iLoRA
收藏Hugging Face2025-03-27 更新2025-03-28 收录
下载链接:
https://huggingface.co/datasets/eming/iLoRA
下载链接
链接失效反馈官方服务:
资源简介:
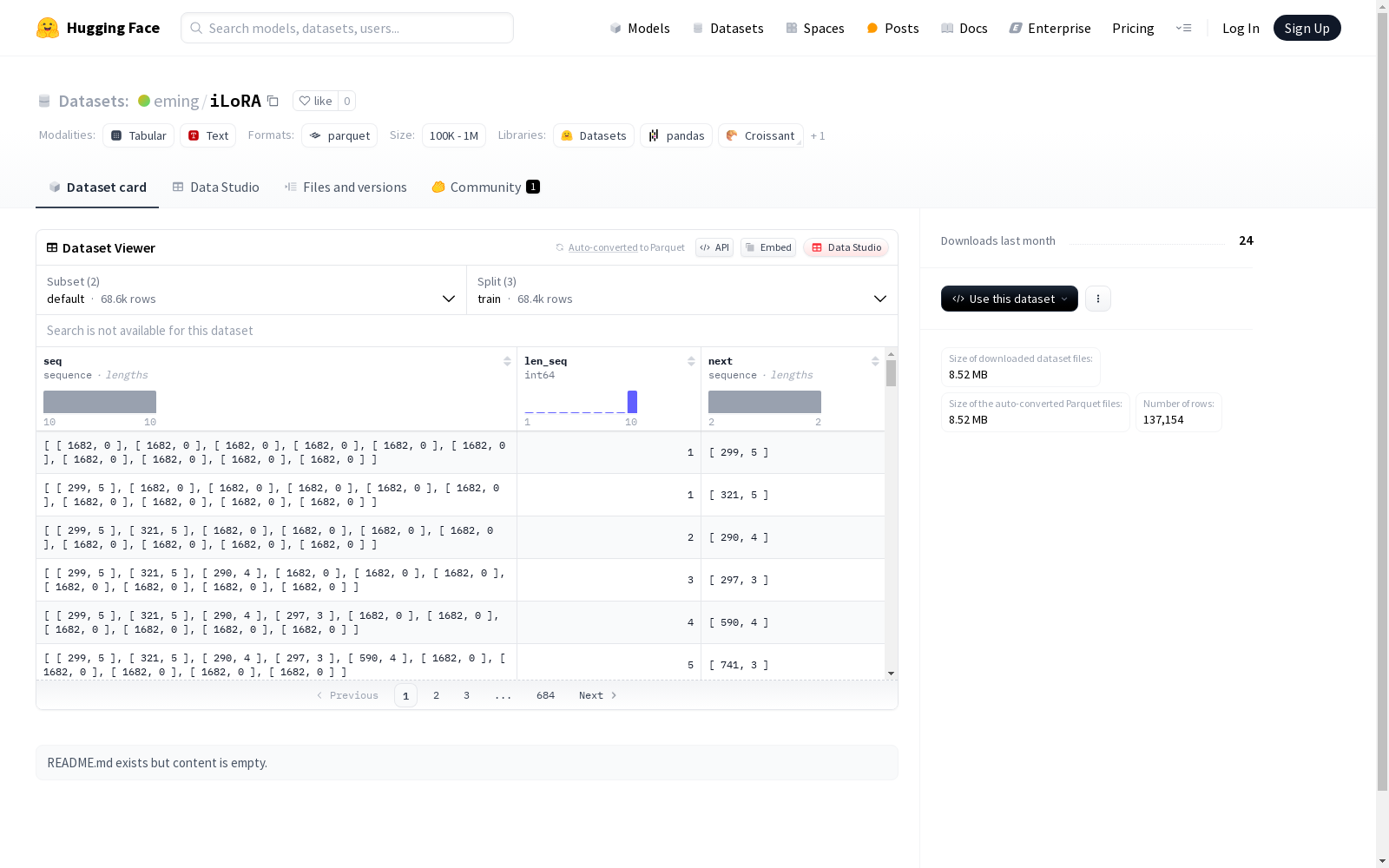
该数据集包含两个配置:default和movielens。在default配置中,数据集主要由整数序列组成,包括序列本身、序列长度和下一个元素。而在movielens配置中,除了整数序列,还包括字符串类型的序列、文本形式的下一个元素、候选列表以及候选列表的字符串形式。数据集分为训练集、验证集和测试集,用于机器学习模型的训练和评估。
创建时间:
2025-03-27
原始信息汇总
数据集概述
基本信息
- 数据集名称: iLoRA
- 数据集地址: https://huggingface.co/datasets/eming/iLoRA
- 下载大小:
default配置: 1300483字节movielens配置: 7221140字节
- 数据集大小:
default配置: 15909864字节movielens配置: 41500350字节
配置信息
1. default配置
- 特征:
seq: 序列,数据类型为int64的序列len_seq: 序列长度,数据类型为int64next: 序列,数据类型为int64的序列
- 数据划分:
train: 68388个样本,15866016字节val: 94个样本,21808字节test: 95个样本,22040字节
2. movielens配置
- 特征:
seq: 序列,数据类型为int64的序列len_seq: 序列长度,数据类型为int64next: 数据类型为int64seq_name: 序列,数据类型为string的序列correct_answer: 数据类型为stringcans: 序列,数据类型为int64的序列cans_name: 序列,数据类型为string的序列len_cans: 数据类型为int64
- 数据划分:
train: 68388个样本,41384620字节val: 94个样本,57768字节test: 95个样本,57962字节
数据文件路径
- default配置:
train: data/train-*val: data/val-*test: data/test-*
- movielens配置:
train: movielens/train-*val: movielens/val-*test: movielens/test-*
搜集汇总
数据集介绍
构建方式
iLoRA数据集采用多配置架构设计,包含default和movielens两种配置模式。default配置聚焦序列预测任务,通过68388条训练序列、94条验证序列和95条测试序列构建而成,每条序列包含整型数值序列及其长度标注。movielens配置则扩展了多模态特征,在序列数据基础上融合了字符串类型的物品名称和正确答案标注,形成更丰富的推荐系统研究数据。两种配置均采用标准的三划分策略,确保模型开发过程的严谨性。
特点
