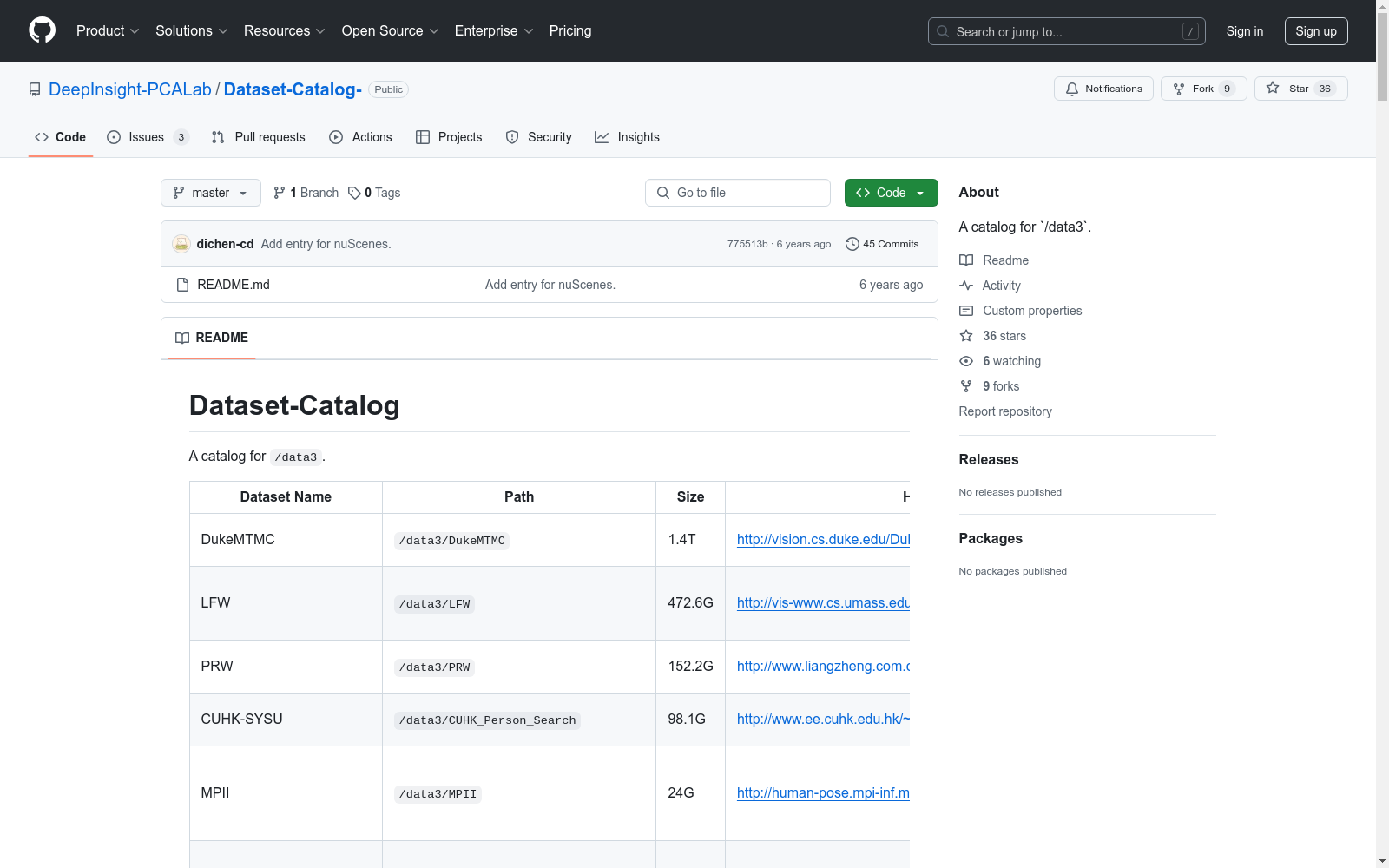
DukeMTMC, LFW, PRW, CUHK-SYSU, MPII, AIchallenge, Kitti, COCO, XJTU2017, DeepInsight, ImageNet/ILSVRC2015
收藏github2023-11-29 更新2024-05-31 收录
下载链接:
https://github.com/DeepInsight-PCALab/Dataset-Catalog-
下载链接
链接失效反馈官方服务:
资源简介:
DukeMTMC: 多轨迹多摄像头跟踪数据集。LFW: 人脸验证数据集,包括RGB图像、灰度图像和提取的特征。PRW: 人物搜索/重新识别数据集,包括图像、边界框和掩码。CUHK-SYSU: 人物搜索/重新识别数据集,包括图像、边界框和掩码。MPII: 2D姿态估计数据集,包括图像、处理过的掩码和关键点注释。AIchallenge: 2D多人姿态估计数据集,包括图像、边界框和关键点注释。Kitti: 自动驾驶数据集,包括立体和光流图像对、立体视觉里程计序列和3D对象注释。COCO: 检测/姿态估计/分割数据集。XJTU2017: 交通线检测、交通标志检测、车辆检测、车道保持监控、车辆距离估计数据集,包括图像、交通线、交通标志边界框和类型、车辆边界框、车辆距离。DeepInsight: 自建交通线检测数据集,包括图像、手工标注的交通线、一些图像和标签处理代码、几个预训练模型。ImageNet/ILSVRC2015: 大规模视觉识别挑战数据集。
DukeMTMC: A multi-trajectory multi-camera tracking dataset. LFW: A face verification dataset, including RGB images, grayscale images, and extracted features. PRW: A person search/re-identification dataset, including images, bounding boxes, and masks. CUHK-SYSU: A person search/re-identification dataset, including images, bounding boxes, and masks. MPII: A 2D pose estimation dataset, including images, processed masks, and keypoint annotations. AIchallenge: A 2D multi-person pose estimation dataset, including images, bounding boxes, and keypoint annotations. Kitti: An autonomous driving dataset, including stereo and optical flow image pairs, stereo visual odometry sequences, and 3D object annotations. COCO: A detection/pose estimation/segmentation dataset. XJTU2017: A dataset for traffic line detection, traffic sign detection, vehicle detection, lane keeping monitoring, and vehicle distance estimation, including images, traffic lines, traffic sign bounding boxes and types, vehicle bounding boxes, and vehicle distances. DeepInsight: A self-built traffic line detection dataset, including images, manually annotated traffic lines, some image and label processing code, and several pre-trained models. ImageNet/ILSVRC2015: A large-scale visual recognition challenge dataset.
