ECJK-parallel-corpus
收藏github2024-05-20 更新2024-05-31 收录
下载链接:
https://github.com/hyunwoongko/ECJK-parallel-corpus
下载链接
链接失效反馈官方服务:
资源简介:
包含多种多语言平行语料库,用于自然语言处理任务。
This dataset encompasses a variety of multilingual parallel corpora, designed for natural language processing tasks.
创建时间:
2020-11-27
原始信息汇总
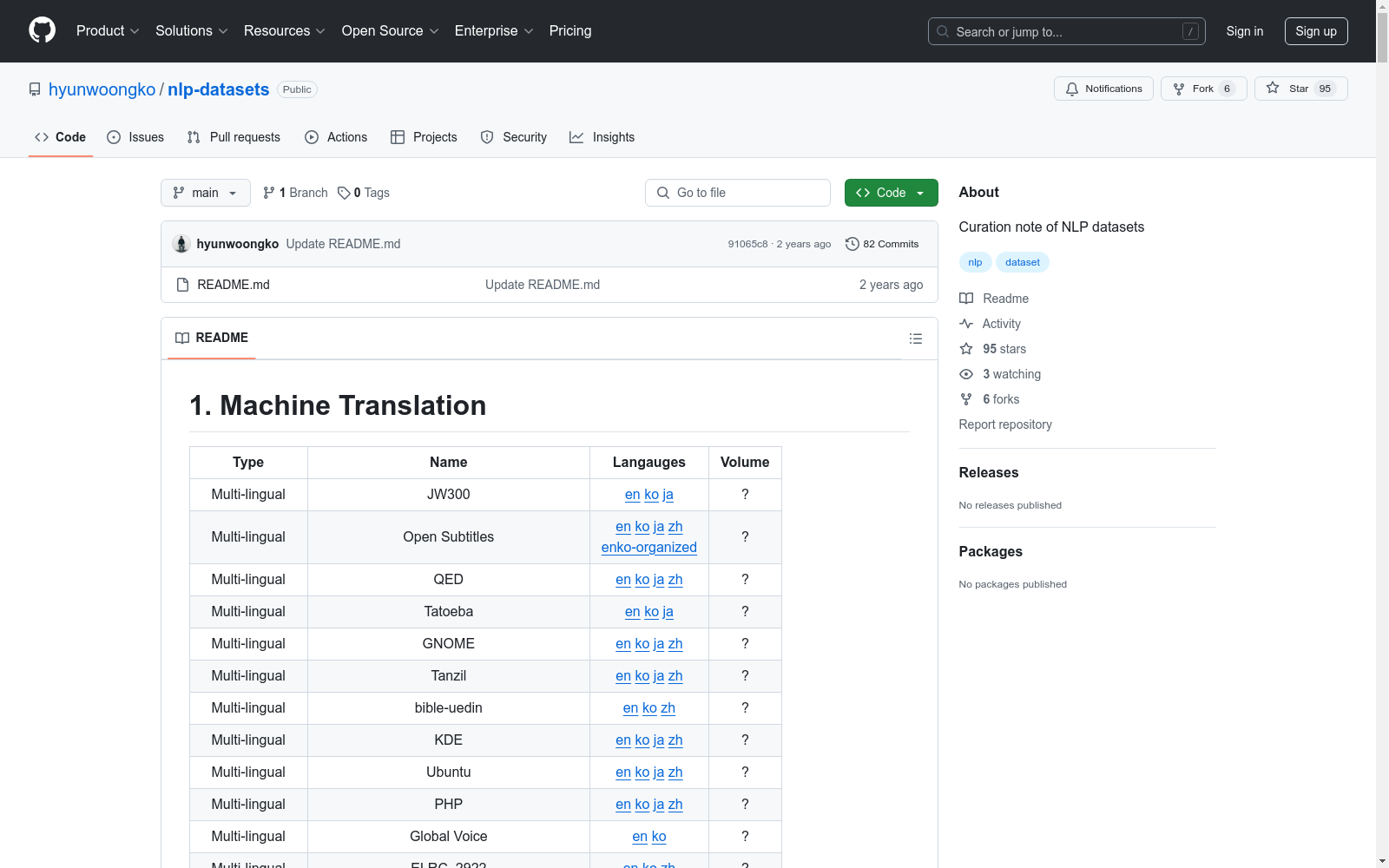
机器翻译数据集
| Type | Name | Languages | Volume |
|---|---|---|---|
| Multi-lingual | JW300 | en, ko, ja | ? |
| Multi-lingual | Open Subtitles | en, ko, ja, zh, enko-organized | ? |
| Multi-lingual | QED | en, ko, ja, zh | ? |
| Multi-lingual | Tatoeba | en, ko, ja | ? |
| Multi-lingual | GNOME | en, ko, ja, zh | ? |
| Multi-lingual | Tanzil | en, ko, ja, zh | ? |
| Multi-lingual | bible-uedin | en, ko, zh | ? |
| Multi-lingual | KDE | en, ko, ja, zh | ? |
| Multi-lingual | Ubuntu | en, ko, ja, zh | ? |
| Multi-lingual | PHP | en, ko, ja, zh | ? |
| Multi-lingual | Global Voice | en, ko | ? |
| Multi-lingual | ELRC_2922 | en, ko, zh | ? |
| Multi-lingual | Ted Multilingual Corpus | ko, ja, zh | 0.4M |
| Multi-lingual | Multilingual TED Talks | 10 languages | ? |
| Multi-lingual | Twitter corpora (small) | en, ko, ja | ? |
| Multi-lingual | Asian Language Treebank | en, ko, zh, ja | 20k |
| Multi-lingual | 1000 parallel sentences | en, ko, ja | 1k |
| Multi-lingual | TUFS Asian Language Parallel Corpus | en, ko, ja | 1k |
| Multi-lingual | NICT QE/APE Dataset | en, ko, ja, zh | 10k |
| Multi-lingual | Basic Expressions | en, ja, zh | 5k |
| Multi-lingual | Kaist Parallel Dataset | en, ko, zh | 60k |
| Bi-lingual | Korean Parallel corpora | en ↔ ko | 10k |
| Bi-lingual | AIHub translation dataset | en ↔ ko | 1.6M |
| Bi-lingual | AIHub Parallel corpus of specialized fields | en ↔ ko | 1.5M |
| Bi-lingual | Ulsan University parallel dataset | en ↔ ko | 1.25M |
| Bi-lingual | UMCorpus | en ↔ zh | ? |
| Bi-lingual | JParaCrawl | en ↔ ja | 10M |
