rag-hpo-bench
收藏Hugging Face2026-01-19 更新2026-01-20 收录
下载链接:
https://huggingface.co/datasets/matanor/rag-hpo-bench
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含论文《检索增强生成的超参数优化方法分析》的网格搜索结果。这些结果涵盖了162种RAG配置在开发和保留测试集上的每个配置输出和分数,涉及五个RAG问答数据集。数据集内容包括RAG配置的摘要文件以及每个配置在特定数据集和分割上的详细结果文件。探索的超参数包括块大小、块重叠、嵌入模型、Top-k和生成模型。数据集还包含了用于评估的多种指标,如LLMaaJ-AC、Lexical-AC等。
This dataset contains the grid search results from the paper *Analysis of Hyperparameter Optimization Methods for Retrieval-Augmented Generation*. The results cover the outputs and scores of 162 RAG configurations on both the development and held-out test sets across five RAG question-answering datasets. The dataset includes summary files for RAG configurations, as well as detailed result files for each configuration on specific datasets and their splits. The explored hyperparameters include chunk size, chunk overlap, embedding model, Top-k, and generative model. Additionally, the dataset contains various evaluation metrics such as LLMaaJ-AC, Lexical-AC, and others.
创建时间:
2026-01-18
原始信息汇总
RAG‑HPO Bench 数据集概述
数据集基本信息
- 名称:RAG‑HPO Bench
- 描述:该数据集包含论文《An Analysis of Hyper‑Parameter Optimization Methods for Retrieval Augmented Generation》的网格搜索结果,涵盖了162种RAG配置在五个RAG问答数据集上的开发集和测试集输出与分数。
- 论文链接:https://arxiv.org/abs/2505.03452
- 语言:英语
- 数据规模:10K<n<100K
- 许可协议:CC-BY-NC-SA 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0/),其中由Llama模型产生的输出受Llama 2社区许可协议(https://ai.meta.com/llama/license/)约束。
- 版本:v1.0.0 (发布日期:2025年1月18日)
数据集内容
- 主要文件:
rag_configurations_summary.csv:包含每种配置的RAG结果摘要(每行一个配置)。Dataset/Split/RagConfigurationNNN.csv:特定数据集和特定划分下单个RAG配置的结果文件。例如,AIArxiv/Dev/RagConfiguration0.csv包含AIArxiv数据集Dev划分下配置#0的结果。
- 数据集构成:包含5个实验数据集:
AIArxiv、BioASQ、ClapNQ、MiniWiki和WatsonxQA。 - 数据划分:
Dev、Test和Dev-Sampled。
超参数搜索空间
| 超参数 | 取值 |
|---|---|
| Chunk size (tokens) | 256, 384, 512 |
| Chunk overlap (% tokens) | 0%, 25% |
