EarthSpeciesProject/animalspeak-pseudovox
收藏Hugging Face2026-05-07 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/EarthSpeciesProject/animalspeak-pseudovox
下载链接
链接失效反馈官方服务:
资源简介:
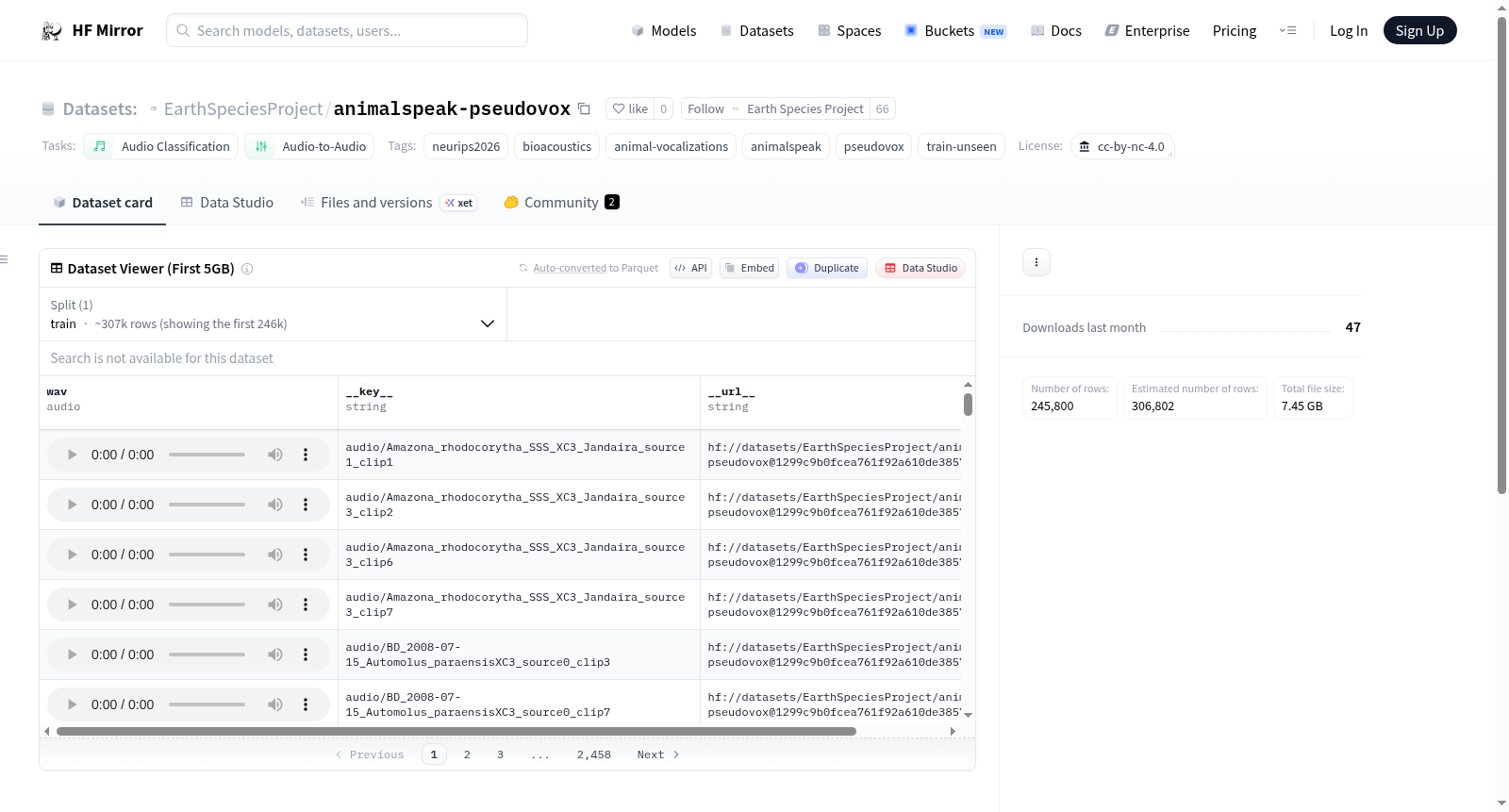
该数据集包含AnimalSpeak Pseudovox的train-unseen分割部分。每个示例都是一个经过静音修剪的短单发声WAV剪辑,附带紧凑的每剪辑元数据。数据集不包含生成的对话、字幕、问答对或多选题答案。数据集共有346,907行,分为18个分片,每个分片最多包含20,000行。文件包括WebDataset风格的分片(包含WAV音频条目)、每音频文件一行的元数据(包括ID、音频名称、持续时间、物种元数据和分类器置信度元数据)以及MLCommons Croissant元数据文件。
This dataset contains the train-unseen split of AnimalSpeak Pseudovox. Each example is a short, silence-trimmed, single-vocalization WAV clip plus compact per-clip metadata. It does not include generated conversations, captions, QA pairs, or MCQ answers. The dataset consists of 346,907 rows, divided into 18 shards with a maximum of 20,000 rows per shard. Files include WebDataset-style shards (containing WAV audio entries), metadata with one row per audio file (including ID, audio name, duration, species metadata, and classifier confidence metadata), and an MLCommons Croissant metadata file.
