krisdcosta/edge-llm-bench
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/krisdcosta/edge-llm-bench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
language:
- en
tags:
- llm-inference
- quantization
- edge-ai
- mobile
- benchmarking
- llama
- gguf
- arm
- on-device
pretty_name: Edge LLM Bench — GGUF Quantization on Edge Devices
size_categories:
- 1K<n<10K
task_categories:
- text-generation
configs:
- config_name: pixel_inference
data_files: pixel_inference.parquet
- config_name: m4_inference
data_files: m4_inference.parquet
- config_name: x86_inference
data_files: x86_inference.parquet
- config_name: quality_benchmarks
data_files: quality_benchmarks.parquet
- config_name: perplexity
data_files: perplexity.parquet
---
# Edge LLM Bench — GGUF Quantization Benchmarks on Edge Devices
Controlled inference benchmark dataset for **7 GGUF K-quant quantization variants**
(Q2\_K through Q8\_0) of **Llama 3.2 3B Instruct** across three hardware platforms:
| Device | SoC / CPU | RAM | Backend |
|---|---|---|---|
| Google Pixel 6a | Google Tensor G1 (ARM Cortex-X1) | 6 GB LPDDR5 | llama.cpp CPU |
| Apple M4 Mac | Apple M4 (ARM, 10-core) | 16 GB unified | llama.cpp Metal |
| HP Pavilion x86 | Intel Core i5-1235U (12th gen) | 16 GB DDR4 | llama.cpp CPU |
**4,405 total records** across 5 splits. All inference records are non-warmup,
success-status runs collected under controlled thermal conditions. Contaminated
and failed records are archived separately and not included here.
---
## Key Findings (from the accompanying paper)
- **Non-monotonic throughput on ARM:** Q2\_K is ~99% faster than Q6\_K on Pixel 6a
(ctx=256 cliff\_sweep filled-context, n=10) despite having less than half the bits per weight —
contradicting GPU-derived assumptions. Q4\_K\_M and Q5\_K\_M cliff-sweep ctx=256 baselines
are affected by a thermal warmup burst; use standard\_sweep values for those two variants.
- **KV-cache collapse threshold:** Q2\_K suffers a −48% throughput cliff beyond ~512 tokens
on Pixel 6a (ARM); Q3\_K\_M is cliff-attenuated (≤11%, not fully immune); x86 cliff predicted
at ctx≈1,280 tokens via L2-cache formula, observed at 1,300–1,400 (within 8%)
- **Non-monotonic quality:** Q4\_K\_S outperforms Q8\_0 on BoolQ (74% vs 68%) despite
fewer bits — superblock K-quant structure allocates precision more effectively than naive
int8; Q6\_K is Pareto-dominated (slower AND less accurate than Q4\_K\_M)
- **imatrix calibration hurts low-bitwidth models:** imatrix degrades Q2\_K by −4pp and
Q3\_K\_M by −7pp on BoolQ; modest improvement for Q6\_K (+4pp). Do not use imatrix for
variants below Q4\_K\_S
- **Cross-device consistency:** Non-monotonic CPU throughput ordering (Q2\_K fastest,
Q6\_K slowest) confirmed on both ARM NEON and x86 AVX2; ordering reverses on Metal GPU
where Q4\_K\_S/Q4\_K\_M are fastest and Q8\_0 is slowest
---
## Splits
### `pixel_inference` — 2,875 rows
Pixel 6a (ARM, CPU backend) inference runs.