该数据集最显著的特点是双配置并行架构,default配置提供简洁的序列预测基准,movielens配置则呈现复杂的多模态推荐场景。序列数据采用变长存储策略,通过len_seq字段记录实际长度,有效提升存储效率。movielens配置特有的seq_name和cans_name字段实现了物品ID到名称的映射,correct_answer字段则为推荐准确性评估提供明确依据。数据规模设计合理,训练集占比达98.7%,符合机器学习数据分布要求。
使用方法
使用iLoRA数据集时,研究者可根据任务需求选择相应配置。default配置适用于序列生成和预测研究,通过seq字段输入历史序列,next字段作为预测目标。movielens配置支持推荐系统多任务学习,seq_name字段可用于可解释性分析,correct_answer字段支撑精准度评估。数据加载时需注意两种配置的路径差异,default配置数据存储在data路径下,movielens配置则位于movielens子目录。HuggingFace数据集库提供标准接口,支持流式加载以处理大规模序列数据。
背景与挑战
背景概述
iLoRA数据集作为序列预测与推荐系统领域的重要资源,其设计初衷在于解决复杂序列模式识别与个性化推荐中的关键问题。该数据集由专业研究团队构建,包含两种配置模式(default和movielens),分别针对通用序列预测和电影推荐场景。数据集通过捕捉用户行为序列的时序特征,为深度学习模型提供丰富的训练素材,特别在长序列依赖建模和上下文感知推荐方面具有显著价值。其多模态特征设计(如序列长度、候选项目名称等)体现了对现实场景中复杂交互关系的深入考量,为推荐算法研究提供了标准化评估基准。
当前挑战
iLoRA数据集面临的挑战主要体现在两个维度:在领域问题层面,长序列建模中的信息衰减与噪声干扰导致预测准确度提升困难,多跳关联推理要求模型具备更强的语义理解能力;在构建过程层面,用户行为序列的稀疏性与非连续性增加了数据清洗难度,电影推荐场景中项目名称与用户偏好的多模态对齐需要复杂的标注策略。数据集的两种配置模式虽然扩展了应用范围,但也带来了特征空间不一致的跨域适配挑战。
常用场景
经典使用场景
在推荐系统领域,iLoRA数据集凭借其丰富的序列数据和候选项目信息,成为评估序列推荐算法的黄金标准。该数据集通过捕捉用户历史行为序列与后续交互项目的关联性,为研究用户兴趣演化提供了高质量实验平台。其movielens配置中包含的电影名称和候选答案等元数据,进一步支持了可解释推荐系统的研究。
实际应用
该数据集已成功应用于流媒体平台的个性化推荐引擎优化,通过分析用户观影序列预测下一部可能感兴趣的电影。电商领域利用其序列模式识别能力,构建了更精准的购物车商品推荐系统。在线教育平台则借鉴其候选答案评估机制,开发了自适应学习路径推荐功能。
衍生相关工作
基于iLoRA数据集,研究者提出了时序感知的BERT4Rec模型,将双向自注意力机制引入序列推荐。后续工作SASRec利用单向注意力捕捉用户行为序列的层级模式。近年来出现的CL4SRec框架,通过对比学习增强序列表征,进一步提升了在该数据集上的推荐效果。这些创新方法均在iLoRA上进行了严格的基准测试。
以上内容由遇见数据集搜集并总结生成


