scorpio-gene-taxa
收藏Hugging Face2025-01-21 更新2025-01-22 收录
下载链接:
https://huggingface.co/datasets/MsAlEhR/scorpio-gene-taxa
下载链接
链接失效反馈官方服务:
资源简介:
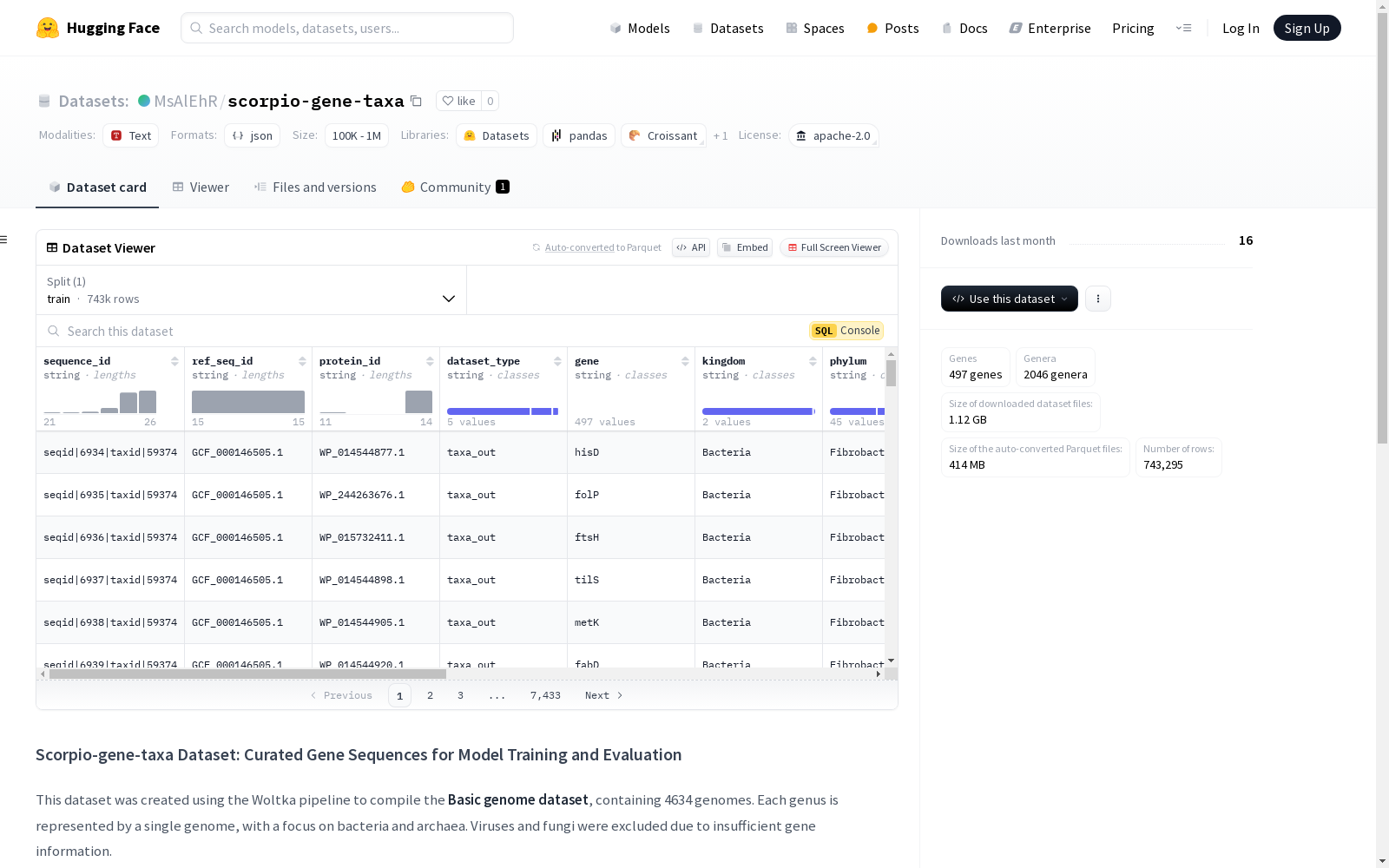
Scorpio-gene-taxa数据集是通过Woltka管道编译的,包含4634个基因组,每个属由一个基因组代表,主要集中在细菌和古菌上,排除了病毒和真菌。数据集包含497个基因和2046个属。数据集分为训练集、测试集、Taxa_out和Gene_out四个部分,分别用于模型训练、序列泛化、基因泛化和分类泛化。
创建时间:
2025-01-16
搜集汇总
数据集介绍
构建方式
Scorpio-gene-taxa数据集通过Woltka流程构建,精选了4634个基因组,涵盖细菌和古菌的2046个属。每个属仅包含一个代表性基因组,排除了病毒和真菌,因其基因信息不足。数据集包含497个基因,分为训练集、测试集、Taxa_out和Gene_out四个部分,分别用于模型训练、序列泛化、基因泛化和分类泛化。
特点
该数据集的特点在于其高度精选的基因组和基因序列,专注于细菌和古菌的多样性。训练集和测试集的设计确保了序列的泛化能力,而Taxa_out和Gene_out部分则分别用于评估基因和分类的泛化性能。数据集的结构清晰,适用于多种生物信息学任务,特别是DNA序列的下游分析。
使用方法
使用Scorpio-gene-taxa数据集时,首先加载训练集进行模型训练,随后利用测试集评估模型的序列泛化能力。Taxa_out和Gene_out部分可用于进一步验证模型在基因和分类层面的泛化性能。通过这种方式,研究人员能够全面评估和改进DNA序列分析的嵌入方法,提升下游分析的准确性。
背景与挑战
背景概述
Scorpio-gene-taxa数据集由Mohammadsaleh Refahi等人于2024年创建,旨在为DNA序列的下游分析提供高质量的基因序列数据。该数据集基于Woltka流程构建,涵盖了4634个基因组,重点关注细菌和古菌,排除了病毒和真菌。数据集包含497个基因和2046个属,分为训练集、测试集、Taxa_out和Gene_out四个部分,分别用于模型训练、序列泛化、基因泛化和分类泛化。该数据集的研究成果发表于bioRxiv预印本平台,为基因组学和生物信息学领域提供了重要的数据支持。