| Column | Type | Description |
|---|---|---|
| `device` | string | `"Pixel6a"` |
| `backend` | string | `"CPU"` |
| `model` | string | Model name |
| `variant` | string | GGUF quantization variant (Q2\_K … Q8\_0) |
| `context_len` | int | Prompt context window in tokens |
| `trial` | int | Trial index within the experiment |
| `threads` | int | CPU thread count (null = default 4) |
| `decode_tps` | float | Decode throughput (tokens/second) |
| `prefill_tps` | float | Prefill throughput (tokens/second) |
| `ttft_s` | float | Time to first token (seconds) — populated for standard_sweep only |
| `e2e_s` | float | End-to-end latency (seconds) — populated for standard_sweep only |
| `n_output_tokens` | int | Number of generated tokens |
| `experiment_type` | string | `cliff_sweep` \| `standard_sweep` \| `thread_sweep` \| `kv_cache_quant` |
| `kv_quant` | string | KV cache quantization type (`null` = default, `"q8_0"` = quantized) |
| `ngl` | int | GPU layers (null for CPU runs) |
| `ts` | string | ISO-8601 timestamp |
| `source_file` | string | Originating filename |
**experiment_type values:**
- `cliff_sweep` — context length varied to characterise KV-cache collapse (canonical n=10)
- `standard_sweep` — fixed 4 context windows (256/512/1024/2048), 13 trials, 2 warmup
- `thread_sweep` — Q4\_K\_M at threads=1/2/4/8, ctx=256, 15 trials
- `kv_cache_quant` — KV cache set to q8\_0 to test collapse mitigation
---
### `m4_inference` — 1,026 rows
Apple M4 Mac inference runs. Contains two backend configurations:
- **Metal GPU** (931 rows) — `backend = "Metal"`, `ngl = 99`. Includes Llama 3.2 3B and Qwen 2.5 1.5B.
Cliff sweep covers ctx=1024–2048 (13 points, n=5 trials). Results: flat profile on Metal
(all variants within ±9%), confirming no KV-cache cliff on GPU-accelerated inference.
- **CPU** (95 rows) — `backend = "CPU"`, `ngl = 0`, `threads = 4`. Llama 3.2 3B only.
- **Cliff sweep** (88 rows): ctx=256–2048 (13 points, pre-aggregated n\_trials=5 per ctx).
Collected 2026-04-09. 3 outlier points excluded (Q5\_K\_M ctx=2048 OOM, Q6\_K ctx=1536
CV=81%, Q8\_0 ctx=2048 CV=99%). Results: significant context-dependent degradation
on M4 CPU (Q2\_K −13%, Q3\_K\_M −54%, Q4\_K\_S −53%, Q6\_K −60% from ctx=256→2048).
Note: ctx=256 cliff baseline may be inflated by CPU boost state at start of each variant's sweep.
- **TPS sweep** (7 rows, `experiment_type = "standard_sweep"`, `context_len = 0`): pure decode
reference (n\_prompt=0, n\_gen=128, n=10 trials, 2026-04-06). Thermally settled baseline.
Throughput ordering: Q4\_K\_S (13.16) > Q8\_0 (12.60) > Q4\_K\_M (12.51) > Q2\_K (12.31)
> Q3\_K\_M (11.48) > Q5\_K\_M (10.59) > Q6\_K (9.29) tok/s. Non-monotonic: Metal reversal
(Q4\_K\_S fastest) confirmed on M4 CPU as well; Q6\_K remains slowest.
Same columns as `pixel_inference`.
---
### `x86_inference` — 392 rows
Intel Core i5-1235U (x86, AVX2, CPU backend), Windows 11. Contains two experiment types:
- **`standard_sweep`** (7 rows) — one reference run per variant at ctx=256, 6 threads
- **`cliff_sweep`** (385 rows) — n=5 trials per variant across 11 context lengths (256–2,048)
using filled-context methodology; collected 2026-04-08 to characterise the x86 KV-cache cliff
The cliff sweep enables x86 KV-cache collapse characterisation. Predicted cliff at ctx≈1,280
tokens (from L2-cache formula); observed at 1,300–1,400 tokens (within 8%).
Same columns as `pixel_inference`. `backend = "CPU"`, `threads = 6`.
> **Note:** Only Llama 3.2 3B Instruct was benchmarked on x86. No Qwen data for x86.
