ragtruth-de-translated
收藏Hugging Face2025-04-07 更新2025-04-08 收录
下载链接:
https://huggingface.co/datasets/KRLabsOrg/ragtruth-de-translated
下载链接
链接失效反馈官方服务:
资源简介:
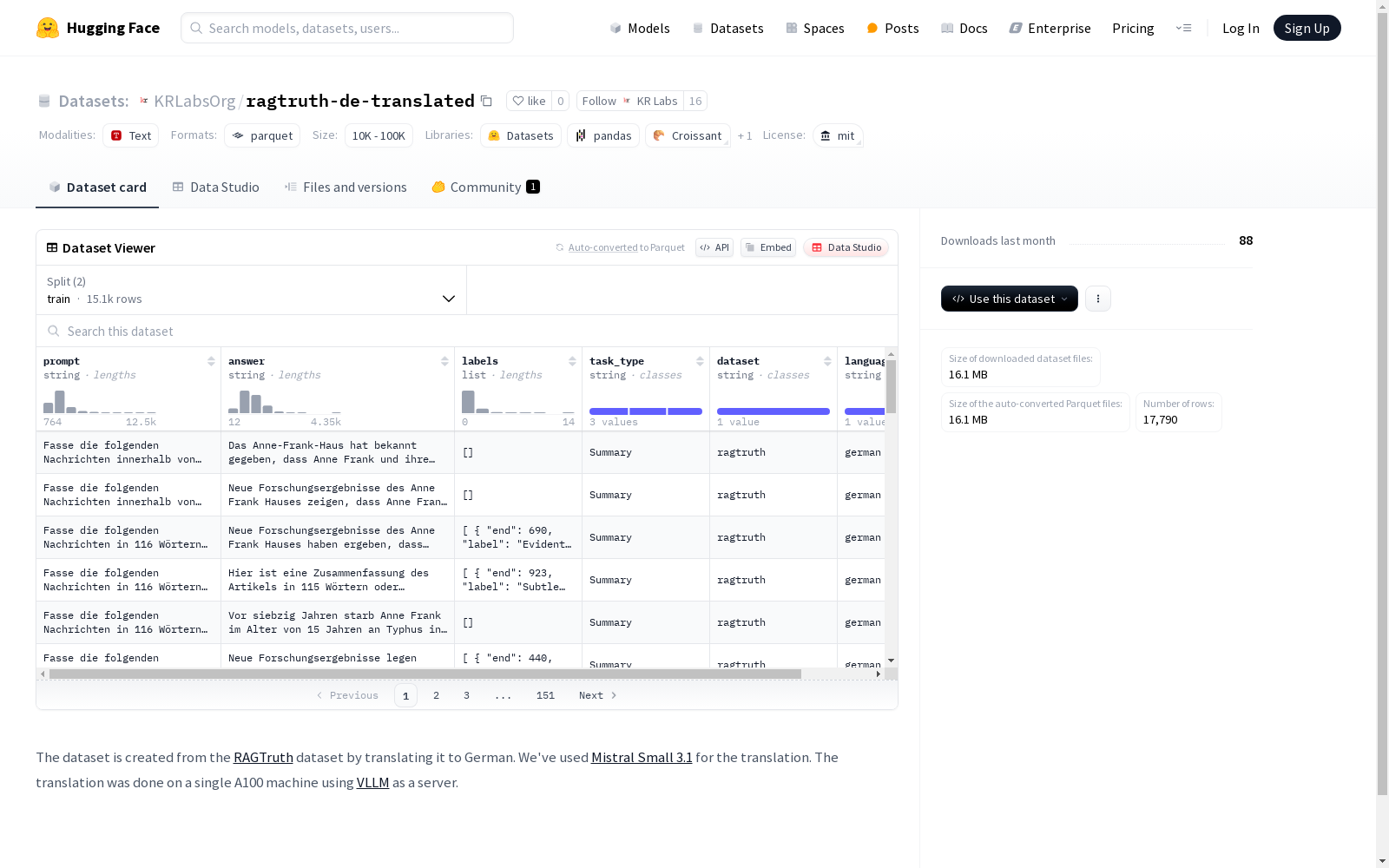
这是一个由RAGTruth数据集翻译成德语的数据集。它包含了prompt、answer、labels(包括结束位置、标签、起始位置)、任务类型、数据集名称和语言等字段。数据集分为训练集和测试集,可用于自然语言处理任务。
This is a dataset translated into German from the RAGTruth dataset. It includes fields such as prompt, answer, labels (including end position, label, and start position), task type, dataset name, and language. The dataset is divided into training and test sets, and can be applied to natural language processing (NLP) tasks.