创建时间:
2018-03-06
原始信息汇总
数据集概述
1. DukeMTMC
- 名称: DukeMTMC
- 路径:
/data3/DukeMTMC - 大小: 1.4T
- 关键词: Multi-Track Multi-Camera Tracking
- 其他信息: 包括RGB图像、灰度图像、提取的特征
2. LFW
- 名称: LFW
- 路径:
/data3/LFW - 大小: 472.6G
- 关键词: Face Verification
- 其他信息: 包括RGB图像、灰度图像、提取的特征
3. PRW
- 名称: PRW
- 路径:
/data3/PRW - 大小: 152.2G
- 关键词: Person Search/Re-identification
- 其他信息: 包括图像、边界框、掩码
4. CUHK-SYSU
- 名称: CUHK-SYSU
- 路径:
/data3/CUHK_Person_Search - 大小: 98.1G
- 关键词: Person Search/Re-identification
- 其他信息: 包括图像、边界框、掩码
5. MPII
- 名称: MPII
- 路径:
/data3/MPII - 大小: 24G
- 关键词: 2D Pose Estimation
- 其他信息: 包括图像、处理过的掩码和关键点注释
6. AIchallenge
- 名称: AIchallenge
- 路径:
/data3/AIchallenge - 大小: 29G
- 关键词: 2D Multi-Person Pose Estimation
- 其他信息: 包括图像、边界框和关键点注释
7. Kitti
- 名称: Kitti
- 路径:
/data3/Kitti - 大小: 357G
- 关键词: Autonomous Driving
- 其他信息: 包括立体和光流图像对、立体视觉里程序列和3D对象注释
8. COCO
- 名称: COCO
- 路径:
/data3/MSCOCO - 大小: 140G
- 关键词: Detection/ Pose Estimation/ Segmentation
9. XJTU2017
- 名称: XJTU2017
- 路径:
/data3/XJTU2017 - 大小: 25.9G
- 关键词: Traffic Line Detection; Traffic Sign Detection; Vehicle Detection; Lane Keeping Monitoring; Vehicle Distance Estimation
- 其他信息: 包括图像、交通线、交通标志边界框和类型、车辆边界框、车辆距离
10. DeepInsight
- 名称: DeepInsight
- 路径:
/data3/DeepInsight - 大小: 296G
- 关键词: Self-constructed dataset for traffic line detection (under development)
- 其他信息: 包括图像、手工标注的交通线、一些图像和标签处理的代码、几个预训练模型
11. ImageNet/ILSVRC2015
- 名称: ImageNet/ILSVRC2015
- 路径:
/data3/ImageNet/ILSVRC2015 - 大小: 179G
- 关键词: Object Detection; Object Tracking
- 其他信息: 包括竞赛数据:对象检测和视频对象检测
12. ImageNet/ILSVRC2017
- 名称: ImageNet/ILSVRC2017
- 路径:
/data3/Imagenet/ILSVRC2017 - 大小: 359G
- 关键词: Object detection from video
- 其他信息: 包括Imagenet 2017挑战的所有数据,由DET和VID子集组成
13. ALOV
- 名称: ALOV
- 路径:
/data3/alov - 大小: 11G
- 关键词: Object Tracking
- 其他信息: 包括注释和图像
14. Cityscapes
- 名称: Cityscapes
- 路径:
/data3/Cityscapes - 大小: 31G
- 关键词: Segmentation; Detection
