DeepSeek-R1-20k
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://huggingface.co/datasets/jasonrqh/DeepSeek-R1-20k
下载链接
链接失效反馈官方服务:
资源简介:
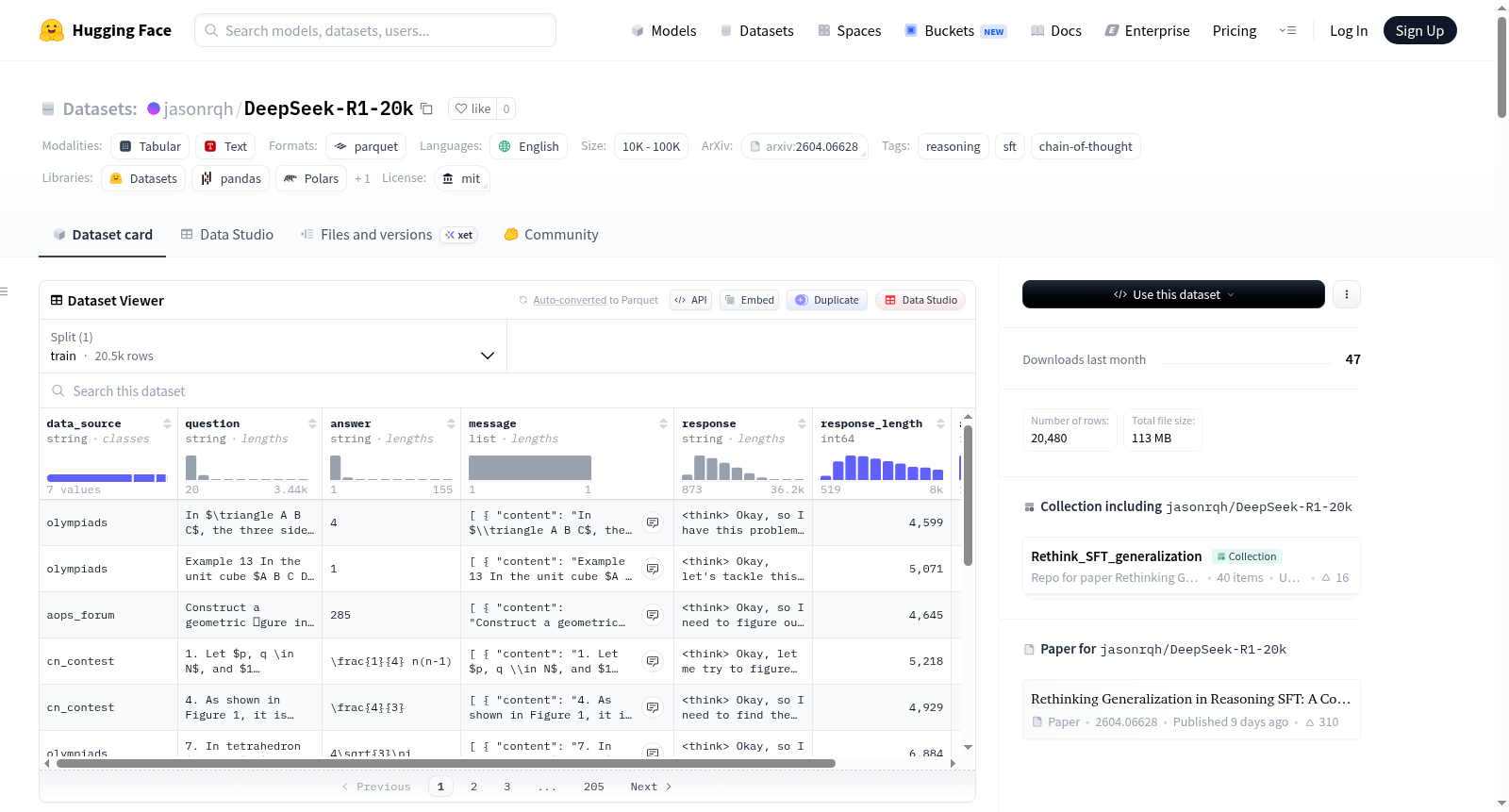
该数据集与论文《Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability》相关,旨在研究大型语言模型(LLMs)在推理监督微调(SFT)中的跨领域泛化能力。数据集包含多种类型的推理数据,如带有长链思维(CoT)的数学推理数据(Math-CoT-20k)、去除CoT的数学数据(Math-NoCoT-20k)、用于程序性转移分析的倒计时算术游戏数据(Countdown-CoT-20k)、以及来自NuminaMath-1.5的无CoT数学数据(NuminaMath-20k)和来自LUFFY数据集的DeepSeek-R1长CoT响应数据(DeepSeek-R1-20k)。每个数据集包含20,480个样本,适用于研究优化动态、数据质量与结构、模型能力以及不对称泛化等问题。
创建时间:
2026-04-06
搜集汇总
数据集介绍
构建方式
在推理能力微调的研究背景下,DeepSeek-R1-20k数据集作为一项关键资源应运而生。该数据集源自LUFFY数据集,其构建过程聚焦于利用DeepSeek-R1模型对相同的数学推理查询生成经过验证的长链思维轨迹。具体而言,研究人员从基础查询集合出发,通过先进的推理模型产生详细的逐步解答,并对这些解答进行严谨的验证,确保思维链的逻辑正确性与完整性。最终形成了包含20,480条高质量样本的数据集,旨在为研究长链思维数据对模型跨领域泛化能力的影响提供标准化、可复现的实验材料。
特点
作为探究推理微调泛化机制的重要载体,DeepSeek-R1-20k数据集展现出若干鲜明特征。其核心在于提供了由高性能推理模型DeepSeek-R1生成的、经过严格验证的长链思维轨迹,这些轨迹蕴含着丰富的程序性推理模式。数据集规模统一为20k,便于在不同实验设置下进行公平比较。尤为关键的是,该数据集与Math-CoT-20k等姊妹数据集共享相同的查询基础,使得研究者能够精确隔离并分析不同教师模型或数据质量对微调效果的影响,为理解数据源特性与模型泛化性能之间的因果关系提供了纯净的实验环境。
使用方法
在大型语言模型的推理微调研究中,DeepSeek-R1-20k数据集主要用于系统性地评估数据源对模型泛化能力的作用。研究者通常将其作为监督微调的训练数据,应用于不同规模与架构的基础模型,以探究基于DeepSeek-R1生成的长链思维数据所诱导的泛化模式。通过与Math-CoT-20k等数据集的对比实验,可以剖析不同教师模型生成的数据质量如何影响模型对回溯等可迁移推理模式的内化程度。此外,该数据集也适用于研究优化动态、数据重复暴露效应以及模型能力与数据质量之间的交互作用,为构建更鲁棒的推理微调策略提供实证依据。
