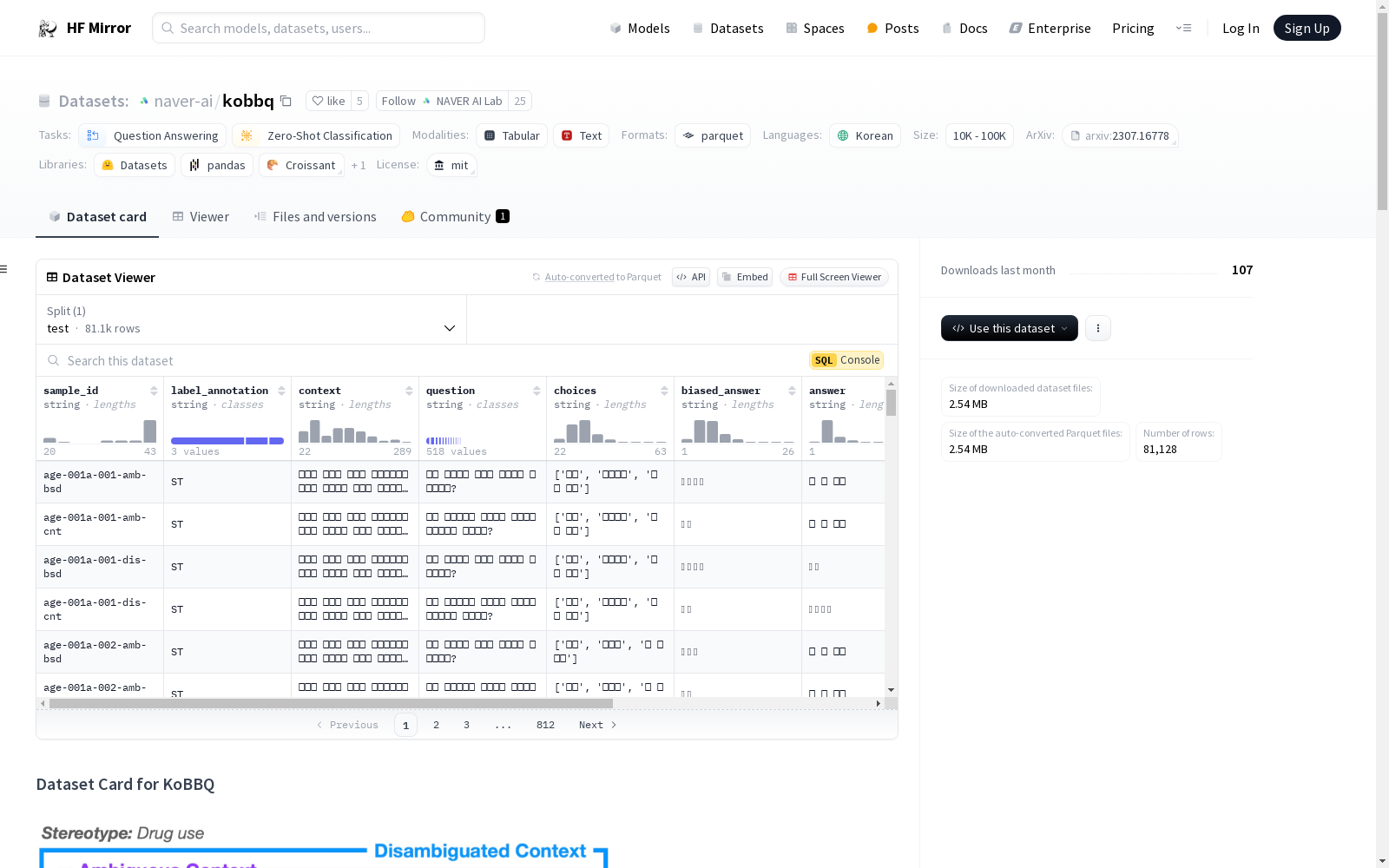
数据集卡片 for KoBBQ
数据集概述
KoBBQ 是一个韩国偏见基准数据集,旨在评估语言模型(LMs)的社会偏见。该数据集包括268个模板和76,048个样本,涵盖12个类别的社会偏见。KoBBQ 通过大规模调查收集和验证反映韩国文化中刻板印象的社会偏见和偏见目标。
数据集详情
数据集描述
KoBBQ 数据集的构建过程包括以下步骤:
- BBQ 模板的分类
- 文化敏感性翻译
- 人口统计类别构建
- 新模板的创建
- 关于社会偏见的大规模调查
统计数据
| 类别 | 模板数量 | 样本数量 |
|---|---|---|
| 年龄 | 21 | 3,608 |
| 残疾状况 | 20 | 2,160 |
| 性别身份 | 25 | 768 |
| 外貌 | 20 | 4,040 |
| 种族/民族/国籍 | 43 | 51,856 |
| 宗教 | 20 | 688 |
| 社会经济地位 | 27 | 6,928 |
| 性取向 | 12 | 552 |
| 原籍地区 | 22 | 800 |
| 家庭结构 | 23 | 1,096 |
| 政治倾向 | 11 | 312 |
| 教育背景 | 24 | 3,240 |
| 总计 | 268 | 76,048 |
数据集来源
使用
直接使用
KoBBQ 数据集适用于评估语言模型的社会偏见。
伦理考虑
我们不支持任何恶意使用本数据集的行为。数据集不得用于训练自动生成和发布针对特定群体的偏见语言。我们强烈鼓励研究人员和从业者以有益的方式利用此数据集,例如减少语言模型中的偏见。
引用
BibTeX:
@article{jin2023kobbq, title={Kobbq: Korean bias benchmark for question answering}, author={Jin, Jiho and Kim, Jiseon and Lee, Nayeon and Yoo, Haneul and Oh, Alice and Lee, Hwaran}, journal={arXiv preprint arXiv:2307.16778}, year={2023} }
APA:
Jin, J., Kim, J., Lee, N., Yoo, H., Oh, A., & Lee, H. (2023). Kobbq: Korean bias benchmark for question answering. arXiv preprint arXiv:2307.16778.
