C4-zh
收藏Hugging Face2025-03-29 更新2025-03-30 收录
下载链接:
https://huggingface.co/datasets/Geralt-Targaryen/C4-zh
下载链接
链接失效反馈官方服务:
资源简介:
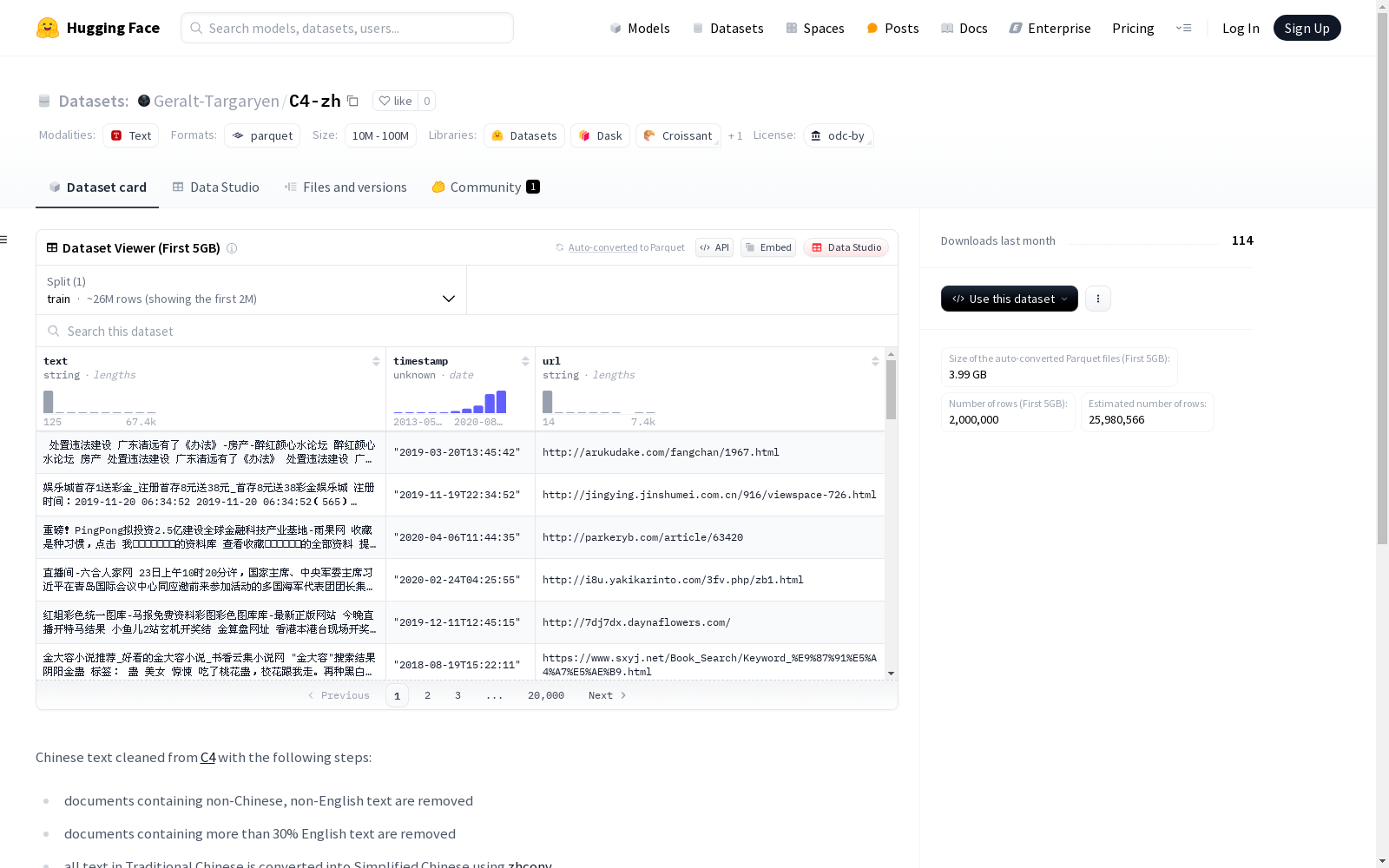
这是一个从C4数据集中清洗出的仅含中文文本的数据集,共包含32485463个样本,转换为Parquet格式后的文件大小为61G。此外,还有一个经过模型筛选的版本,包含16751363个样本,文件大小为33G。数据集中还包含了398K个中文样本和250K个英文样本的语言质量标注信息,这些信息用于训练一个XLM-RoBERT-large分类器来过滤文档。
This is a Chinese-only text dataset cleaned from the C4 corpus, containing a total of 32,485,463 samples. The file size in Parquet format is 61 GB. Additionally, there is a model-filtered version with 16,751,363 samples and a file size of 33 GB. The dataset also includes language quality annotation information for 398K Chinese samples and 250K English samples, which is used to train an XLM-RoBERTa-large classifier for document filtering.