15. KAIST_Infrared_Pedestrain
- 名称: KAIST_Infrared_Pedestrain
- 路径:
/data3/KAIST_Infrared_Pedestrain - 大小: 36G
- 关键词: Pedestrian Detection
- 其他信息: 包括RGB图像、红外图像和标记的边界框
16. RESIDE
- 名称: RESIDE
- 路径:
/data3/RESIDE - 大小: 98G
- 关键词: Single Image Dehazing
- 其他信息: 包括RGB对(雾&清洁)、灰度图像(传输图)
17. pku_Rain
- 名称: pku_Rain
- 路径:
/data3/pku_Rain/rainALL_ALL - 大小: 8.6G
- 关键词: Deraining, rain removal from a single image
- 其他信息: 包括RGB对(雨&清洁)、标记的雨条
18. Snow100K
- 名称: Snow100K
- 路径:
/data3/Snow - 大小: 16G
- 关键词: Desnow/ Snow Removal
- 其他信息: 包括RGB对(雪&清洁)、标记的雪位置
19. NYU depth v2
- 名称: NYU depth v2
- 路径:
/data3/NYU_depth - 大小: 428G
- 关键词: Depth Estimation from RGB Image
20. PASCAL VOC
- 名称: PASCAL VOC
- 路径:
/data3/PASCAL/VOCdevkit - 大小: 3G
- 关键词: Object Detection; Segmentation
- 其他信息: 包括VOC2007和VOC2012
21. CIFAR 10
- 名称: CIFAR 10
- 路径:
/data3/cifar10 - 大小: 236M
- 关键词: Object Recognition
22. CIFAR 100
- 名称: CIFAR 100
- 路径:
/data3/cifar100 - 大小: 939M
- 关键词: Object Recognition
23. SVHN
- 名称: SVHN
- 路径:
/data3/SVHN - 大小: 2.5G
- 关键词: Number Recognition
24. HMDB-51
- 名称: HMDB-51
- 路径:
/data3/hmdb51 - 大小: 2.1G
- 关键词: Human Motion Recognition
25. DAVIS 17
- 名称: DAVIS 17
- 路径:
/data3/DAVIS17 - 大小: 12G
- 关键词: Video Segmentation
26. DAVIS 16
- 名称: DAVIS 16
- 路径:
/data3/DAVIS-data-origin - 大小: 7.2G
- 关键词: Video Segmentation
27. Tsinghua-Tencent 100K
- 名称: Tsinghua-Tencent 100K
- 路径:
/data3/Tsinghua_Tencent_100K - 大小: 24.5G
- 关键词: Traffic Sign Detection
28. Traffic Light Datasets
- 名称: Traffic Light Datasets
- 路径:
/data3/TrafficLight - 大小: 36G
- 关键词: Traffic Sign Detection
29. SUN RGBD
- 名称: SUN RGBD
- 路径:
/data3/SUNRGBD - 大小: 7.39G
- 关键词: Depth Estimation; RGBD object classification
30. VOT
- 名称: VOT
- 路径:
/data3/VOT - 大小: 1.9G
- 关键词: Video Object Tracking
- 其他信息: 包括vot2014和vot 2015
31. Charades
- 名称: Charades
- 路径:
/data3/Charades - 大小: 396G
- 关键词: Video Recognition & Video Caption
- 其他信息: 包括视频、原始大小的流以及缩放到480p的流,以及由帧和光流计算的两流特征,评估代码也提供