| Embedding model | multilingual-e5-large, bge-large-en-v1.5, granite-embedding-125M-english |
| Top‑k | 3, 5, 10 |
| Generative model | Llama-3.1-8B-Instruct, Mistral-Nemo-Instruct-2407, Granite-3.1-8B-instruct |
总配置数:162 (3 × 2 × 3 × 3 × 3)
实验包含的RAG问答数据集
- AIArxiv:基于机器学习arXiv论文的技术问答。
- BioASQ:生物医学领域问答。
- MiniWiki:维基百科事实型问答。
- ClapNQ:长答案Natural Questions子集。
- WatsonxQA:企业文档问答。
评估指标
LLMaaJ-AC:基于LLM-as-a-Judge的答案正确性(使用RAGAS,以GPT‑4o‑mini为骨干)。Lexical-AC:词汇答案正确性(与标准答案的token召回率)。Context Correctness:检索指标,使用平均倒数排名实现。Lexical-FF:忠实度。
文件结构
RAG配置摘要 (rag_configurations_summary.csv)
每行描述一个RAG配置在特定数据集划分上的结果。
Dataset(string):数据集名称。Split(string):数据划分。Configuration ID(int32):唯一配置ID,范围[0-161]。Chunk Size(int32):块大小。Chunk Overlap(int32):块重叠比例。Embedding Model(string):嵌入模型。Top-K(int32):Top-K值。Generative Mode(string):生成模型。Context Correctness,LLMaaJ-AC,Lexical-AC,Lexical-FF:各指标分数。
单个RAG配置结果文件
question_id(string):问题唯一ID。question(string):基准测试中的问题。answer(string):LLM生成的答案。ground_truths(string):基准测试中的标准答案列表。contexts(string):为问题从索引中检索到的上下文列表。Lexical-AC,Lexical-FF,context_correctness,LLMaaJ-AC(float32):该实例的指标分数。
关键发现(来自论文)
- 探索约10种配置足以在多个数据集和指标上匹配完整网格搜索的性能。
- 模型优先的贪婪优化(按顺序优化参数:生成器 → 嵌入模型 → 分块 → Top‑k)优于管道顺序贪婪变体。
- 在所探索的搜索空间中,生成器选择对性能影响最大。
引用
bibtex @article{orbach2025raghpo, title={An Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation}, author={Orbach, Matan and Eytan, Ohad and Sznajder, Benjamin and Gera, Ariel and Boni, Odellia and Kantor, Yoav and Bloch, Gal and Levy, Omri and Abraham, Hadas and Barzilay, Nitzan and Shnarch, Eyal and Factor, Michael E. and Ofek-Koifman, Shila and Ta-Shma, Paula and Toledo, Assaf}, eprint={2505.03452}, archivePrefix={arXiv}, primaryClass={cs.CL}, year={2025}, url={https://arxiv.org/abs/2505.03452}, }
搜集汇总
数据集介绍
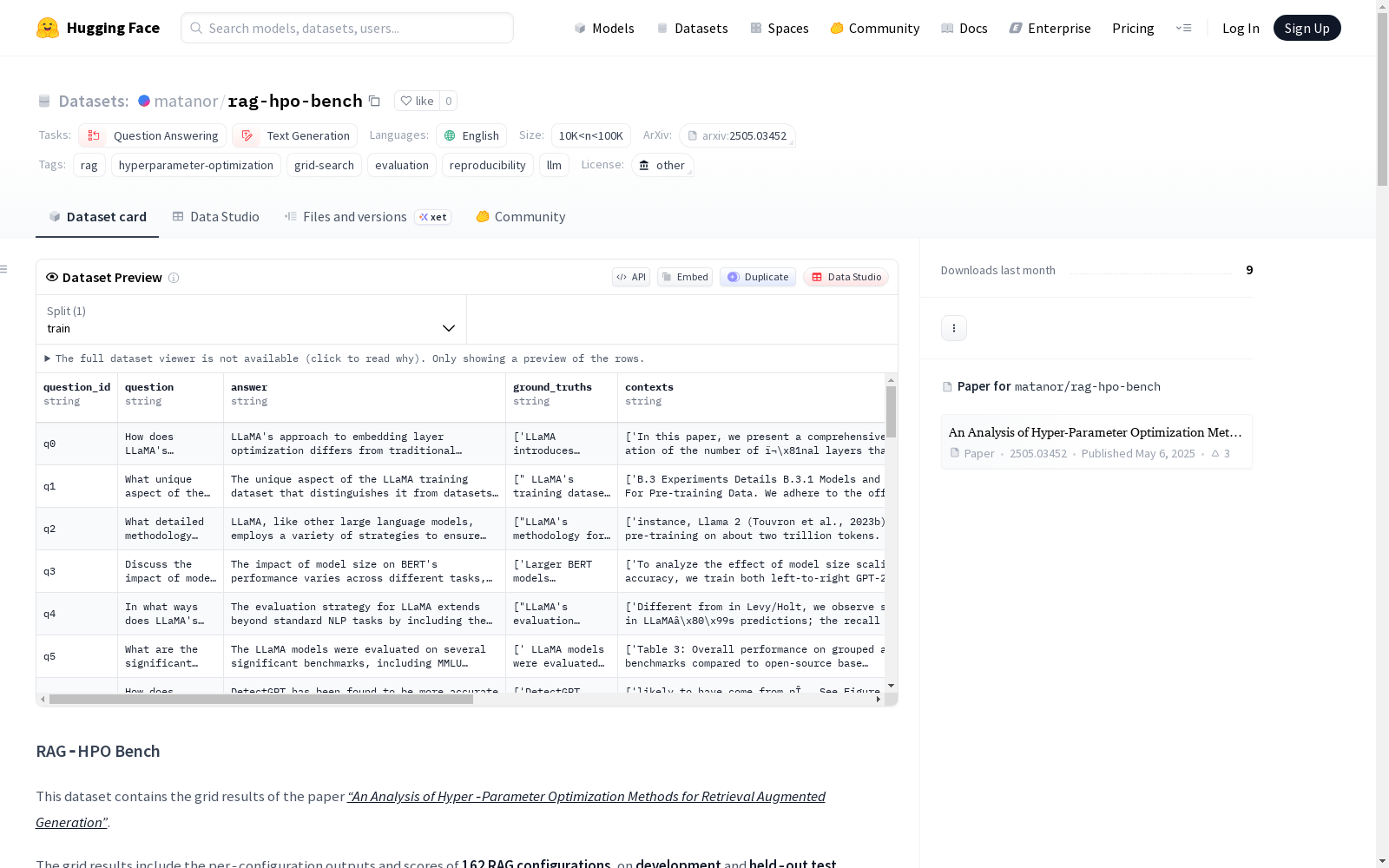
构建方式