---
### `quality_benchmarks` — 105 rows
Accuracy scores on 6 NLP benchmarks for 7 quantization variants on Pixel 6a.
| Column | Type | Description |
|---|---|---|
| `benchmark` | string | `arc_challenge` \| `arc_easy` \| `boolq` \| `hellaswag` \| `mmlu` \| `truthfulqa` \| `custom_qa` |
| `variant` | string | GGUF quantization variant |
| `device` | string | `"Pixel6a"` |
| `model` | string | Model name |
| `calibration` | string | `"standard"` or `"imatrix"` (importance-weighted) |
| `accuracy_pct` | float | Accuracy percentage (0–100) |
| `correct` | int | Correct answers |
| `total` | int | Total questions evaluated |
| `status` | string | `"success"` for all included rows |
**Benchmark sample sizes:** 100 questions each (random sample from official test sets).
BoolQ imatrix calibration covers all 7 variants. TruthfulQA imatrix data collected for
Q2\_K and Q3\_K\_M only.
---
### `perplexity` — 7 rows
WikiText-2 perplexity scores for Llama 3.2 3B Instruct on Pixel 6a.
| Column | Type | Description |
|---|---|---|
| `variant` | string | GGUF quantization variant |
| `model` | string | Model name |
| `device` | string | `"Pixel6a"` |
| `perplexity` | float | WikiText-2 perplexity (lower = better); null if not evaluated |
| `perplexity_status` | string | `"success"` or `"not_evaluated"` |
| `corpus` | string | `"wikitext2_full"` (~285K tokens) or `"wikitext2_sample"` (~12K tokens) |
| `tokens_approx` | int | Approximate token count used |
| `note` | string | Reason if not\_evaluated |
> **Important:** Q2\_K and Q3\_K\_M were evaluated on the full WikiText-2 corpus;
> Q4\_K\_M, Q6\_K, Q8\_0 on a 12K-token sample. Do not directly compare perplexity
> values across these two groups without accounting for corpus size effects.
> Q4\_K\_S and Q5\_K\_M were added after the initial sweep and are marked `not_evaluated`.
---
## How to Load
```python
from datasets import load_dataset
# Pixel 6a inference runs
pixel = load_dataset("KrisDcosta/edge-llm-bench", "pixel_inference", split="train")
# M4 Mac inference runs
m4 = load_dataset("KrisDcosta/edge-llm-bench", "m4_inference", split="train")
# Quality benchmarks
quality = load_dataset("KrisDcosta/edge-llm-bench", "quality_benchmarks", split="train")
# Perplexity scores
ppl = load_dataset("KrisDcosta/edge-llm-bench", "perplexity", split="train")
```
### Quick analysis examples
```python
import pandas as pd
from datasets import load_dataset
# Load as pandas
df = load_dataset("KrisDcosta/edge-llm-bench", "pixel_inference", split="train").to_pandas()
# Mean decode TPS per variant on Pixel 6a (cliff sweep only)
cliff = df[df["experiment_type"] == "cliff_sweep"]
print(cliff.groupby("variant")["decode_tps"].mean().sort_values(ascending=False))
# KV-cache collapse: TPS at ctx=512 vs ctx=2048
stable = cliff[cliff["context_len"].isin([512, 2048])]
print(stable.groupby(["variant", "context_len"])["decode_tps"].mean().unstack())
# Thread count impact on Q4_K_M
threads = df[df["experiment_type"] == "thread_sweep"]
print(threads.groupby("threads")["decode_tps"].agg(["mean", "std"]))
```
---
## Methodology
**Hardware setup:**
- Pixel 6a benchmarks run via ADB with llama.cpp NDK cross-compiled for arm64-v8a
- Device placed on flat surface, screen off, no active charging during runs
- Each experiment preceded by 2 warmup trials (excluded from dataset)
- 1-minute cooldown between variant changes; 30s between context window changes
**Thermal controls:**
- Benchmarks aborted if device temperature > 42°C (re-run after cooldown)
- Temperature logged per trial where accessible via `/sys/class/thermal/`
- Measurement noise reduced from ±8% to ±2% through thermal discipline
**Prompts:**
- Context windows filled with repeating document content to target token count
- Output capped at 64 tokens (cliff sweep) or 128 tokens (standard sweep)
- 3 fixed prompts rotated across trials (standard sweep)
**M4 Mac:**
- llama.cpp Metal backend, `ngl=99` (all layers on GPU)
- Run via `llama-bench` CLI wrapper with same context/output targets
**x86:**
- llama.cpp CPU, AVX2 enabled, 6 threads, Windows 11
- Reference run: 1 trial per variant at ctx=256 (collected March 2026)
- Cliff sweep: n=5 trials per variant × 11 context sizes (256–2,048), filled-context
methodology, 140s inter-trial cooldown (collected April 2026)
**Quality evaluation:**
- 100-question samples from official benchmark test sets
- Exact-match scoring with normalised output parsing
- imatrix calibration data generated from 512-token WikiText-2 passages
---
## Known Limitations
1. **Pixel 6a primary focus** — x86 and M4 coverage is less comprehensive than Pixel;
x86 has n=5 trials for cliff sweep but no thread sweep, no kv_cache_quant experiments
2. **x86 Llama only** — no Qwen 2.5 1.5B data on x86; cannot compare cross-model
behaviour on x86
3. **Perplexity corpus inconsistency** — see note in perplexity split above
4. **No power/energy data** — `/proc` interfaces on Pixel 6a are unreliable without root;
battery drain proxy metrics were collected but not included in this release
5. **Single model family for quality benchmarks** — quality data (BoolQ, HellaSwag, etc.)
