narrative_qa
收藏Hugging Face2024-12-13 更新2024-12-14 收录
下载链接:
https://huggingface.co/datasets/yzhuang/narrative_qa
下载链接
链接失效反馈官方服务:
资源简介:
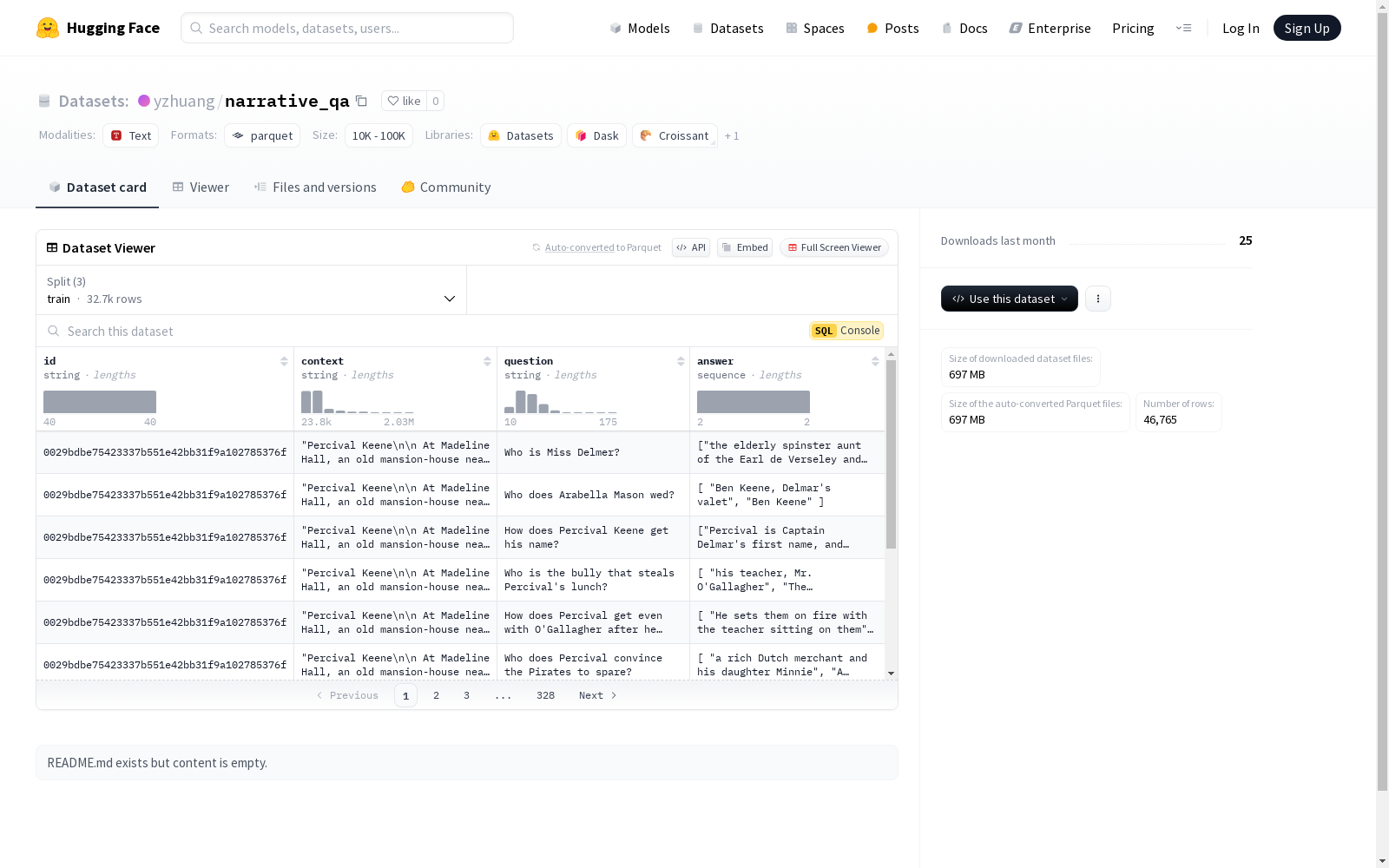
该数据集包含四个主要特征:id、context、question和answer。id是字符串类型,用于唯一标识每个样本;context是字符串类型,表示问题的背景信息;question是字符串类型,表示具体的问题;answer是字符串序列类型,表示问题的答案。数据集分为三个部分:训练集(train)、验证集(validation)和测试集(test),分别包含32747、3461和10557个样本。数据集的总下载大小为696511560字节,总数据集大小为16046403548字节。
This dataset contains four core features: id, context, question, and answer. The id is a string-type field used to uniquely identify each sample; context is a string-type field representing the background information corresponding to the question; question is a string-type field referring to the specific query; answer is a string-sequence field representing the answer to the corresponding question. The dataset is divided into three subsets: training set (train), validation set (validation), and test set (test), which contain 32747, 3461, and 10557 samples respectively. The total download size of the dataset is 696511560 bytes, and the total storage size of the complete dataset is 16046403548 bytes.