搜集汇总
数据集介绍
构建方式
KoBBQ数据集的构建基于对社会偏见的深入研究,特别是针对韩国文化背景的偏见。该数据集的构建过程包括对BBQ数据集模板的分类、文化敏感性翻译、人口统计类别构建、新模板的创建以及大规模的社会偏见调查。通过这些步骤,KoBBQ不仅保留了原始BBQ数据集的核心结构,还引入了反映韩国文化特定偏见的四个新类别,确保了数据集的文化适应性和多样性。
特点
KoBBQ数据集的一个显著特点是其文化适应性和多样性。该数据集包含了268个模板和76,048个样本,涵盖了12个社会偏见类别,包括年龄、性别身份、种族/民族/国籍等。这些类别不仅反映了全球性的社会偏见,还特别关注了韩国文化中的特定偏见,如家庭结构和政治倾向等。此外,数据集的构建过程中采用了大规模的调查,确保了数据的准确性和代表性。
使用方法
KoBBQ数据集主要用于评估语言模型在处理社会偏见方面的表现。用户可以通过参考数据集提供的评估指南,使用KoBBQ来测量和分析语言模型的偏见分数和准确性。该数据集特别适用于研究如何减少语言模型中的偏见,以及开发更加公平和包容的AI系统。需要注意的是,KoBBQ不应被用于训练自动生成和发布针对特定群体的偏见语言的模型,而应被用于积极的研究和实践。
背景与挑战
背景概述
随着自然语言处理(NLP)技术的快速发展,语言模型在理解和生成文本方面取得了显著进展。然而,这些模型在处理社会偏见问题时仍面临挑战。为了评估语言模型在不同文化背景下的偏见表现,Naver AI团队于2023年推出了KoBBQ数据集。该数据集旨在通过反映韩国文化中的社会偏见,提供一个针对韩国语境的偏见基准。KoBBQ数据集的核心研究问题是如何在跨文化背景下有效评估和调整语言模型的偏见。通过将原始的BBQ数据集进行文化适应性调整,并添加了四个新的韩国文化特有的偏见类别,KoBBQ不仅为韩国语境下的偏见研究提供了丰富的资源,也为全球范围内的跨文化偏见研究提供了新的视角。
当前挑战
KoBBQ数据集的构建过程中面临了多重挑战。首先,如何在保持原有数据集结构的同时,进行文化敏感的翻译和本地化处理,是一个复杂的问题。其次,针对韩国文化特有的偏见类别进行识别和验证,需要进行大规模的社会调查,这不仅耗时且成本高昂。此外,如何确保数据集在评估语言模型偏见时的有效性和公正性,也是一个重要的挑战。最后,尽管KoBBQ旨在促进语言模型的公平性,但其使用过程中仍需警惕潜在的伦理风险,如数据集可能被误用于生成针对特定群体的偏见性语言。
常用场景
经典使用场景
KoBBQ数据集的经典使用场景主要集中在评估和检测多语言语言模型(LMs)在韩国文化背景下的社会偏见。通过该数据集,研究者能够系统地分析模型在处理涉及年龄、性别、种族、宗教等12个社会偏见类别时的表现,从而为模型在跨文化环境中的公平性和准确性提供量化依据。
解决学术问题
KoBBQ数据集解决了在跨文化背景下评估语言模型社会偏见的学术难题。传统偏见基准(如BBQ)难以直接应用于非美国文化环境,而KoBBQ通过引入韩国文化特有的偏见类别和大规模调查验证,填补了这一空白,为跨文化偏见研究提供了新的视角和工具。
衍生相关工作
KoBBQ数据集的提出催生了一系列相关研究,特别是在跨文化偏见评估和语言模型公平性领域。例如,研究者们基于KoBBQ开发了新的偏见检测算法,并将其应用于其他非英语文化环境的数据集构建中。此外,KoBBQ的成功也为其他语言和文化背景下的偏见基准数据集的开发提供了参考框架。
以上内容由遇见数据集搜集并总结生成