背景与挑战
背景概述
在大型语言模型推理能力微调的研究脉络中,跨领域泛化能力是衡量模型能否习得普适性思维模式的关键指标。DeepSeek-R1-20k数据集作为一项系统性研究的产物,诞生于2026年,由任启涵等研究人员在论文《Rethinking Generalization in Reasoning SFT》中构建并发布。该数据集旨在探究推理导向的监督微调中,长链思维数据对模型跨领域泛化能力的影响机制。其核心研究问题聚焦于优化动态、数据质量与模型能力三者如何共同塑造泛化行为,为理解大语言模型在复杂推理任务上的学习本质提供了实证基础,推动了领域内对微调泛化理论的深入反思。
当前挑战
该数据集致力于解决推理微调中模型泛化能力不足的核心挑战,具体表现为跨领域性能的非单调‘先降后升’轨迹,以及推理能力提升与安全性下降的不对称泛化现象。在构建层面,挑战主要源于高质量长链思维数据的获取与验证,需确保思维轨迹的正确性与逻辑一致性,以避免低质量解决方案引入误导性信号。同时,数据结构的差异,如有无思维链的对比,要求构建过程精确控制变量,以分离数据形式与内容对泛化效果的具体影响,这为数据集的构建带来了严谨性与复杂性并存的挑战。
常用场景
经典使用场景
在大型语言模型推理能力微调的研究领域,DeepSeek-R1-20k数据集作为高质量长链思维轨迹的典型代表,常被用于探索监督微调过程中的跨领域泛化现象。该数据集包含由DeepSeek-R1模型生成的已验证长链推理步骤,为研究者提供了分析模型如何从特定领域数据中学习可迁移推理模式的关键素材。通过在不同基础模型上进行对比实验,该数据集能够揭示优化动态、数据质量与模型能力之间的复杂交互关系,成为系统性评估推理泛化性能的基准工具。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于微调策略的深入探索与模型能力边界的系统性测绘。相关研究利用数据集对比了不同优化器配置、学习率调度和训练时长对泛化性能的影响,形成了关于“重复曝光优于单次覆盖”等高效训练范式的共识。同时,一系列开源模型检查点的发布催生了关于模型容量与推理模式内化效率的谱系分析,推动了跨模型家族的泛化规律比较研究。这些工作共同构建了一个关于推理微调可复现实验的生态系统,为后续研究提供了坚实的基准和比较基础。
数据集最近研究
最新研究方向
在大型语言模型推理能力微调领域,DeepSeek-R1-20k数据集作为高质量长链思维数据,正推动对跨领域泛化机制的深入探索。前沿研究聚焦于优化动态、数据质量与模型能力之间的复杂交互,揭示了泛化过程中存在的“先降后升”轨迹与不对称现象。这些发现不仅挑战了传统微调范式,也为构建兼具强大推理能力与安全性的模型提供了关键洞见,标志着该领域正从单纯性能提升转向对泛化本质的系统性解构。
以上内容由遇见数据集搜集并总结生成