提供机构:
EarthSpeciesProject
搜集汇总
数据集介绍
构建方式
AnimalSpeak Pseudovox数据集的构建以深度学习驱动的生物声学研究为背景,专注于动物发声数据的标准化处理。该数据集从大规模原始录音中提取短时、经静音裁剪的单次发声WAV片段,并附有紧凑的每片段元数据。元数据涵盖音频标识符、文件名、时长、物种信息以及分类器置信度等关键字段,确保数据的高质量和可追溯性。整体采用WebDataset格式分片存储,共分为18个分片,每分片最多容纳20,000条记录,总行数达346,907条,便于高效加载与分布式训练。
特点
该数据集的核心特点在于其专注于动物发声的单一性,不包含任何生成的对话、描述或问答对,从而避免了外部文本噪声对声学模型的干扰。所有音频片段均经过静音裁剪,确保了输入的一致性。元数据中嵌入的分类器置信度信息为模型评估提供了额外的可靠性维度,而物种信息的详尽标注则支持细粒度的跨物种声学分析。此外,采用Croissant元数据标准对分片导出进行描述,增强了数据集的可复现性和互操作性。
使用方法
该数据集主要用于音频分类与音频到音频生成任务,特别适合生物声学领域的研究。用户可通过读取WebDataset分片文件(如data-20k/train-*.tar)直接加载WAV音频流,并结合元数据Parquet文件中的标识符、时长和物种标签进行模型训练。Croissant JSON文件提供了分片导出的完整元数据,便于用户快速理解数据结构并集成到现有流水线中。建议用户依据分类器置信度字段筛选高质量样本,以优化模型性能。
背景与挑战
背景概述
动物声学作为生物多样性与生态监测的核心手段,近年来随着深度学习技术的进步而快速发展,尤其是自监督学习在少样本或零样本场景下的应用日益受到关注。AnimalSpeak Pseudovox数据集由国际多机构联合创建,旨在解决动物声音识别中标注数据稀缺的瓶颈问题,其核心研究问题在于如何利用伪标签技术从海量未标记的野外录音中高效提取有效的动物发声表征。该数据集包含346,907条经过静音裁剪的单发声WAV片段及紧凑的元数据,是AnimalSpeak项目的重要组成部分,于2024年首次公开,并已被NeurIPS 2026生物声学挑战赛采用,对推动动物声学领域的开放研究与模型泛化能力评估具有重要影响力。
当前挑战
该数据集所解决的领域问题主要在于动物发声分类与检索中面临的数据稀疏性与类别不均衡挑战,具体表现为:1) 野外环境下的声学数据常包含环境噪声、混响及多物种重叠发声,导致纯净单发声样本难以获取;2) 不同物种的发声频率差异巨大,稀有物种的样本数量极少,难以支撑传统监督学习训练。在构建过程中,数据集面临的技术挑战包括:1) 从长达数千小时的野外录音中自动检测并裁剪单发声片段,需平衡准确率与召回率;2) 利用伪标签策略生成训练信号时,模型置信度阈值的选择直接影响标签质量,低置信度样本可能引入噪声,高置信度策略则加剧数据稀疏性;3) 对346,907条音频进行统一的元数据标注与质量控制,确保物种标签与声学特征的一致性,是一项繁重且易出错的工程任务。
常用场景
经典使用场景
在生物声学与动物行为研究的交叉领域中,animalspeak-pseudovox数据集以其大规模、高质量的单发声动物音频剪辑闻名。经典使用场景包括构建物种识别模型,利用346,907条沉默裁剪后的WAV样本,训练分类器以精准区分不同物种的声学特征。研究者常通过其元数据中的物种标签与置信度信息,评估模型在无监督或有监督条件下的泛化能力,尤其适合探索跨物种声学相似性的科学问题。
解决学术问题
该数据集有效回应了动物发声识别研究中的两大核心挑战:数据稀缺性与标注不一致性。通过提供规模空前的标准化音频片段和附带分类器置信度的元数据,它助力学界解决声学模型在噪声环境下的鲁棒性问题,以及跨群体、跨生态区发声模式的迁移学习难题。其成就在于推动了非人类物种声学信号处理从少数个案向大规模统计推断的范式转变,为解读动物交际系统的底层结构奠定数据基础。
衍生相关工作
基于animalspeak-pseudovox的衍生工作已延伸至多个前沿方向。其中包括面向神经语言模型的动物声学表征学习范式,如利用自监督预训练方法提取通用声学特征,进而推动跨物种对话系统的原型设计。此外,该数据集催生了针对低资源声学场景的微调策略研究,以及与GeoAI技术结合的时空声学分布建模,显著拓展了生物声学在环境科学中的工具边界。
以上内容由遇见数据集搜集并总结生成