32. MOT
- 名称: MOT
- 路径:
/data3/MOT - 大小: 1.9G
- 关键词: Multiple-Object Tracking
- 其他信息: 包括mot数据集的训练和测试数据,如果需要,还包括由flownet2.0提取的光流
33. MPI-Sintel
- 名称: MPI-Sintel
- 路径:
/data3/MPI_Sintel - 大小: 12G
- 关键词: Optical flow estimation
- 其他信息: 包括MPI-Sintel数据集的所有训练和测试数据,特别是用于评估光流算法性能
34. FlyingThings
- 名称: FlyingThings
- 路径:
/data3/FlyingThings - 大小: 1.3T
- 关键词: Optical flow estimation
- 其他信息: 包括训练和测试数据以及转换为tensorflow tfrecords文件的数据,其中光流仅从左视图转换,顺序为into_future
35. FlyingChairs
- 名称: FlyingChairs
- 路径:
/data3/FlyingChairs/FlyingChairs - 大小: 1.1T
- 关键词: Optical flow estimation
- 其他信息: 包括训练和测试数据以及转换为tensorflow tfrecords文件的数据
36. Broden
- 名称: Broden
- 路径:
/data3/Broden - 大小: 1G
- 关键词: CNN Interpretbility; Network Dissection
- 其他信息: 用于解释CNN中解耦表示的数据集
37. CASIA WebFace
- 名称: CASIA WebFace
- 路径:
/data3/CASIA_WebFace - 大小: 8.9G
- 关键词: Face Recognition/Verification
38. Market1501
- 名称: Market1501
- 路径:
/data3/Market1501 - 大小: 2.6G
- 关键词: Person Re-identification
39. MARS
- 名称: MARS
- 路径:
/data3/MARS - 大小: 19G
- 关键词: Video-based Person Re-identification
40. CUHK03
- 名称: CUHK03
- 路径:
/data3/CUHK03 - 大小: 8.7G
- 关键词: Person Re-identification
41. GraspingRectangleDataset
- 名称: GraspingRectangleDataset
- 路径:
/data3/GraspingRectangle/ - 大小: 10G
- 关键词: RGBD detection
- 其他信息: 用于检测机器人抓取的数据集
42. Visual Genome
- 名称: Visual Genome
- 路径:
/data3/Visual_Genome - 大小: 15G
- 关键词: Visual Relationship Detection
- 其他信息: Visual Genome是一个数据集,一个知识库,一个持续努力连接结构化图像概念到语言
43. Human 3.6M
- 名称: Human 3.6M
- 路径:
/data3/Human36M - 大小: 32G
- 关键词: RGBD Human Pose Estimation
- 其他信息: 用于从RGBD数据检测人体关键点的数据集
44. UCF-101
- 名称: UCF-101
- 路径:
/data3/UCF-all-in-one - 大小: 94G
- 关键词: Video analysis
- 其他信息: 包括UCF-101(原始视频)、ucf_frame(视频帧)和ucf_transed(光流)
45. DiDi Self-Driving Dataset
- 名称: DiDi Self-Driving Dataset
- 路径:
/data3/DiDi - 大小: ~500G
- 关键词: 3D Object Detection with multiple sensors
46. DOTA
- 名称: DOTA
- 路径:
/data3/DOTA - 大小: 20G