当前挑战
Scorpio-gene-taxa数据集在构建和应用过程中面临多重挑战。首先,基因序列的多样性和复杂性使得数据集的构建需要高度精确的筛选和分类,以确保数据的代表性和可靠性。其次,由于病毒和真菌的基因信息不足,数据集的覆盖范围受到限制,可能影响其在某些特定领域的应用。此外,数据集的泛化能力测试要求严格的实验设计,以确保模型在不同基因和分类群中的表现具有可比性。这些挑战不仅考验了数据集的构建质量,也对后续的模型训练和评估提出了更高的要求。
常用场景
经典使用场景
Scorpio-gene-taxa数据集在生物信息学领域中被广泛用于基因序列的分类和功能预测。该数据集通过精心筛选的4634个基因组,涵盖了2046个属的497个基因,特别聚焦于细菌和古菌的基因组。研究人员利用该数据集进行模型训练和评估,以提升基因序列的嵌入表示能力,从而在基因组学分析中实现更高的准确性和泛化能力。
衍生相关工作
基于Scorpio-gene-taxa数据集,多项经典研究工作得以展开。例如,Refahi等人(2024)提出的Scorpio方法,利用该数据集优化了基因序列的嵌入表示,显著提升了基因组学下游分析的性能。此外,该数据集还启发了其他研究团队开发新的机器学习模型,用于基因序列的分类和功能预测,进一步推动了生物信息学领域的技术创新。
数据集最近研究
最新研究方向
在生物信息学领域,基因序列数据的分析与建模一直是研究的热点。Scorpio-gene-taxa数据集通过精心筛选的4634个基因组,涵盖了2046个属的497个基因,为模型训练和评估提供了高质量的基准数据。近年来,随着深度学习技术在基因组学中的应用日益广泛,该数据集在基因嵌入(gene embedding)和下游分析任务中的表现备受关注。特别是在增强基因序列嵌入以提升分类和预测性能方面,Scorpio数据集的研究成果为微生物组学、病原体检测和进化分析等领域提供了新的工具和方法。其独特的训练、测试和泛化子集设计,进一步推动了基因序列模型在跨属和跨基因泛化能力上的突破,为生物医学研究带来了深远影响。
以上内容由遇见数据集搜集并总结生成