创建时间:
2024-12-13
原始信息汇总
数据集概述
数据集信息
-
特征:
- id: 数据类型为字符串。
- context: 数据类型为字符串。
- question: 数据类型为字符串。
- answer: 数据类型为字符串序列。
-
数据集划分:
- train: 包含32747个样本,数据大小为11367309106字节。
- validation: 包含3461个样本,数据大小为1192508224字节。
- test: 包含10557个样本,数据大小为3486586218字节。
-
下载大小: 696511560字节。
-
数据集总大小: 16046403548字节。
配置
- 配置名称: default
- 数据文件路径:
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
narrative_qa数据集的构建基于对叙事文本的深入分析,旨在捕捉复杂故事情节中的关键信息。该数据集通过从大量叙事文本中提取上下文信息,并结合精心设计的问题与答案对,形成了一个多层次的问答系统。构建过程中,研究者们不仅关注文本的表面信息,还深入挖掘了文本背后的隐含意义,确保数据集能够有效支持复杂叙事理解任务的研究。
特点
narrative_qa数据集的显著特点在于其丰富的上下文信息和多样的问答对。每个样本包含一个唯一的标识符、详细的上下文文本、精心设计的问题以及相应的答案序列。数据集分为训练、验证和测试三个部分,分别包含32747、3461和10557个样本,确保了数据集的广泛适用性和可靠性。此外,数据集的上下文文本长度和答案的多样性为研究者提供了丰富的实验材料,适用于多种自然语言处理任务。
使用方法
使用narrative_qa数据集时,研究者可以通过加载数据集的训练、验证和测试部分,分别进行模型训练、调优和评估。数据集的结构设计使得研究者能够轻松地提取上下文、问题和答案信息,进行各种自然语言处理任务的实验。例如,可以利用该数据集训练问答模型,评估模型在复杂叙事理解任务中的表现。此外,数据集的多样性和规模也为大规模预训练模型提供了理想的实验平台。
背景与挑战
背景概述
NarrativeQA数据集由AI2(Allen Institute for AI)于2018年发布,旨在推动长文本理解和问答系统的研究。该数据集的核心研究问题是如何从长篇叙事文本中提取关键信息并回答复杂问题。NarrativeQA包含了从书籍和电影剧本中提取的叙事文本,以及与之相关的问题和答案。这一数据集的发布对自然语言处理领域产生了深远影响,尤其是在长文本问答和机器阅读理解方面,为研究人员提供了一个具有挑战性的基准。
当前挑战
NarrativeQA数据集的主要挑战在于其处理长篇叙事文本的复杂性。首先,长文本的结构和内容多样性使得信息提取和理解变得困难。其次,问题和答案之间的关联性可能跨越多个段落,增加了模型捕捉上下文信息的难度。此外,构建过程中需要从大量书籍和电影剧本中提取高质量的叙事文本,并确保问题和答案的多样性和复杂性,这对数据标注和处理提出了高要求。
常用场景
经典使用场景
在自然语言处理领域,narrative_qa数据集的经典使用场景主要集中在问答系统的构建与评估。该数据集通过提供丰富的叙事文本及其对应的问答对,为研究者提供了一个理想的平台,用以训练和测试基于叙事理解的问答模型。这些模型能够从长篇故事或电影剧本中提取关键信息,并回答相关问题,从而在复杂文本理解任务中展现出卓越的性能。
解决学术问题
narrative_qa数据集解决了自然语言处理领域中关于长文本理解和复杂问答机制的学术研究问题。传统的问答数据集多集中于短文本或简单问答,而该数据集通过引入长篇叙事文本,填补了这一研究空白。其意义在于推动了问答系统在处理复杂、多层次文本时的能力,为研究者提供了一个评估和改进模型在长文本理解方面的基准。
衍生相关工作
narrative_qa数据集的发布催生了一系列相关研究工作,特别是在长文本理解和问答机制的优化方面。研究者们基于该数据集开发了多种先进的问答模型,如基于注意力机制的序列到序列模型和图神经网络模型,这些模型在处理复杂叙事文本时表现出色。此外,该数据集还激发了对多模态问答系统的研究,探索如何结合文本、图像和音频等多种信息源来提升问答系统的性能。
以上内容由遇见数据集搜集并总结生成