- 关键词: Aerial Images; Small Object Detection
- 其他信息: 用于航空图像中的小对象检测的大型数据集
47. PoseTrack
- 名称: PoseTrack
- 路径:
/data3/Posetrack - 大小: 33G
- 关键词: Pose estimation; Tracking
- 其他信息: PoseTrack是一个用于视频中人体姿态估计和跟踪的大型基准
48. WIDER Person Search
- 名称: WIDER Person Search
- 路径:
/data3/WIDER_Person_Search - 大小: 12G
- 关键词: Person Search; Person Detection; Re-identification
- 其他信息: WIDER Face & Pedestrain Challenge - Track 3: Person Search
49. VisDrone
- 名称: VisDrone
- 路径:
/data3/VisDrone - 大小: 14G
- 关键词: Bird-view detection; Drone survallence detection
- 其他信息: 包括图像和标签
50. SmartCity
- 名称: SmartCity
- 路径:
/data3/smartcity - 大小: 28G
- 关键词: Action Recognition
51. RGBT234
- 名称: RGBT234
- 路径:
/data3/RGBT234 - 大小: 7.76G
- 关键词: RGB-T tracking, Thermal image
- 其他信息: 包括RGB图像和热图像
52. TB-100
- 名称: TB-100
- 路径:
/data3/TB-100 - 大小: 2.76G
- 关键词: Visual Tracker
- 其他信息: 包括RGB图像和地面实况
53. Youtube-8M
- 名称: Youtube-8M
- 路径:
/data3/Youtube-8M - 大小: 1.8T
- 关键词:
54. CUB-200-2011
- 名称: CUB-200-2011
- 路径:
/data3/CUB_200_2011 - 大小: 1.1G
- 关键词: Bird Classification
55. Online Product
- 名称: Online Product
- 路径:
/data3/Online_Product - 大小: 2.9G
- 关键词: Product Retrieval
56. Automated Driving 3D Point Cloud Segmentation
- 名称: Automated Driving 3D Point Cloud Segmentation
- 路径:
/data3/3D_Point_Cloud_Segmentation - 大小: 86.5G
- 关键词: Dataset for automated driving 3D point cloud segmentation
57. LaSOT
- 名称: LaSOT
- 路径:
/data3/LaSOT - 大小: 227G
- 关键词: Large-scale Single Object Tracking (LaSOT)
- 其他信息: 包括图像和标签
58. AIChallenger Caption
- 名称: AIChallenger Caption
- 路径:
/data3/ai_challenger_caption - 大小: 21.7G
- 关键词:
59. UCF_Crime
- 名称: UCF_Crime
- 路径:
/data3/UCF_Crime - 大小: 208G
- 关键词: a dataset for anomaly detection, including initial video, generated images and optical flows
60. KTH
- 名称: KTH
- 路径:
/data3/KTH - 大小: 1G
- 关键词: The current video database containing six types of human actions (walking, jogging, running, boxing, hand waving and hand clapping).