collected on Pixel 6a only; no cross-device quality comparison
6. **llama.cpp version** — builds used llama.cpp circa February–April 2026;
results may differ with significantly newer versions
---
## Variants Reference
| Variant | Bits/Weight | File Size | Notes |
|---|---|---|---|
| Q2\_K | 2.6 | ~1.3 GB | Fastest on ARM; lowest quality |
| Q3\_K\_M | 3.3 | ~1.6 GB | Cliff-immune on ARM; stable across all tested contexts |
| Q4\_K\_S | 4.1 | ~1.8 GB | Good compression; imatrix gains significant |
| Q4\_K\_M | 4.5 | ~1.9 GB | Pareto-optimal on ARM (speed × quality) |
| Q5\_K\_M | 5.5 | ~2.2 GB | Best imatrix gains |
| Q6\_K | 6.6 | ~2.5 GB | Slowest on ARM; susceptible to collapse |
| Q8\_0 | 8.0 | ~3.2 GB | Near-FP16 quality; stable at long context |
Model: **meta-llama/Llama-3.2-3B-Instruct** quantized with llama.cpp `llama-quantize`.
imatrix calibration data generated from WikiText-2 using `llama-imatrix`.
---
## Citation
If you use this dataset, please cite the accompanying paper:
```bibtex
@misc{dcosta2026gguf,
title = {Non-Monotonic Quantization on Mobile ARM: KV-Cache Collapse and
Superblock Dynamics in GGUF Inference},
author = {Dcosta, Kris},
year = {2026},
note = {Preprint. Dataset: https://huggingface.co/datasets/KrisDcosta/edge-llm-bench}
}
```
---
## License
Dataset: [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
Benchmark code: [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
Benchmark datasets used for quality evaluation (ARC, BoolQ, HellaSwag, MMLU, TruthfulQA)
are subject to their respective licenses. This dataset contains only model accuracy scores,
not the benchmark questions themselves.