在检索增强生成(RAG)系统的超参数优化研究中,RAG-HPO Bench数据集通过系统性的网格搜索方法构建而成。研究团队在五个具有代表性的问答数据集上,对162种不同的RAG配置进行了全面评估,涵盖了块大小、块重叠比例、嵌入模型、检索数量以及生成模型等关键超参数。每个配置均在开发集和测试集上执行,并记录了详细的输出结果与多项评估指标得分,从而形成了一个结构化的性能比较基准。
使用方法
研究人员可利用该数据集进行多种分析,例如通过加载配置摘要与详细结果文件,识别在特定评估指标下各数据集的最优配置。数据集支持对超参数进行边际效应分析,例如探究生成模型选择对整体性能的主导性影响。典型的使用流程包括从开发集中筛选最优配置,进而评估其在独立测试集上的泛化性能,或执行模拟优化过程的收敛性分析,以验证高效超参数调优方法的有效性。
背景与挑战
背景概述
随着检索增强生成(RAG)技术在自然语言处理领域的广泛应用,其性能高度依赖于众多超参数的协同配置,如文本分块策略、嵌入模型选择及生成模型调优等。为系统探索这些参数对RAG系统效果的影响,研究团队于2025年发布了RAG‑HPO Bench数据集。该数据集源自论文《An Analysis of Hyper‑Parameter Optimization Methods for Retrieval Augmented Generation》,由Matan Orbach等学者联合构建,旨在通过网格搜索方法,在五个代表性问答数据集上评估162种不同配置的性能。其核心研究问题聚焦于超参数优化方法在RAG系统中的效率与有效性,为自动化超参数调优提供了实证基础,对提升RAG系统的可复现性与工程实践具有重要参考价值。
当前挑战
RAG‑HPO Bench数据集致力于解决检索增强生成系统中超参数优化的核心挑战,即如何在庞大的参数空间中高效寻址最优配置,以平衡问答准确性、上下文相关性与计算成本。构建过程中,研究团队面临多重困难:首先,需设计合理的参数搜索空间,涵盖分块大小、重叠比例、嵌入模型、检索数量及生成模型等关键维度,同时控制组合爆炸风险;其次,实验涉及多个异构数据集,如AIArxiv、BioASQ等,其领域差异与规模不一要求适配统一的评估框架与采样策略,以确保结果可比性与计算可行性;此外,评估指标需兼顾自动化评判与人工标注的可靠性,例如采用LLM‑as‑a‑Judge方法,其本身亦引入模型偏差与一致性挑战。
常用场景
经典使用场景
在检索增强生成(RAG)系统的开发与评估领域,RAG‑HPO Bench数据集为超参数优化研究提供了标准化的实验基准。该数据集通过系统性地探索162种RAG配置在五个问答数据集上的性能表现,为研究人员提供了详尽的网格搜索结果。经典使用场景包括对比不同超参数组合对RAG系统答案正确性、上下文准确性和忠实度等指标的影响,从而揭示各参数间的交互效应与最优配置规律。
解决学术问题
该数据集有效解决了RAG系统超参数优化中缺乏标准化评估框架的学术难题。通过提供跨多个领域数据集的系统化实验结果,它使研究者能够定量分析块大小、重叠率、嵌入模型、检索数量与生成模型等关键参数对系统性能的边际贡献。其意义在于建立了可复现的比较基准,为理解超参数优化方法的收敛特性与效率边界提供了实证基础,推动了RAG系统设计从经验驱动向数据驱动的范式转变。
实际应用
在实际应用中,RAG‑HPO Bench为构建高效RAG系统提供了直接的配置参考。企业可依据该数据集揭示的规律,在知识库问答、技术文档检索和生物医学信息提取等场景中快速确定近似最优参数组合。例如,在有限计算资源下,遵循数据集验证的模型优先贪婪优化策略,能显著缩短系统调优周期。同时,其跨领域性能对比有助于针对特定垂直领域定制化选择嵌入模型与生成器,提升实际部署系统的准确性与稳定性。
数据集最近研究
最新研究方向
在检索增强生成(RAG)系统的优化领域,RAG‑HPO Bench数据集为超参数调优提供了系统性的实证基准。该数据集通过网格搜索方法,全面评估了分块策略、嵌入模型、检索数量及生成模型等关键超参数对五个问答数据集性能的影响。前沿研究聚焦于高效超参数优化方法的探索,例如模型优先贪婪策略,其能在仅评估约10种配置的情况下逼近网格搜索的最优性能,显著降低了计算成本。生成模型的选择被证实对整体效果具有主导性影响,这一发现推动了针对模型适配性的轻量级调优框架的发展。该数据集促进了RAG系统在可复现性、评估标准化及自动化调优方面的进步,为构建更稳健、高效的问答系统奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