61. AirbusShipDetection
- 名称: AirbusShipDetection
- 路径:
- 大小:
- 关键词:
- 其他信息:
搜集汇总
数据集介绍
构建方式
ILSVRC2015数据集作为ImageNet大规模视觉识别挑战赛的重要组成部分,其构建过程依托于ImageNet数据库,涵盖了超过1000个类别的图像数据。数据集的构建采用了严格的标注流程,每张图像均经过人工标注,确保类别标签的准确性。此外,数据集还包含了视频对象检测(VID)任务的数据,通过从视频序列中提取帧并进行标注,进一步扩展了其应用范围。
特点
ILSVRC2015数据集以其大规模和高多样性著称,涵盖了自然场景中的多种对象类别,为计算机视觉任务提供了丰富的训练和测试数据。其特点在于不仅包含静态图像,还引入了视频对象检测任务,使得数据集能够支持更复杂的视觉分析任务。数据集的标注信息包括对象类别、边界框以及视频帧的时间序列信息,为多任务学习提供了坚实的基础。
使用方法
ILSVRC2015数据集广泛应用于对象检测、对象跟踪等计算机视觉任务的研究与开发。研究人员可通过下载数据集并加载其标注信息,使用深度学习框架进行模型训练与评估。对于视频对象检测任务,数据集提供了帧序列及其对应的标注信息,支持时间序列建模与多帧联合分析。此外,数据集的标准化格式便于与其他视觉数据集进行联合使用,以提升模型的泛化能力。
背景与挑战
背景概述
ILSVRC2015数据集是ImageNet大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)的一部分,由斯坦福大学、普林斯顿大学等机构的研究人员共同创建。该数据集于2015年发布,旨在推动计算机视觉领域的发展,特别是在目标检测和目标跟踪任务上。ILSVRC2015包含了海量的图像和视频数据,涵盖了1000个类别的物体,为深度学习模型提供了丰富的训练和测试资源。该数据集在推动卷积神经网络(CNN)等技术的进步中发挥了关键作用,成为计算机视觉领域的基准数据集之一。
当前挑战
ILSVRC2015数据集在解决目标检测和目标跟踪问题时面临多重挑战。首先,数据集中包含的物体类别繁多且场景复杂,模型需要具备强大的泛化能力以应对多样化的视觉环境。其次,目标跟踪任务要求模型在视频序列中持续准确地定位目标,这对算法的鲁棒性和实时性提出了极高要求。在数据集构建过程中,研究人员还需处理海量数据的标注问题,确保每一帧图像中的目标边界框和类别标签的准确性,这对标注团队的工作量和精度提出了巨大挑战。此外,数据集的规模庞大,存储和处理这些数据需要高性能的计算资源,进一步增加了研究门槛。
常用场景
经典使用场景
ILSVRC2015数据集在计算机视觉领域中被广泛用于对象检测和视频对象检测任务。该数据集包含了大量的标注图像和视频,为研究者提供了一个标准化的平台,用于开发和评估新的算法。特别是在深度学习模型的训练和验证过程中,ILSVRC2015数据集因其丰富的类别和高质量的标注而成为首选。
实际应用
在实际应用中,ILSVRC2015数据集被广泛用于自动驾驶、视频监控和智能安防系统。通过利用该数据集训练的模型,能够实现对交通标志、行人、车辆等对象的实时检测和跟踪,从而提升系统的安全性和智能化水平。此外,该数据集还在医疗影像分析、无人机监控等领域展现了其重要价值。
衍生相关工作
ILSVRC2015数据集催生了许多经典的研究工作,特别是在深度学习和卷积神经网络(CNN)领域。基于该数据集的研究成果包括Faster R-CNN、YOLO和SSD等著名的对象检测算法。这些算法不仅在学术界引起了广泛关注,还在工业界得到了广泛应用,推动了计算机视觉技术的快速发展。
以上内容由遇见数据集搜集并总结生成