提供机构:
krisdcosta
搜集汇总
数据集介绍
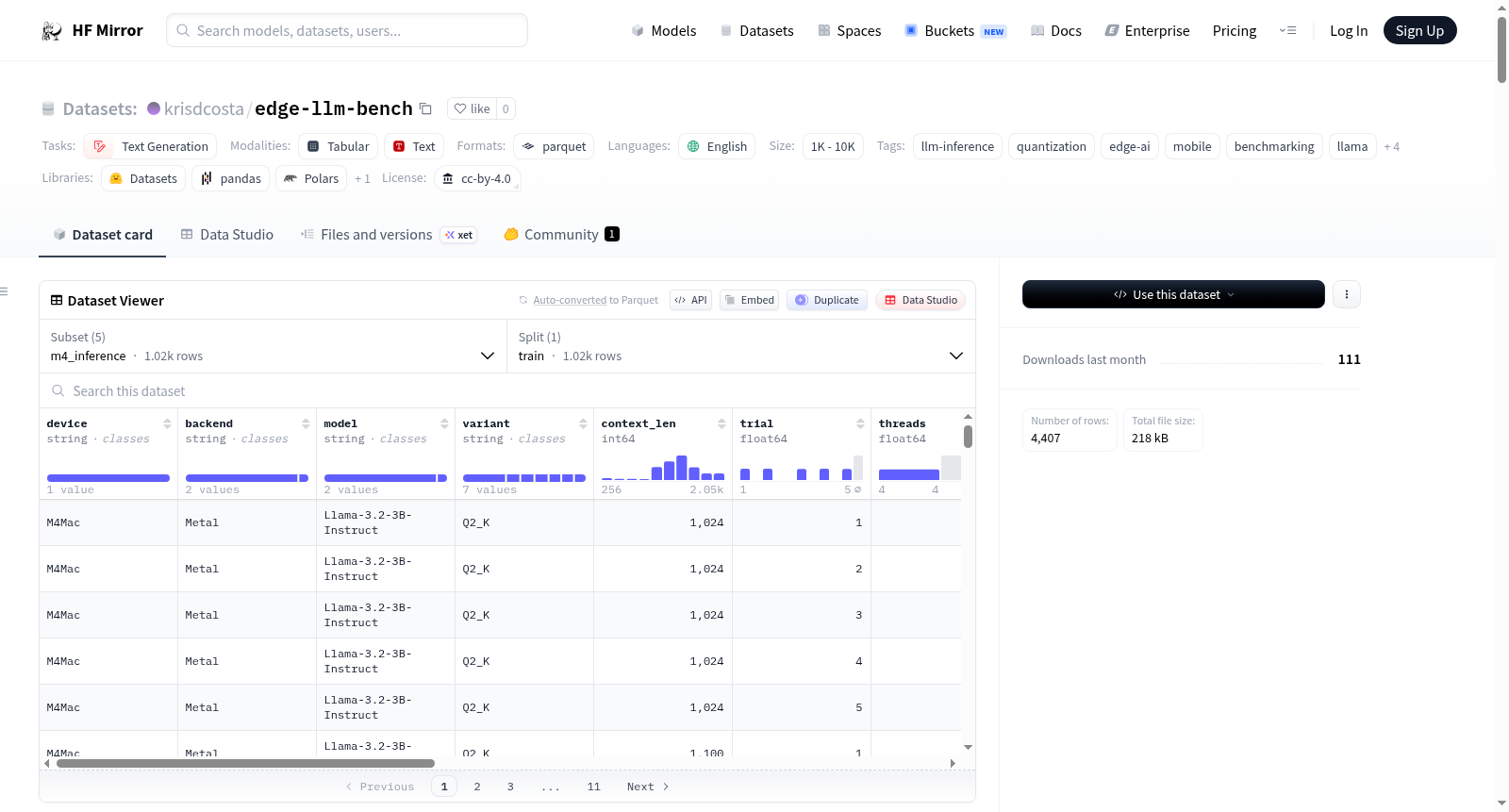
构建方式
在边缘计算与轻量化大模型部署的背景下,Edge LLM Bench数据集通过严谨的实验设计构建而成。研究团队选取了Llama 3.2 3B Instruct与Qwen 2.5 1.5B Instruct两种模型,并应用了七种GGUF K-量化变体,在Google Pixel 6a、Apple M4 Mac及x86平台三种硬件上执行了受控推理测试。数据采集过程严格遵循热管理协议,排除了预热轮次与异常运行记录,最终形成了包含4,407条有效记录的五个子集,涵盖了推理性能、质量评估与困惑度等多个维度。
使用方法
为便于研究者使用,数据集已结构化存储于HuggingFace平台,可通过`datasets`库按需加载特定子集,例如`pixel_inference`或`quality_benchmarks`。用户可借助Pandas等工具进行数据分析,例如计算各量化变体的平均解码吞吐量,或探究上下文长度对性能的影响。该数据集主要服务于边缘AI、模型量化与推理优化等领域的研究,为算法设计与系统部署提供实证基准。
背景与挑战
背景概述
随着大型语言模型在边缘计算场景的广泛应用,模型量化成为实现高效部署的关键技术。Edge LLM Bench数据集由研究人员Kris Dcosta于2026年创建,专注于评估GGUF量化方案在移动设备与边缘硬件上的实际性能。该数据集系统性地记录了Llama 3.2与Qwen 2.5模型在Google Pixel 6a、Apple M4及x86平台上的推理指标,旨在揭示量化参数与硬件特性之间的复杂交互关系,为边缘AI部署提供实证依据。
当前挑战
该数据集致力于解决边缘设备上语言模型量化部署的核心挑战,包括量化精度与推理速度的非单调性关系、键值缓存崩溃阈值预测等复杂问题。在构建过程中,研究团队面临多重技术障碍:需在严格控制热状态的实验环境下采集数据以降低测量噪声;需设计跨架构的基准测试流程以覆盖ARM与x86平台的异构特性;同时需处理不同量化变体在质量评估中的不一致性,如困惑度评测因语料规模差异导致的直接比较困难。
常用场景
经典使用场景