| Bi-lingual | Stanford | en ↔ ja | 2.8M |
| Bi-lingual | small_parallel_enja | en ↔ ja | 50K |
| Bi-lingual | Kyoto Free Translation Task | en ↔ ja | 1k |
| Bi-lingual | Japanese-English Legal Parallel Corpus | en ↔ ja | 0.26M |
| Bi-lingual | UNCorpus | en ↔ zh | 15M |
| Bi-lingual | MultiUN | en ↔ zh | ? |
| Bi-lingual | Sina Weibo | ko ↔ zh | 41k |
| Bi-lingual | JParaCrawl | ja ↔ zh | 83k |
| Other Materials | CS224N Subtitles | en ↔ ko | 5k |
| Other Materials | CS231N Subtitles | en ↔ ko | ? |
| Other Materials | KaiserreichKoreanTranslation | en ↔ ko | ? |
| Other Materials | TheNewOrderKoreanTranslation | en ↔ ko | ? |
| Other Materials | EYWOR-Korean-translation | en ↔ ko | ? |
| Other Materials | Red-Flood-Korean-Translation | en ↔ ko | ? |
问题回答数据集
| No | Name | Description |
|---|---|---|
| 1 | KorQuAD 1.0 | 代表性的韩语QA数据集,遵循与SQuAD相同的格式,数据集规模约为6万。 |
| 2 | KorQuAD 2.0 | 代表性的韩语QA数据集,包含HTML标签、表格等复杂输入,以及解决多跳等多样问题的数据集。 |
| 3 | AIHub-MRC | 韩语QA数据集,规模约为45万。 |
| 4 | AIHub-Commonsense | 韩语QA数据集,规模约为10万。 |
| 5 | ARC | 多选科学问题数据集,分为挑战集和简单集。 |
| 6 | Story Cloze Test | 故事理解数据集,提供四句话的故事和两个可能的结局。 |
| 7 | SearchQA | 通用问题回答的全流程数据集,包含问题/答案/元数据。 |
| 8 | SQuAD2 | 开放域QA数据集,可从给定段落中找到答案,答案可能不存在。 |
| 9 | SQuAD | 从维基百科文章中收集的QA对集合,问题和答案由人类生成。 |
| 10 | GLUE | 包含9个NLU任务的数据集集合,包括单句任务、复述任务和NLI任务。 |
| 11 | MS MARCO | 基于Bing问题和人工编写的答案的数据集,现已扩展到包括问题生成、段落排序等多个任务。 |
| 12 | TriviaQA | 基于维基百科的文本基础QA数据集,问题可能需要从多个段落中收集信息。 |
| 13 | CoQA | 针对给定段落的问答及证据数据集,包含问题、答案和证据。 |
| 14 | SuperGLUE | 类似于GLUE的8个语言理解任务数据集,但更难且覆盖更多任务。 |
| 15 | QuAC | 包含14K众包QA对话和98K QA对的数据集,模拟学生和教师之间的交互式对话。 |
跨语言/多语言数据集
| No | Name | Description |
|---|---|---|
| 1 | DuReader | 中文开放域MRC数据集。 |
| 2 | C3 | 中文多选题数据集。 |
| 3 | MLQA | 包含英语、阿拉伯语、德语、西班牙语、印地语、越南语、简体中文的QA数据集,平均每种语言有4种不同语言的平行数据。 |
| 4 | TyDi QA | 包含11种语言的QA数据集。 |
| 5 | DRCD | 开放域阅读理解数据集,中文和英语平行。 |
| 6 | XQuAD | 包含西班牙语、德语、希腊语、俄语、土耳其语、阿拉伯语、越南语、泰语、中文、印地语的QA数据集,包含段落、答案跨度和问题。 |