创建时间:
2025-03-24
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,多语言数据集的构建对跨语言研究具有重要意义。ragtruth-de-translated数据集基于RAGTruth原始数据集,采用Mistral Small 3.1模型进行德语翻译,该过程在配备A100显卡的服务器上完成,并借助VLLM框架实现高效推理。翻译过程注重保持原始语义的准确性,为德语自然语言处理任务提供了可靠的数据支持。
特点
该数据集包含15,090条训练样本和2,700条测试样本,涵盖prompt、answer、labels等多个结构化字段。labels字段采用细粒度标注,包含起止位置、标签类型等元信息,支持序列标注等多种任务类型。数据以JSON格式存储,总大小约69.7MB,其多字段设计为研究者提供了灵活的建模可能性。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,默认配置包含train和test两个标准分割。使用load_dataset方法时需指定数据集名称及分割参数,数据字段可直接用于德语问答系统训练或序列标注任务。对于特定研究需求,可结合task_type字段筛选不同任务子集,或利用language字段实现多语言对比分析。
背景与挑战
背景概述
ragtruth-de-translated数据集源自ACL 2024会议发表的RAGTruth研究,该研究聚焦于检索增强生成(RAG)系统的真实性评估问题。作为RAGTruth的德语翻译版本,本数据集由研究人员采用Mistral Small 3.1模型在A100计算设备上完成跨语言转换,通过VLLM推理框架实现高效处理。数据集包含15,090条训练样本和2,700条测试样本,涵盖提示文本、生成答案及真实性标注三元组(起始位置、终止位置、标签),为德语NLP社区提供了评估生成文本事实准确性的重要基准。其多任务类型设计反映了当前大语言模型在跨语言场景下的可信度验证需求。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,德语与英语语言结构的差异性导致传统真实性评估指标可能失效,需要建立适应德语语法特性的标注体系;多任务类型标注的兼容性要求模型同时处理事实核查、矛盾检测等异构任务。在构建过程中,机器翻译引入的语义偏移现象对标签位置映射造成干扰,特别是复合词处理与语序差异导致实体边界识别困难;VLLM框架的批处理机制虽提升效率,但长文本的显存占用问题限制了单次处理的上下文窗口大小。
常用场景
经典使用场景
在机器翻译与跨语言信息检索领域,ragtruth-de-translated数据集为研究者提供了德语环境下评估检索增强生成系统性能的基准。其包含的提示-答案对及标注信息,特别适合用于测试模型在德语语境中处理事实一致性、语义连贯性的能力,成为比较不同翻译模型输出质量的标准化工具。
实际应用
在商业搜索引擎优化场景中,该数据集可优化德语区智能客服系统的响应准确性。教育机构利用其构建双语教学工具时,能够通过对比原始英语与德语译文,自动检测课程材料翻译的知识点损耗,显著提升跨语言教育资源的转换效率。
衍生相关工作
基于该数据集衍生的研究包括跨语言检索增强生成框架X-RAG,其通过联合训练策略提升了德语生成质量。ACL 2024发表的《Multilingual Fact Verification》论文采用该数据集作为核心评估基准,开创了多语言事实核查任务的新范式。
以上内容由遇见数据集搜集并总结生成