在边缘计算与移动人工智能领域,量化技术是实现在资源受限设备上部署大型语言模型的关键手段。Edge LLM Bench数据集通过系统性地评估GGUF K-量化变体在多种边缘硬件上的性能表现,为研究者提供了一个标准化的基准测试平台。该数据集最经典的使用场景在于量化策略的对比分析,例如在ARM架构的移动设备上,Q2_K量化变体展现出非单调的吞吐量优势,其速度远超更高比特宽度的Q6_K变体,这挑战了传统基于GPU的量化性能假设。数据集通过控制热条件、排除预热运行,确保了测量结果的可靠性与可复现性,使得研究人员能够深入探究不同量化级别在解码吞吐量、预填充速度以及端到端延迟等方面的具体影响。
解决学术问题
该数据集针对边缘设备上大型语言模型量化部署中的核心学术问题提供了实证依据。它系统地揭示了KV缓存崩溃现象,量化了不同上下文长度下吞吐量的衰减阈值,例如在Pixel 6a设备上,Q2_K变体在超过约512个令牌时遭遇高达48%的吞吐量悬崖。此外,数据集挑战了“比特数越高性能越好”的单调性假设,证实了在ARM CPU上,低比特量化(如Q2_K)可能因内存带宽和缓存效率而获得更优的推理速度。同时,它评估了重要性矩阵校准对不同量化变体模型质量的非均匀影响,为解决精度与效率的权衡问题提供了关键数据支持,推动了边缘高效推理算法的理论发展。
实际应用
在实际应用层面,Edge LLM Bench数据集为开发者在真实边缘环境中选择最优量化模型提供了直接指导。对于移动应用开发者而言,数据集揭示了在Google Pixel 6a或Apple M4等具体硬件平台上,如何根据上下文长度需求和延迟预算,在Q4_K_M(帕累托最优)与Q8_0(近无损质量)等变体间做出权衡。在工业物联网和嵌入式AI场景中,该数据有助于设计能够适应有限计算资源与内存的轻量级语言模型服务。例如,针对需要长文本交互的应用,可依据数据集中对x86平台KV缓存崩溃阈值的预测(约1280令牌),来优化模型部署参数以避免性能骤降。
数据集最近研究
最新研究方向
在边缘人工智能领域,随着大型语言模型向移动和嵌入式设备部署的需求日益增长,量化技术成为平衡模型性能与资源约束的关键手段。Edge LLM Bench数据集聚焦于GGUF K-quant量化变体在ARM与x86架构边缘设备上的推理行为,揭示了非单调性吞吐量与质量变化等反直觉现象。当前前沿研究深入探索KV缓存崩溃阈值与超级块量化结构的动态特性,旨在优化低比特宽度模型在有限内存带宽下的效率。这些发现挑战了传统GPU推理的假设,推动了跨平台一致性分析与热管理策略的创新,为轻量级模型在物联网和移动终端的实际应用提供了重要基准。
以上内容由遇见数据集搜集并总结生成