创建时间:
2025-03-24
搜集汇总
数据集介绍
构建方式
在构建C4-zh数据集的过程中,研究团队采用了多阶段精细化的处理流程。基于原始的C4多语言语料库,通过严格的文本筛选机制保留中文内容,包括剔除含非中英文字符的文档,以及过滤英文占比超过30%的文本。针对中文特性,使用zhconv工具将繁体中文统一转换为简体中文,并运用启发式规则去除低质量文本如广告和模板内容,最终形成包含3248万样本的纯净语料库。针对模型过滤版本,额外采用Qwen2.5-32B-Instruct模型进行语言质量评分,并训练XLM-RoBERT-large分类器实施二次过滤。
使用方法
使用该数据集时,研究者可根据需求选择基础版本或模型过滤版本。基础版本适用于需要海量中文文本的场景,如预训练语言模型;过滤版本则更适合对文本质量要求较高的任务。数据集采用parquet格式存储,支持高效读取和处理。语言质量评分可用于构建分层训练集,或作为模型训练的辅助特征。值得注意的是,使用过滤版本时应充分理解评分模型的筛选标准,必要时可结合人工评估验证数据质量。
背景与挑战
背景概述
C4-zh数据集源于AllenAI团队发布的C4(Colossal Clean Crawled Corpus)项目,旨在为中文自然语言处理任务提供高质量的文本资源。该数据集通过严格的清洗流程,从原始C4数据中筛选出纯净的中文文本,并转换为简体中文格式,以满足中文NLP研究的需求。其构建过程体现了对语言纯度和文本质量的严格要求,为机器翻译、文本生成等任务提供了重要支持。C4-zh的发布丰富了中文语料库的多样性,推动了中文信息处理技术的发展。
当前挑战
C4-zh数据集在构建过程中面临多重挑战。从领域问题来看,中文文本的复杂性,包括繁简体转换、中英混合文本的识别与过滤,对数据清洗提出了较高要求。在构建过程中,如何准确区分低质量文本(如广告、模板内容)并保持数据的多样性,是一个技术难点。此外,尽管采用了基于Qwen2.5-32B-Instruct和XLM-RoBERT-large的质量评估模型,但自动评分系统的准确性和一致性仍需进一步验证,以确保筛选后的数据真正符合高质量标准。
常用场景
经典使用场景
在自然语言处理领域,C4-zh数据集作为大规模中文文本语料库,为语言模型的预训练提供了丰富的资源。其经过严格清洗和过滤的文本质量,使得研究者能够构建更精准的中文语言理解模型。特别是在机器翻译、文本生成等任务中,该数据集展现了出色的基础支撑作用。
解决学术问题
C4-zh数据集有效解决了中文自然语言处理研究中数据稀缺和质量参差不齐的难题。通过去除低质量文本和标准化简繁转换,该数据集为语言模型的训练提供了纯净的语料环境。其在语言质量评估方面的创新标注方法,进一步推动了文本过滤技术的发展。
实际应用
在实际应用中,C4-zh数据集支撑了各类中文智能系统的开发。搜索引擎优化、智能客服对话系统、以及内容推荐算法都受益于该数据集提供的海量高质量文本。企业利用这些预训练模型,显著提升了中文信息处理的准确性和效率。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模预训练语料库的质量对模型性能具有决定性影响。C4-zh数据集作为中文文本处理的重要资源,其最新研究方向聚焦于多语言混合文本的精细化过滤与质量评估。近期研究通过引入Qwen2.5-32B-Instruct等先进大语言模型进行文本质量标注,结合XLM-RoBERT-large分类器构建自动化评分体系,显著提升了语料纯净度。该技术路径为跨语言预训练、低资源语言建模等前沿课题提供了高质量的基准数据,尤其在处理简繁中文转换、广告文本识别等实际场景中展现出重要应用价值。当前学术界正基于此类增强型语料库,探索多模态预训练与语言模型微调的新范式。
以上内容由遇见数据集搜集并总结生成