| 7 | XQA | 包含英语、中文、法语、德语、波兰语、葡萄牙语、俄语、泰米尔语、乌克兰语的QA数据集。 |
| 8 | MKQA | 包含26种语言的QA数据集,包括英语、阿拉伯语、丹麦语、德语、西班牙语、芬兰语、法语、希伯来语、匈牙利语、意大利语、日语、安科莱语、韩语、马来西亚语、荷兰语、挪威语、波兰语、葡萄牙语、俄语、瑞典语、泰语、土耳其语、越南语、中文、香港中文、简体中文。 |
| 9 | XTREME | 包含12种语言和9个任务的多语言迁移学习数据集。 |
| 10 | KLEJ | 波兰语自然语言理解任务数据集。 |
| 11 | RELX | 包含英语、法语、德语、西班牙语、土耳其语的关系分类数据集。 |
| 12 | XOR-TYDI QA | 基于TyDi QA问题生成的数据集,覆盖的语言较少。 |
搜集汇总
数据集介绍
构建方式
ECJK-parallel-corpus数据集通过整合多个多语言平行语料库构建而成,涵盖了英语、中文、日语和韩语四种语言。这些语料库包括了从不同领域和来源收集的文本,如电影字幕、新闻文章、宗教文本等。数据集的构建过程中,采用了多种公开可用的平行语料库,如JW300、Open Subtitles、QED等,确保了数据的多源性和多样性。
特点
该数据集的主要特点在于其多语言性和广泛的应用领域。它不仅包含了多种语言的平行文本,还涵盖了从日常对话到专业领域的多样化内容,如电影字幕、新闻报道、宗教文本等。此外,数据集的规模较大,能够支持多种自然语言处理任务,如机器翻译、文本对齐和跨语言信息检索等。
使用方法
ECJK-parallel-corpus数据集可用于多种自然语言处理任务,主要包括机器翻译、文本对齐和跨语言信息检索。用户可以通过下载相应的语料库文件,进行数据预处理和模型训练。对于机器翻译任务,用户可以将数据集划分为训练集、验证集和测试集,使用神经网络模型进行训练和评估。此外,该数据集还可用于研究多语言文本的语义对齐和跨语言知识迁移。
背景与挑战
背景概述
ECJK-parallel-corpus 数据集是一个多语言平行语料库,涵盖了英语、中文、日语和韩语四种语言。该数据集的主要目的是支持机器翻译和跨语言自然语言处理任务的研究。数据集的构建基于多个公开的平行语料库,如Open Subtitles、QED、Tatoeba等,这些语料库提供了丰富的多语言文本对,适用于训练和评估机器翻译模型。ECJK-parallel-corpus 的创建旨在为研究人员提供一个高质量的多语言资源,以推动跨语言信息处理的进展。
当前挑战
ECJK-parallel-corpus 数据集在构建过程中面临多个挑战。首先,多语言平行语料库的构建需要处理不同语言之间的语法、词汇和文化差异,这增加了数据对齐和处理的复杂性。其次,数据集的规模和多样性也是一个挑战,尽管包含多个语料库,但部分语料库的规模和质量参差不齐,可能影响模型的训练效果。此外,数据集的标注和清洗过程也需要耗费大量人力和时间,以确保数据的质量和一致性。最后,跨语言翻译任务本身具有高度复杂性,模型需要在不同语言之间进行有效的语义映射,这对模型的设计和训练提出了更高的要求。
常用场景
经典使用场景
ECJK-parallel-corpus数据集在机器翻译领域中具有广泛的应用,尤其是在多语言翻译任务中。该数据集包含了多种语言(如英语、韩语、日语、中文)之间的平行语料,为研究人员提供了丰富的资源来训练和评估跨语言翻译模型。通过利用这些平行语料,研究人员可以构建高效的翻译系统,提升不同语言之间的互译质量。
实际应用
在实际应用中,ECJK-parallel-corpus数据集被广泛用于构建多语言翻译工具和系统。例如,在跨国企业的全球化运营中,该数据集支持的语言对可以帮助企业快速实现多语言文档的翻译,提升沟通效率。此外,在教育、旅游和文化交流等领域,该数据集也为语言学习者和跨文化交流者提供了强大的翻译支持。
衍生相关工作
基于ECJK-parallel-corpus数据集,许多研究工作得以展开,尤其是在多语言翻译模型的优化和跨语言理解任务中。例如,研究人员利用该数据集开发了更高效的神经机器翻译模型,提升了翻译的准确性和流畅性。此外,该数据集还被用于多语言问答系统、跨语言信息检索等领域的研究,推动了多语言自然语言处理技术的整体发展。
以上内容由遇见数据集搜集并总结生成


